ETL, ELT, and Reverse ETL
What are the advantages of ETL? Is ETL preferable to ELT for your data pipeline use cases? Why and when is reverse ETL valuable for your data warehouse (DW)?
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Data Pipelines Trend Report.
For more:
Read the Report
ETL (extract, transform, load) has been a standard approach to data integration for many years. But the rise of cloud computing and the need to integrate self-service data has led to the development of new methodologies such as ELT (extract, load, transform) and reverse ETL.
What are the advantages of ETL? How do these three data integration approaches differ? Is ETL preferable to ELT for your data pipeline use cases? Why and when is reverse ETL valuable for your data warehouse (DW) and a data lake? Why is reverse ETL not an optional choice for data pipeline ETL or ELT, but rather another process opportunity for a DW and data lake?
To help you choose the data integration method for your data pipeline projects, we briefly explore ETL and ELT — their strengths and weaknesses and how to exploit both technologies. We describe why ETL is an exceptional choice if you need to transform to support business logic, granular compliance on data in flight, and in the case of ETL streaming, low latency. We also explore how ELT is a better option for those who need fast data loading, minimized maintenance, and highly automated workflows.
General Concepts of ETL and ELT
A common challenge for organizations is capturing data from multiple sources in multiple formats and then moving it to one or more data targets. It is possible that the target is not the same kind of data storage as the source. If the format is different, the data must be refined or cleaned before being loaded into the final target. Many tools, services, and processes have been developed to help address these challenges. Regardless of the process used, there is a shared need to coordinate work and apply data transformations in the data pipeline.
Most data movement projects gather multiple sources of data. They need a well-defined data pipeline (i.e., ELT/ELT). But what is a data pipeline? It’s the path (or workflow) that the information goes through from the origin to the end.
The ETL Process
ETL is a data integration process that enables data pipeline projects to extract data from various sources, transform the data, and load the resulting data into a target database. Regardless of whether it's ETL or ELT, the data transformation/integration process involves the following three phases (Figure 1):
- Extraction – Data is extracted from source systems (e.g., SAS, online, local) using database queries or change data capture (CDC) processes. Following extraction, the data is moved into staging areas for further processing.
- Transformation – Data is cleaned, processed, transformed, enriched, etc., then converted to a required format to be consumed by a target data pipeline, data warehouse, database, or data lake.
- Loading – The original and converted data are loaded into the target system. This process may involve writing to a delimited file, creating schemas in a database, or overwriting existing data with cumulative or aggregated data.
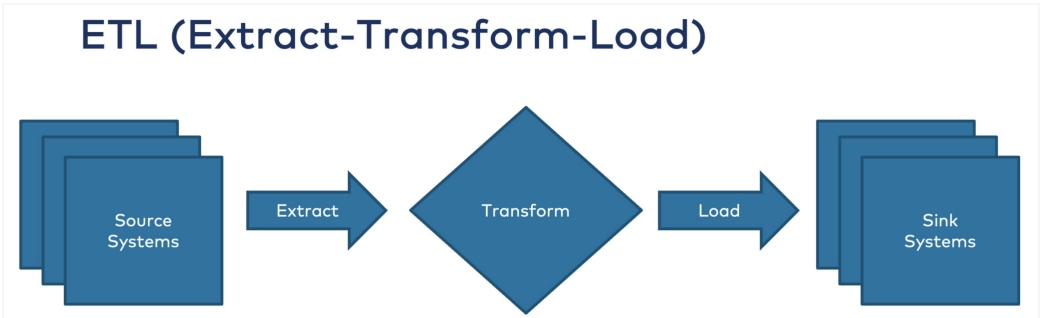
Figure 1: The ETL process ("When to Use Reverse ETL and When It Is an Anti-Pattern," Kai Waehner)
ETL and ELT processes perform these steps in a different order. The data pipeline team must decide whether to transform data before or after loading it into the target data repository.
The ELT Process
ELT is a method for integrating data from across an organization to prevent data silos. The data is extracted from its source(s), loaded into a data warehouse, and then transformed on-demand later. Transformations are typically applied on an as-needed basis, whereas in an ETL process, data is transformed before being stored (Figure 2).
- Extraction – Same as ETL.
- Loading – Unlike ETL, data is delivered directly (i.e., without cleaning, enrichment, transformations) to the target system — typically with the target schema and data type migrations factored into the process.
- Transformation – The target platform where data was loaded can be transformed for business reporting purposes. Some companies utilize tools like dbt to transform their target data. Therefore, in the ELT pipeline, transformations are performed on the target data as needed.
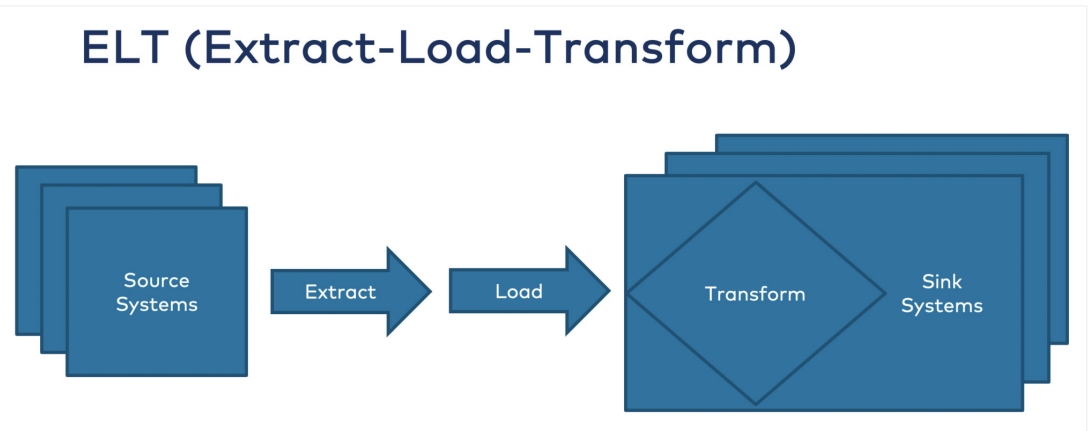
Figure 2: The ELT process ("When to Use Reverse ETL and When It Is an Anti-Pattern," Kai Waehner)
ELT reorders the steps involved in the integration process, with transformations occurring at the end instead of in the middle. ELT processes can switch the order of phases to load the data into a data lake (for example) that accepts raw data, no matter its structure or format. This allows for instant data extraction and loading.
A further factor contributing to the adoption of ELT is the widespread implementation of cloud-based data warehouses. Most cloud-hosted DWs are now managed, which means enterprises don't need to purchase or manage any hardware or storage, install software, or think about scaling — the cloud provider tool manages everything. For instance, a cloud-hosted DW can be provisioned in a short period of time. Cloud data warehouse solutions offer complete separation between computing and storage and the ability to store unlimited data.
ETL vs. ELT: Attributes, Functions, and Use Cases
There is no clear front-runner in the ETL vs. ELT use case discussion. The table below outlines their distinguishing attributes:
| Attributes | ETL | ELT |
|---|---|---|
| Best for… | Structured data, legacy systems, and relational DBs; transforming data before loading to DW | Quicker, timely data loads, structured and unstructured data, and large and growing data; transforming data as needed |
| Support for unstructured data | Used chiefly for on-premises relational data | Support for unstructured data is readily available |
| Support for data lakes | Does not support data lakes | Supports data lakes |
| Lookups | Fact data, as well as dimensions, must be available for the staging area | All data is available because extracts and loads occur in one single action |
| Time to load | Data is initially loaded into staging, then the target system | Data is loaded into a target system once |
| Data output | Often used for on-premises data that should be structured before uploading to a relational DW | Structured, semi-structured, and unstructured data; best suited for large data volumes to be implemented in cloud environments that offer large storage and computing power, enabling the data lake to store and transform data quickly as needed |
| Performance of data loads | Data load time is longer than its alternative since it's a multi-stage process | Data loading happens faster since there's no wait time for transformations, and the data is only loaded once into the target database |
| Performance of transformations | Data transformations can be slow | Data transformations complete faster since they are done after load and on an as-needed basis |
| Aggregations | Complexity increases with a greater amount and variety of data | The power of the target platform can process a significant amount of data quickly |
| Data deployment | On-premises or cloud-based | Often cloud-based |
| Analysis flexibility | Use cases and report models are well defined | Data may be added at any time as the schemas evolve; analysts can build new views of the target warehouse |
| Compliance | Better suited for compliance with GDPR, HIPAA, and CCPA standards; users can omit sensitive data before loading it into the target system | Carries more risk of exposing private data and not complying with GDPR, HIPAA, and CCPA standards |
| Implementation | Easier to implement given the wide variety of tools and support skills | Requires niche skills to implement and maintain |
General Concepts of Reverse ETL
Reverse ETL is an architecture for extracting cleaned and processed data, which involves copying data from a data warehouse (or data lake/mart) to one or more operational systems. Data can be ingested back into other applications, such as Salesforce, which can be used for business operations and forecasting. Operationalizing extracted data sources enables all users to access the data and insights needed for tools they frequently use. As a modern data technology stack component, reverse ETL allows companies to conduct more complex analyses than they could with business intelligence (BI) tools alone.
Reverse ETLs have become a strategic new integration process in the modern data stack to reduce the time between analytics and data that’s needed in fast-moving enterprises. Reverse ETL processes focus on activating the data within the data warehouse by syncing it back into the operational tools of business users. Users must define the data and map it to the appropriate columns/fields in the end destination.
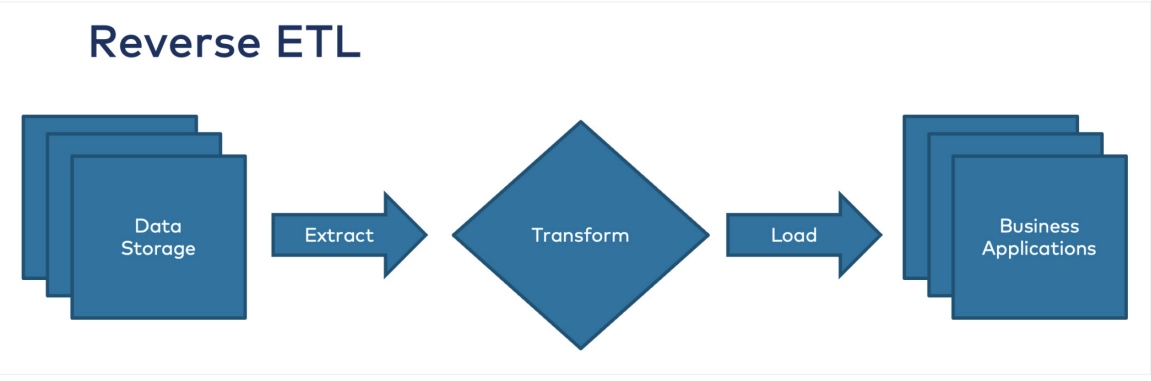
Figure 3: The reverse ETL process ("When to Use Reverse ETL and When It Is an Anti-Pattern," Kai Waehner)
Reverse ETL may be required because your data store (e.g., DW, relational DB) has become a repository that is not fully accessible to everyone who needs the data. Without a reverse ETL on your data warehouse, much of the basic data your business needs is only in the DW (Figure 3).
Reverse ETL Use Cases
Instead of seeing the data warehouse as the end component in a data pipeline, reverse ETL users can leverage the already cleaned and prepared information available from their DW. They can do so by using connectors to read the data warehouse (e.g., SAP, SASS). The objective is to make the DW data actionable by operational systems.
Data lake teams are embracing a new set of advanced engineering analytics skills. They should be freed and allowed to use those skills and data using their modern analytic tools. With reverse ETL solutions available, modern data teams can extract data from data warehouses to power email marketing, customer support, sales, or financial models. This means that more successful business teams can make self-service deep, valuable, and more efficient.
What can you accomplish with reverse ETL? Among other things:
- Business analysis - Quickly track and react to changes in business applications and data.
- Business analytics – Deliver insights to business teams for their analytical workflows, so that they can make more data-informed decisions.
- Data infrastructure – With an increasing number of source systems, reverse ETL is now an essential tool to quickly and efficiently operationalize data in DWs and data lakes.
- Replicating data for modern cloud applications – To enhance reporting capabilities and find timely information.
Buy vs. Build Reverse ETL
When data teams adopt third-party reverse ETL tools, they can implement operational analytics quickly, but whether to buy or build might be difficult to determine.
Three factors should be considered before deciding to build a reverse ETL process and platform:
- Build data connectors – Transferring data from your warehouse to downstream operational systems requires the complicated work of integrating API connectors. If you choose to design and build the reverse ETL and associated process, you will most likely allocate the ETL pipeline construction process to a team of developers.
- Prepare for long-term maintenance – Once your development team rolls out data connectors, the work doesn't end there. Since API specifications often change, keeping connectors up to date becomes an additional burden.
- Design in extendibility and reliability – Data engineers need to ensure that reverse ETL pipelines can evolve rapidly to manage data surges effortlessly as your enterprise grows. Reverse ETL pipelines must be exceedingly reliable, leaving no room for performance or data delivery issues.
Conclusions
The most burdensome and time-consuming step in creating a data pipeline is extracting data from various sources and then testing the entire process. Each source needs its synchronization, and you can have many sources for data collection. This can rapidly become a huge lift for a technical team. Ultimately, data integrations can become very complicated as they require significant expertise at all levels of the process. However, the time and effort needed to learn more about the options, variations, and products available for the job are always worthwhile.
References:
- Gartner Research (2021), "Gartner Magic Quadrant for Data Integration Tools"
- Gartner Research (2020), "Critical Capabilities for Data Integration Tools"
- Kai Waehner, "When to Use Reverse ETL and When It Is an Anti-Pattern"
- Stephen Roddewig, "ETL vs. ELT: What's the Difference & Which Is Better?"
This is an article from DZone's 2022 Data Pipelines Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments