Flink State Management and Fault Tolerance for Real-Time Computing
We look at the processing of stateful streaming data, state interfaces, and the implementation of state management and fault tolerance in Apache Flink.
Join the DZone community and get the full member experience.
Join For FreeThis article summarizes the presentation shared by Shi Xiaogang on the Flink Meetup in Beijing on August 11, 2018. Shi Xiaogang is currently engaged in Blink R&D in the Alibaba Big Data team and is responsible for the R&D of Blink state management and fault tolerance. Alibaba Blink is a real-time computing framework built based on Apache's Flink, aimed at simplifying the complexity of real-time computing on Alibaba's ecosystem.
In this article, we will cover the following content:
- Processing of stateful streaming data.
- State interfaces in Flink.
- Implementation of state management and fault tolerance.
- Alibaba contribution to Flink.
Processing of Stateful Streaming Data
What Is Stateful Computing?
The result of a computing task relies not only on the input objects, but also on the current state of the data. In fact, most computing tasks involve stateful data. For example, WordCount is a variable used to calculate the count of words. The word count is an output that accumulates new input objects into the existing word count. In this case, the word count is a stateful variable.
Issues With Traditional Stream Computing
Traditional stream computing systems lack efficient support for program states such as:
- Storage and access of the state data.
- Backup and recovery of the state data.
- Partitioning of state data and dynamic resizing.

In traditional batch processing, data is partitioned, and each task processes a partition. When all partitions are executed, the outputs are aggregated as the final result. In this process, the state is not demanding.
However, stream computing has high requirements for the state because an unlimited stream is imported to the stream system, which runs for a long time, say, a couple of days or even several months, without interruption. In this case, the state data must be properly managed. Unfortunately, the traditional stream computing system does not completely support the state management. For example, Storm does not support any program state. A solution is to use Storm with HBase. The state data is stored in HBase, Storm reads the state data for calculation, and then writes the updated data into HBase again. The following problems may occur:
- If Storm tasks and HBase data are stored on different servers, the performance is poor. The server running Storm tasks has to frequently access the peer server that runs HBase over networks and storage media.
- Backup and recovery are hard because HBase does not support rollback and it is difficult to achieve the exactly-once consistency. In a distributed environment, Storm must be restarted if the program fails. In this case, the HBase data cannot be rolled back to the previous state. For example, using Storm with HBase is not applicable in the advertising billing because the cost may be doubled. Another solution is using Storm with MySQL, which ensures data consistency because MySQL supports rollback. However, the architecture becomes complex and the performance is poor. The COMMIT statement is required to ensure data consistency.
- State data partitioning and dynamic resizing are difficult for Storm. A serious problem is that all users have to repeat the same tasks on Storm, for example, search and advertising services, which constraints business development.
Benefits of Flink
Flink provides rich interfaces for accessing state and efficient fault tolerance. Flink has been designed to provide rich APIs for state access and efficient fault tolerance, as shown in the following figure:

State Management of Flink
Flink has two types of states based on data partitioning and resizing modes: Keyed States and Operator States.
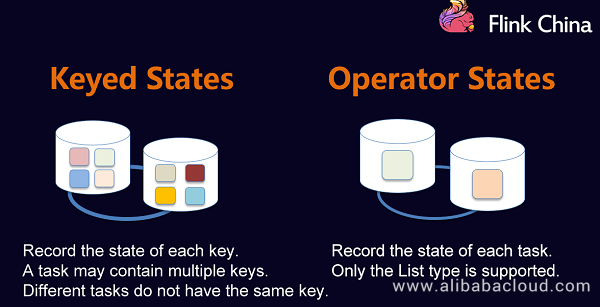
Keyed States
Use of Keyed States:

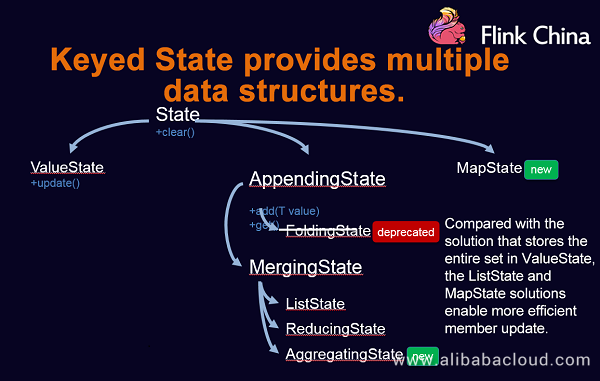
Flink also provides multiple data structure types in Keyed States.
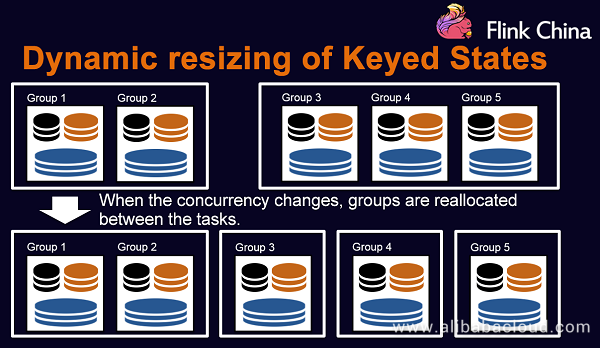
Dynamic resizing of Keyed States:
Operator State
Use of Operator States:

Operator States do not support as many data structures as Keyed States. They only support List currently.
Multiple resizing modes of Operator States:
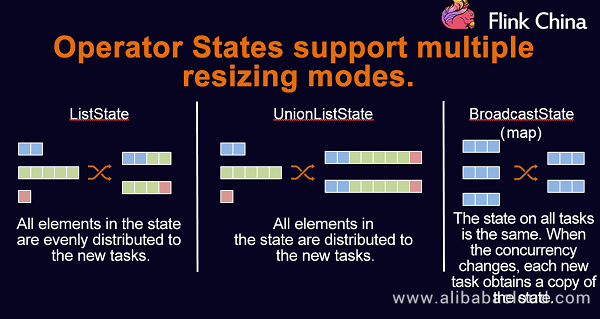
Operator States support dynamic and flexible resizing. The following describes three resizing methods that Operator States support:
- ListState: When the parallelism is changed, the lists in the parallel instances are extracted and merged into a new list. The elements in the new list are evenly redistributed to the new task.
- UnionListState: It is more flexible compared with ListState. You can determine the partitioning method. When the concurrency changes, the original lists are joined. The joined lists are not partitioned and are directly sent to you.
- BroadcastState: When a large table and a small table are joined, the small table can be directly broadcast to the partitions of the large table. The data on each concurrent task is completely the same. The update is the same. When the concurrency changes, the data is copied to the new tasks.
The preceding are the three resizing methods supported by Flink Operator States. You can select any of them as required.
Use Checkpointing to Improve Program Reliability
You can enable checkpointing for your program. Flink backs up the program state at a certain interval. In case of a failure, Flink recovers all tasks to the state of the last checkpoint and restarts running the tasks from that checkpoint.
Flink supports two modes to guarantee consistency: at least once and exactly once.

Back Up Program State Data Not Stored in the State
Flink also provides a mechanism that allows the state to be stored in the memory. Flink restores the state during the checkpoint operation.

Resume From Stopped Jobs
The running jobs must be stopped before a component is upgraded. After the component upgrade is completed, the jobs must be resumed. Flink provides two modes to resume the jobs:
- Savepoint: It is a special checkpoint. Unlike the checkpoint that is periodically triggered by the system, the savepoint is triggered by running commands. The storage format of the savepoint is also different from that of the checkpoint, and the data is stored in the standard format. Regardless of the configuration, Flink resumes the state from the checkpoint. The savepoint is a good tool for version upgrade.
- External checkpoint: It is an extension of the existing checkpoint. After an internal checkpoint operation is completed, the checkpoint data is also stored in the specified directory.

Implementation of State Management and Fault Tolerance
The following lists three StateBackends provided by Flink for state management and fault tolerance:
- MemoryStateBackend
- FsStateBackend
- RockDBStateBackend
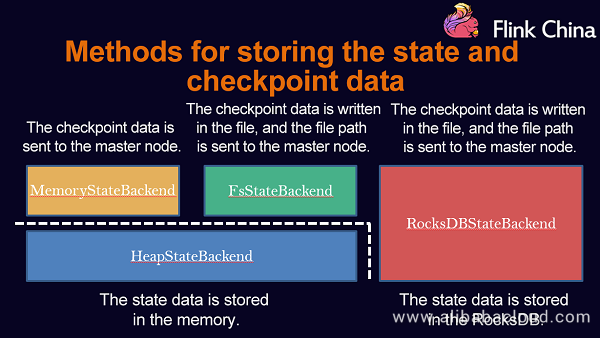
You can select any of the modes as required. You can store a small amount of data in MemoryStateBackend or FsStateBackend and store a large amount of data in RocksDBStateBackend.
The following describes HeapKeyedStateBackend and RocksDBKeyedStateBackend:
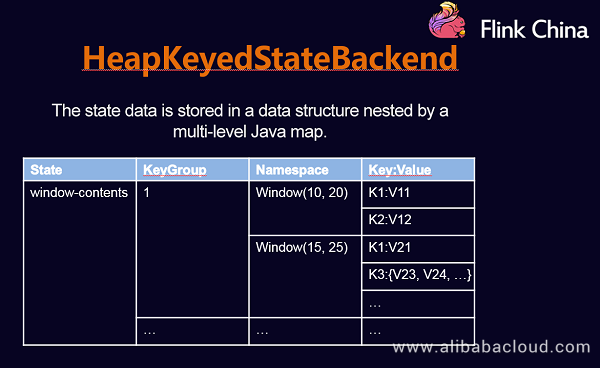
HeapKeyedStateBackend
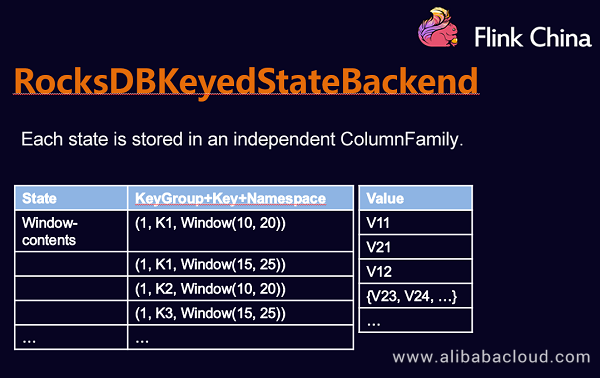
RocksDBKeyedStateBackend
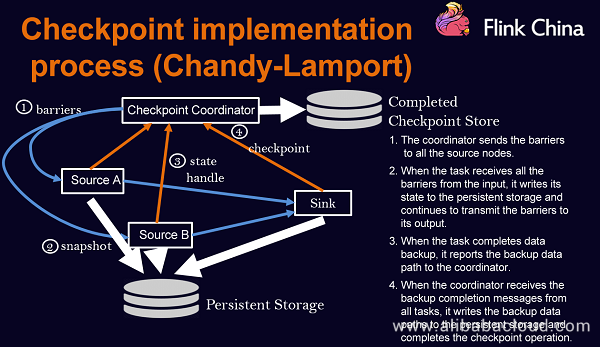
Checkpoint Implementation Process
The checkpoint operation is implemented based on the Chandy-Lamport algorithm.
Alignment of Checkpoint Barriers

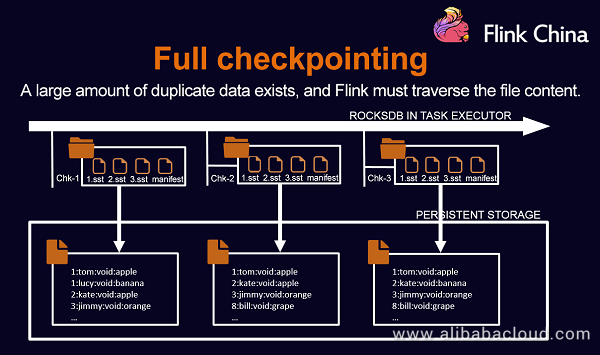
Full Checkpointing
When backing up data of each node, Flink traverses and writes all the data to external storage, which affects the backup performance. Full checkpointing has been optimized to improve the performance.
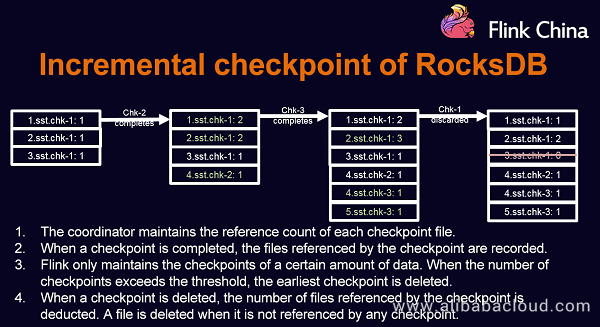
Incremental Checkpoint of RocksDB
RocksDB data is updated to the memory and is written to the disk when the memory is full. By using the incremental checkpoint mechanism, the newly generated files are copied to the persistent storage, while the previously generated files do not need to be copied to the persistent storage. In this way, the amount of data to be copied is reduced, thus improving the performance.
Flink and Alibaba
Alibaba has supported the Flink research since 2015. In October 2015, it started the Blink project and optimized and improved Flink in large-scale production environments. In the Double 11 Shopping Festival in 2016, Alibaba used the Blink system to provide services for search, recommendation, and advertising. In May 2017, Blink became Alibaba's real-time computing engine.

Published at DZone with permission of Leona Zhang. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments