From Zero to Scale With AWS Serverless
Serverless scales effortlessly from zero to peak, with AWS tools like DynamoDB and Lambda enabling cost-efficient, auto-scaling apps for data and real-time workflows.
Join the DZone community and get the full member experience.
Join For FreeIn recent years, cloud-native applications have become the go-to standard for many businesses to build scalable applications. Among the many advancements in cloud technologies, serverless architectures stand out as a transformative approach. Ease-of-use and efficiency are the two most desirable properties for modern application development, and serverless architectures offer these. This has made serverless the game changer for both the cloud providers and the consumers.
For companies that are looking to build applications with this approach, major cloud providers offer several serverless solutions. In this article, we will explore the features, benefits, and challenges of this architecture, along with use cases. In this article, I used AWS as an example to explore the concepts, but the same concepts are applicable across all major cloud providers.
Serverless
Serverless does not mean there are no servers. It simply means that the underlying infrastructure for those services is managed by the cloud providers. This allows the architects and developers to design and build the applications without worrying about managing the infrastructure. It is similar to using the ride-sharing app Uber: when you need a ride, you don’t worry about owning or maintaining a car. Uber handles all that, and you just focus on getting where you need to go by paying for the ride.
Serverless architectures offer many benefits that make them suitable and attractive for many use cases. Here are some of the key advantages:
Auto Scaling
One of the biggest advantages of serverless architecture is that it inherently supports scaling. Cloud providers handle the heavy lifting to offer near-infinite, out-of-the-box scalability. For instance, if an app built using Serverless technologies suddenly gains popularity, the tools or services automatically scale to meet the app’s needs. We don’t have to wake up in the middle of the night to add the servers or other resources.
Focus on Innovation
Since you are no longer burdened with managing servers, you can instead focus on building the application, adding features towards app’s growth. For any organization, whether small, medium, or large, this approach helps in concentrating on what truly matters — business growth.
Cost Efficiency
With traditional server models, you often end up paying for unused resources as they are bought upfront and managed even when they are not in use. Serverless changes this by switching to a pay-as-you-use model. In most of the scenarios, you only pay for the resources that you actually use. If the app you build doesn’t get traction right away, your costs will be minimal, like paying for a single session instead of an entire year. As the app’s traffic grows, the cost will grow accordingly.
Faster Time-to-Market
With serverless frameworks, you can build and deploy applications much faster compared to traditional server models. When the app is ready, it can be deployed with minimal effort using serverless resources. Instead of spending time on server management, you can focus on development and adding new features, shipping them at a faster pace.
Reduced Operational Maintenance
Since cloud providers manage the infrastructure, the consumers need not worry about provisioning, maintaining, scaling, or handling security patches and vulnerabilities.
Serverless frameworks offer flexibility and can be applied to a variety of use cases. Whether it is building web applications or processing real-time data, they provide the scalability and efficiency needed for these use cases.
Building Web Service APIs With AWS Serverless
Now that we have discussed the benefits of serverless architectures, let us dive into some practical examples. In this section, we will create a simple backend web application using AWS serverless resources.
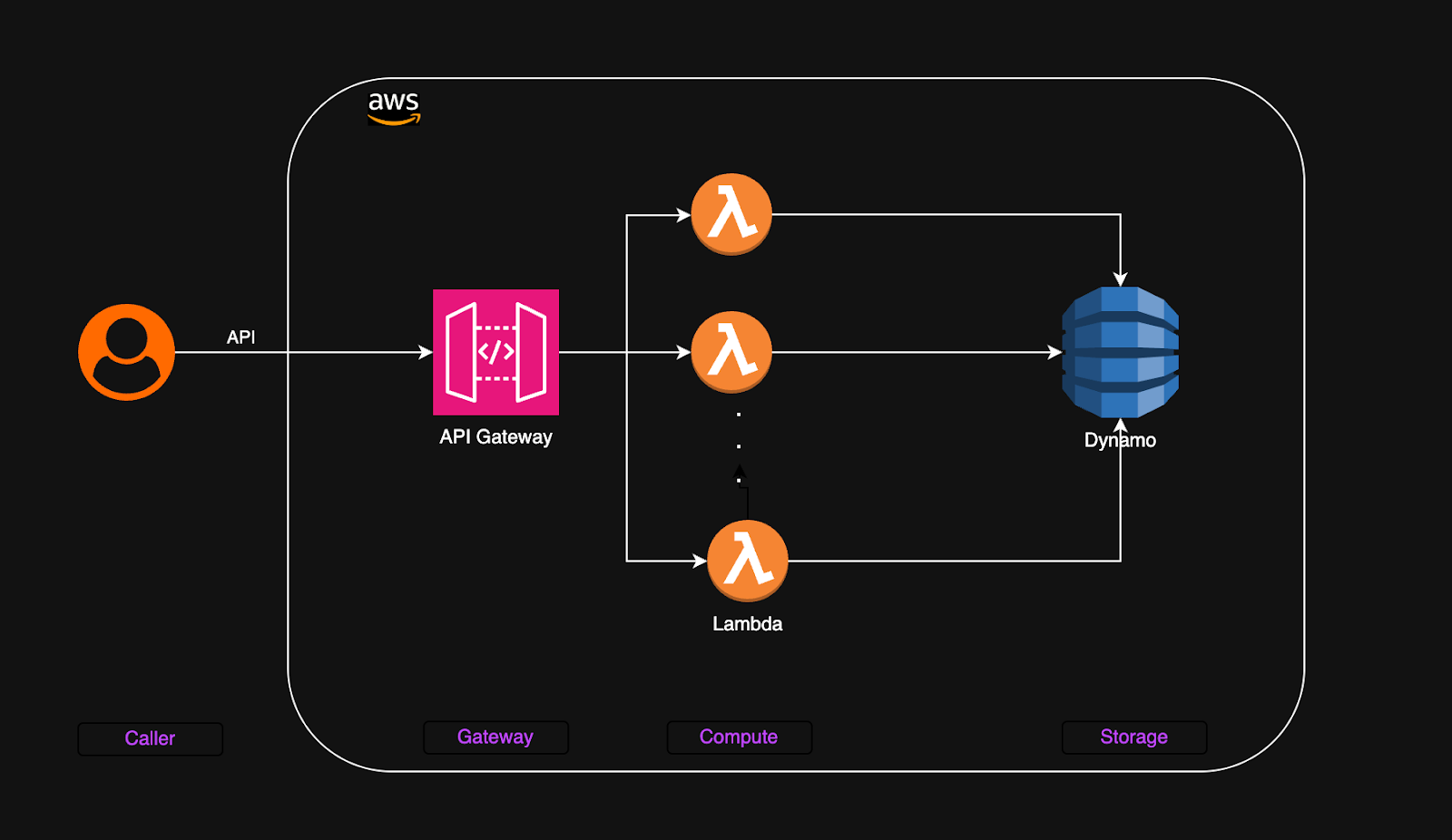
The above backend application design contains three layers to provide APIs for a web application. Once deployed on AWS, the gateway endpoint is available for API consumption. When the APIs are called by the users, the requests are routed through the API gateway to appropriate lambda functions. For each API request, Lambda function gets triggered, and it accesses the DynamoDB to store and retrieve data. This design is a streamlined, cost-effective solution that scales automatically as demand grows, making it an ideal choice for building APIs with minimal overhead. The components in this design integrate well with each other providing flexibility.
There are two major components in this architecture — computing and storage.
Serverless Computing
Serverless computing changed the way cloud-native applications and services are built and deployed. It promises a real pay-as-you-go model with millisecond-level granularity without wasting any resources. Due to its simplicity and economic advantages, this approach gained popularity, and many cloud providers support these capabilities.
The simplest way to use serverless computing is by providing code to be executed by the platform on demand. This approach led to the rise of Function-as-a-service (FaaS) platforms focused on allowing small pieces of code represented as functions to run for a limited amount of time. The functions are triggered by events like HTTP requests, storage changes, messages, or notifications. As these functions are invoked and stopped when the code execution is complete, they don’t keep any persistent state. To maintain the state or persist the data, they use services like DynamoDB which provide durable storage capabilities.
AWS Lambda is capable of scaling as per the demand. For example, AWS Lambda processed more than 1.3 trillion invocations on Prime Day 2024. Such capabilities are crucial in handling the sudden spurts of traffic.
Serverless Storage
In the serverless computing ecosystem, serverless storage refers to cloud-based storage solutions that scale automatically without having the consumers manage the infrastructure. These services offer many capabilities, including on-demand scalability, high availability, and pay-as-you-go. For instance, DynamoDB is a fully managed, serverless NoSQL database designed to handle key-value and document data models. It is purpose-built for applications requiring consistent performance at any scale, offering single-digit millisecond latency. It also provides seamless integration capabilities with many other services.
Major cloud providers offer numerous serverless storage options for specific needs, such as S3, ElastiCache, Aurora, and many more.
Other Use Cases
In the previous section, we discussed how to leverage serverless architecture to build backend APIs for a web application. There are several other use cases that can benefit from serverless architecture. A few of those use cases include:
Data Processing
Let’s explore another example of how serverless architecture can be used to notify services based on data changes in a datastore. For instance, in an e-commerce platform, let’s say on the creation of an order, several services need to be informed. Within the AWS ecosystem, the order can be stored in DynamoDB upon creation. In order to notify other services, multiple events can be triggered based on this storage event.
Using DynamoDB Streams, a Lambda function can be invoked when this event occurs. This lambda function can then push the change event to SNS (Simple Notification Service). SNS acts as the notification service to notify several other services that are interested in these events.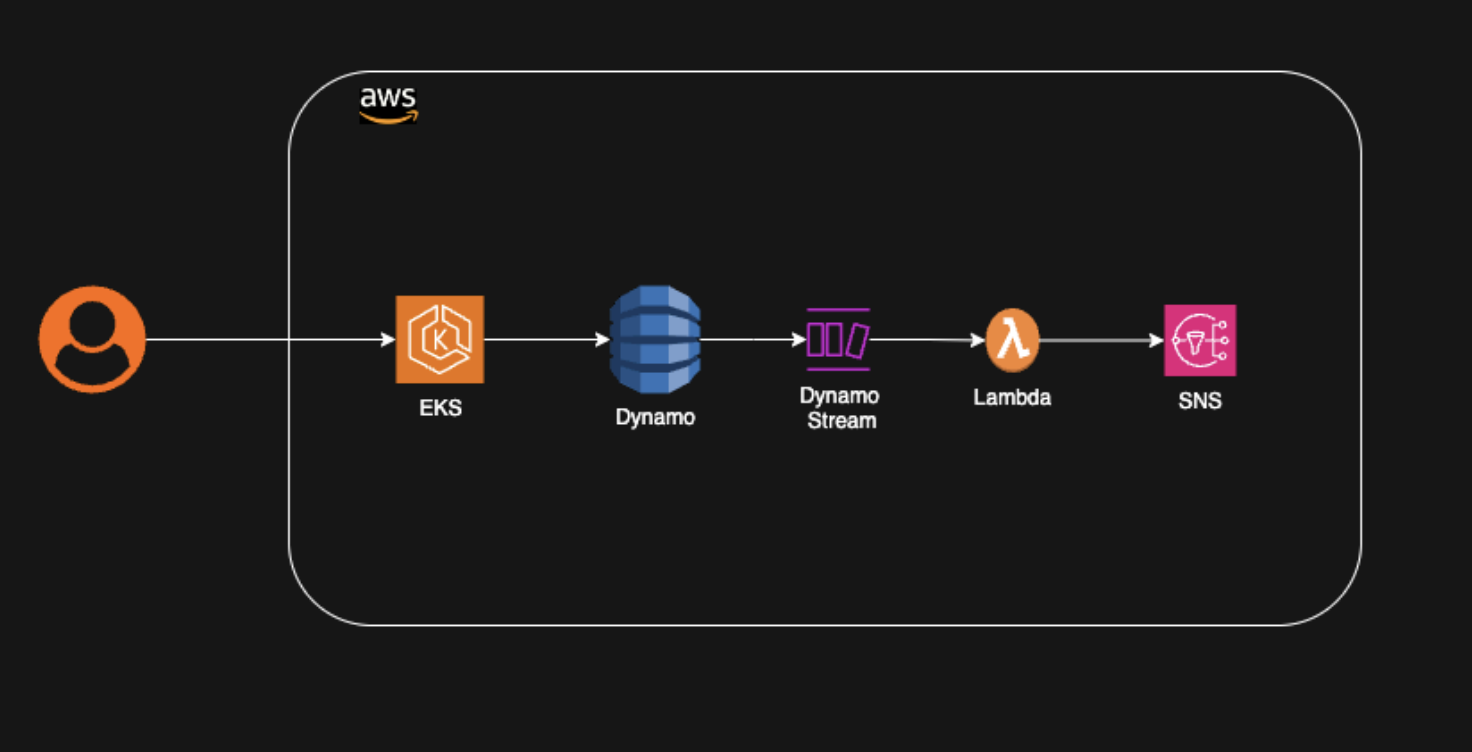
Real-Time File Processing
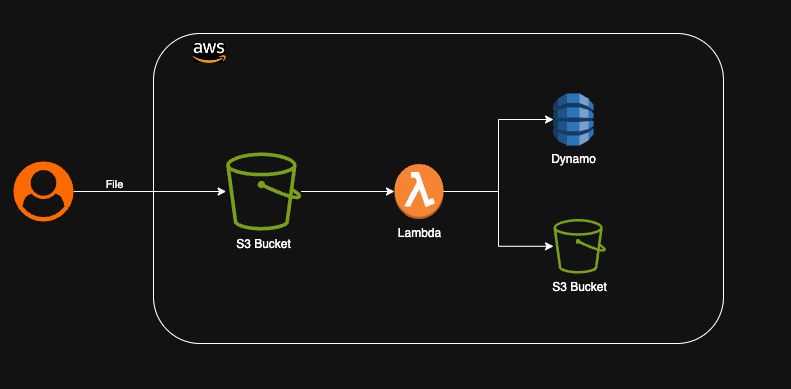
In many applications, users upload images that need to be stored, processed for resizing, converted to different formats, and analyzed. We can achieve this functionality using AWS serverless architecture in the following way. When an image is uploaded, it is pushed to an S3 bucket configured to trigger an event to invoke a Lambda function. The Lambda function can process the image, store metadata in DynamoDB, and store resized images in another S3 bucket. This scalable architecture can be used to process millions of images without requiring to manage any infrastructure or any manual intervention.
Challenges
Serverless architectures offer many benefits, but they also bring certain challenges that need to be addressed.
Cold Start
When a serverless function is invoked, the platform needs to create, initialize, and run a new container to execute the code. This process, known as cold start, can introduce additional latency in the workflow. Techniques like keeping functions warm or using provisioned concurrency can help reduce this delay.
Monitoring and Debugging
As there can be a large number of invocations, monitoring and debugging can become complex. It can be challenging to identify and debug issues in applications that are heavily used. Configuring tools like AWS Cloudwatch for metrics, logs, and alerts is highly recommended to address these issues.
Although serverless architectures scale automatically, the resource configurations must be optimized to prevent bottlenecks. Proper resource allocation and implementation of cost optimization strategies are essential.
Conclusion
The serverless architecture is a major step towards the development of cloud-native applications backed by serverless computing and storage. It is heavily used in many types of applications, including event-driven workflows, data processing, file processing, and big data analytics. Due to its scalability, agility, and high availability, serverless architecture has become a reliable choice for businesses of all sizes.
Opinions expressed by DZone contributors are their own.
Comments