Getting Started With the Retry Pattern
Understanding retry pattern and use cases with sample python code
Join the DZone community and get the full member experience.
Join For FreeFailures are a given and everything will eventually fail over time - Werner Vogels, allthingsdistributed.com
In distributed systems, where making calls to services over the network is necessary for functioning of the system, teams must expect and code to handle failure scenarios. The network here can be traditional remote calls across data centers, within a rack cluster over some form of SDN, etc. An external service here can be anyone of DB, 3rd party integration server, S3, API Server, Web server or even a microservice running in a Kubernetes cluster. Let us not assume that since we have deployed services in a K8 cluster, it is always up and running.
Retry is one such simple and effective pattern in such situations. You retry few times hoping to get a response, with a fixed, random or exponential wait period in between each attempt and eventually give up to try in the next poll cycle. A fine example is AWS Kinesis Libraries for both Producer and Consumer, which has an inbuilt retry logic when writing or reading data with Kinesis. Most of the AWS SDK has an implementation for retry due to the fact that every service has a throttle to limit the rate of interaction.
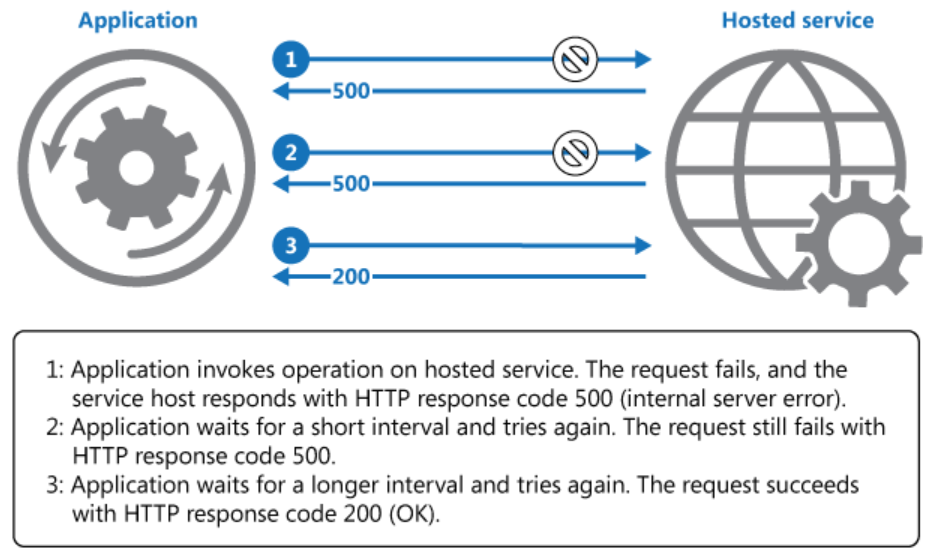
I would like to mention, a subtle difference with "Circuit Breaker" pattern, which is actually one level up. It has an implicit Retry but also prevents further communication until the remote service is available and responds with a test call. This strategy is recommended when you expect services to be unavailable for a longer duration whereas "Retry" is recommended for transient failures (short duration or temporary failures).
Let us understand this difference with an example. Assume an API call is executed every 5 minutes (through cron jobs, language-specific polling threads, or some other orchestration tool). With a retry=3 times, in an event of failure, we are making 36 calls per hour (or 864 calls per day). Clearly, a better design (e.g. Circuit Breaker) is required, if the external service is unavailable for a longer duration.
However, when dealing with cloud services (e.g. AWS DynamoDB, API Gateway) which have an in-built throttling (when request rate > limit), it is recommended to use the Retry pattern with exponential back-off, since after few minutes it will get resolved. In this case, if the service is still not serving request within an hour or two, then a critical alert must be raised & AWS CloudTrail logs must be checked to see from where such high requests are being generated.
Let's try to understand further with the following example using decorator API and leveraging 2 easy to use python packages.
(1) retrying - It has 1600+ GitHub stars and 137 forks. By default, it absorbs all exceptions during retries but a specific exception can be passed. Supports both exponential as well as random back-off, however, the developer has to explicitly use logging to keep track of retry count for further analysis.

(2) retry - It has 344 GitHub stars and 56 forks. A cool feature is to allow passing a logger object that helps the developer in log analysis and alert on retry behavior.

To have an effective Retry pattern implementation, I recommend monitoring a few additional metrics to understand system behavior, such as:
Published at DZone with permission of Preetdeep Kumar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments