GitOps-Backed Agentic Operator for Kubernetes: Safe Auto-Remediation With LLMs and Policy Guardrails
Create an AI-driven Kubernetes Operator that analyzes failures, generates fixes with LLMs, validates them with OPA, and applies changes safely via GitOps.
Join the DZone community and get the full member experience.
Join For FreeKubernetes is already the master of reconciliation: if a pod dies, the scheduler restarts it; if a node disappears, workloads reschedule. But what happens when the failure is due to misconfiguration, resource limits, or novel runtime errors? Traditional controllers keep retrying without real problem-solving.
This is where Agentic AI Operators step in. Instead of blindly retrying, they analyze logs, propose a fix, run it through policies, and deliver it safely via GitOps.
In this article, we’ll build a prototype GitOps-backed Agentic Operator that:
- Detects a failing pod.
- Collects logs and events.
- Uses an LLM (local or cloud) to generate a remediation plan.
- Creates a GitHub Pull Request with manifest changes.
- Runs policy checks (OPA/Gatekeeper) and CI validation before merging.
- Let's ArgoCD/Flux reconcile the fix into the cluster.
This pattern combines autonomy, safety, and auditability — the missing ingredients in most “AI + Kubernetes” experiments.
Architecture
Here’s the high-level flow:
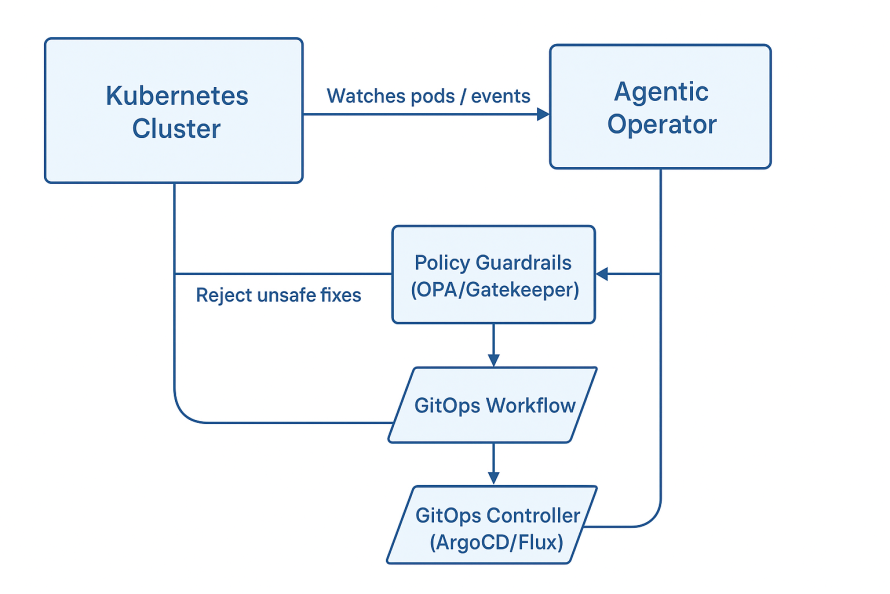
Step 1: Minimal Agentic Operator (Python)
We’ll use the Kubernetes Python client to watch pods and OpenAI for reasoning.
from kubernetes import client, config, watch
import openai, subprocess, os
openai.api_key = os.getenv("OPENAI_API_KEY")
def analyze_failure(logs, manifest):
"""Ask LLM to generate a remediation plan."""
resp = openai.ChatCompletion.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a Kubernetes reliability operator."},
{"role": "user", "content": f"Pod failed.\nLogs:\n{logs}\nManifest:\n{manifest}\nPropose a fix as a YAML patch."}
]
)
return resp["choices"][0]["message"]["content"]
def create_git_pr(branch, patch_file, commit_msg):
"""Commit patch and open PR via gh CLI."""
subprocess.run(["git", "checkout", "-b", branch])
with open(patch_file, "w") as f:
f.write(commit_msg)
subprocess.run(["git", "add", patch_file])
subprocess.run(["git", "commit", "-m", commit_msg])
subprocess.run(["git", "push", "origin", branch])
subprocess.run(["gh", "pr", "create", "--title", commit_msg, "--body", "AI-suggested fix"])
def main():
config.load_kube_config()
v1 = client.CoreV1Api()
w = watch.Watch()
for event in w.stream(v1.list_pod_for_all_namespaces):
pod = event["object"]
if pod.status.phase == "Failed":
logs = v1.read_namespaced_pod_log(pod.metadata.name, pod.metadata.namespace)
manifest = str(pod.metadata) # Simplified
fix = analyze_failure(logs, manifest)
branch = f"ai-fix-{pod.metadata.name}"
create_git_pr(branch, f"fix-{pod.metadata.name}.yaml", fix)
if __name__ == "__main__":
main()Step 2: Policy Guardrails With OPA/Gatekeeper
Before merging, we want to ensure no unsafe actions sneak in (e.g., disabling securityContext).
Example Rego policy (no_privileged.rego):
package kubernetes.admission
violation[{"msg": msg}] {
input.spec.containers[_].securityContext.privileged == true
msg := "Privileged containers are not allowed"
}Run OPA check locally:
opa eval \
--input fix-myapp.yaml \
--data no_privileged.rego \
"data.kubernetes.admission"Step 3: GitHub Actions CI Pipeline
CI ensures the fix compiles, passes lint, and applies cleanly in a dry run.
.github/workflows/validate.yaml:
name: Validate Fix
on: [pull_request]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Lint YAML
run: yamllint .
- name: Kubeval check
uses: instrumenta/kubeval-action@master
- name: Dry run apply
run: kubectl apply -f . --dry-run=server
- name: OPA Policy Check
run: opa eval --input fix.yaml --data no_privileged.rego "data.kubernetes.admission"Step 4: GitOps Deployment With ArgoCD
Once PR merges, ArgoCD syncs manifests to the cluster. The agent watches the pods again. If failure persists, it retries with a new PR.
Step 5: Demo
- Install the operator into your cluster.
- Trigger a failure (e.g., pod OOMKilled due to low memory).
YAML
resources: requests: memory: "64Mi" limits: memory: "64Mi" - Operator logs:
Plain Text
Pod myapp-xyz failed. Logs: OOMKilled. AI suggests patch: resources: limits: memory: "128Mi" - PR opens in GitHub → CI validates → OPA approves → Merge.
- ArgoCD applies new manifest → pod recovers.
Why This Matters
Most AI-in-Kubernetes articles stop at “AI can explain logs.” This pattern goes further:
- Safe automation: All fixes flow through GitOps + policy guardrails.
- Auditable: Each decision is a PR with context.
- Composable: Works with any GitOps tool (ArgoCD, Flux).
- Extensible: Add more policies (cost, compliance, SLO budgets).
Security and Compliance Considerations
Security is the most critical aspect of introducing LLM-backed automation into Kubernetes. While agentic operators increase autonomy, they must never bypass established security or compliance frameworks. Key practices include:
Secure API Keys in Kubernetes Secrets
Store OpenAI or other LLM provider tokens in Kubernetes Secrets. Mount them as environment variables with least-privilege RBAC rules so only the operator pod can access them. Rotate keys regularly.
Enforce Strict OPA/Kyverno Policies
All AI-generated manifests must pass through admission controls (OPA Gatekeeper or Kyverno). Example checks include blocking privileged containers, enforcing namespace isolation, and requiring resource limits. This ensures that even if the AI suggests a risky change, it is automatically rejected.
Secure Supply Chain in CI/GitOps
Sign and verify container images (e.g., using Cosign/Sigstore). Validate manifests with tools like Conftest in the CI pipeline before merging. GitOps reconciliation should only trust signed commits from verified contributors.
Require Human Approvals for Critical Workloads
For production namespaces or sensitive workloads (e.g., financial apps, healthcare), configure GitHub/GitLab branch protection rules so all AI-generated pull requests require human review. This balances automation with governance.
Auditability and Logging
Log every AI recommendation, the final applied manifest, and the policy evaluation outcome. Store logs centrally (e.g., in Elasticsearch or Loki) for compliance audits and incident forensics.
LLM Data Privacy Controls
Redact sensitive data (credentials, PII, financial info) before sending context to LLMs. If operating in regulated industries, consider self-hosted LLMs or fine-tuned models that run inside the compliance boundary.
Comparison With Alternatives
When designing auto-remediation strategies in Kubernetes, it’s important to understand how agentic operators differ from existing approaches:
Human SREs Fixing Issues
Site Reliability Engineers bring context, intuition, and creativity to novel failures. However, manual intervention is slow, error-prone, and doesn’t scale well in high-velocity, multi-cluster environments. Human review is best reserved for critical or ambiguous changes.
Traditional Self-Healing Operators (e.g., Karpenter, VPA, Cluster Autoscaler)
These tools excel at deterministic problems: scaling nodes, adjusting pod resources, or replacing failed infrastructure. But they operate within predefined rules. If the failure falls outside their logic (e.g., misconfigurations, novel runtime errors), they simply retry or escalate alerts.
Agentic Operators
Agentic operators bridge the gap. Powered by LLM reasoning, they interpret logs and manifests, propose concrete fixes, and validate them against policy guardrails before applying via GitOps. Unlike traditional operators, they can adapt to unseen issues. Unlike fully manual SREs, they automate the “first draft” of remediation while still allowing human-in-the-loop governance.
In short:
- Humans = deep context, slower
- Traditional operators = fast, rigid
- Agentic operators = adaptive, policy-driven, scalable
Next Steps for Readers
- Extend the operator to open Jira/GitHub issues if fixes fail.
- Integrate a local LLM (Ollama/LocalAI) for private inference.
- Add a feedback loop: store successful/failed remediations in a vector DB and use it for retrieval-augmented reasoning.
With this setup, you’ve built the first step toward truly autonomous Kubernetes — but with the safety net of GitOps and policy enforcement.
Opinions expressed by DZone contributors are their own.
Comments