How Hasura 2.0 Works: A Design and Engineering Look
We peek under the hood to see what makes Hasura 2.0 tick.
Join the DZone community and get the full member experience.
Join For FreeHasura GraphQL Engine launched as an open-source product in July 2018. Since then, Hasura has been downloaded over 200M times and has become the fastest-growing open-source GraphQL project globally.
Hasura accelerates API development by 10x by giving you GraphQL or REST APIs with built-in authorization on your data, instantly. In this blog post, we’re going to look at how Hasura works, what we thought about when building Hasura, and the problems we were trying to solve.
Then we’ll dive into what’s new in Hasura 2.0, which was released earlier this year. Again, this will be with a view on the issues that we were trying to address.
And finally, we’ll peek under the hood a bit and see how our engineers were thinking when they were building out Hasura 2.0.
Hasura’s Design Philosophy
The Problem
Hasura aims to help developers build fast. Our entire mission is to make tools that make it easier for devs to do their thing. To that end, a major problem that needed solving was the accessibility of and to data, especially for enterprises that needed to continually work with online/real-time data.
The recent trend has been that data is no longer being sourced from a single point and that data is being consumed in unsecured, unauthorized, and increasingly stateless and concurrent computing environments.
To do this successfully, you’ll need to build a data API that connects to multiple data sources and understands industry-specific logic, while keeping everything secure and performing.
This is a pain to do and takes up a lot of time.
The Solution
That’s where Hasura comes in.
Hasura allows you to configure a web server and expose a production-ready API within minutes. Months of writing code reduced to mere minutes.
So, as you can imagine, using Hasura allowed developers in startups, enterprises, and even Fortune 10 companies to build APIs and apps extremely fast and with record predictability.
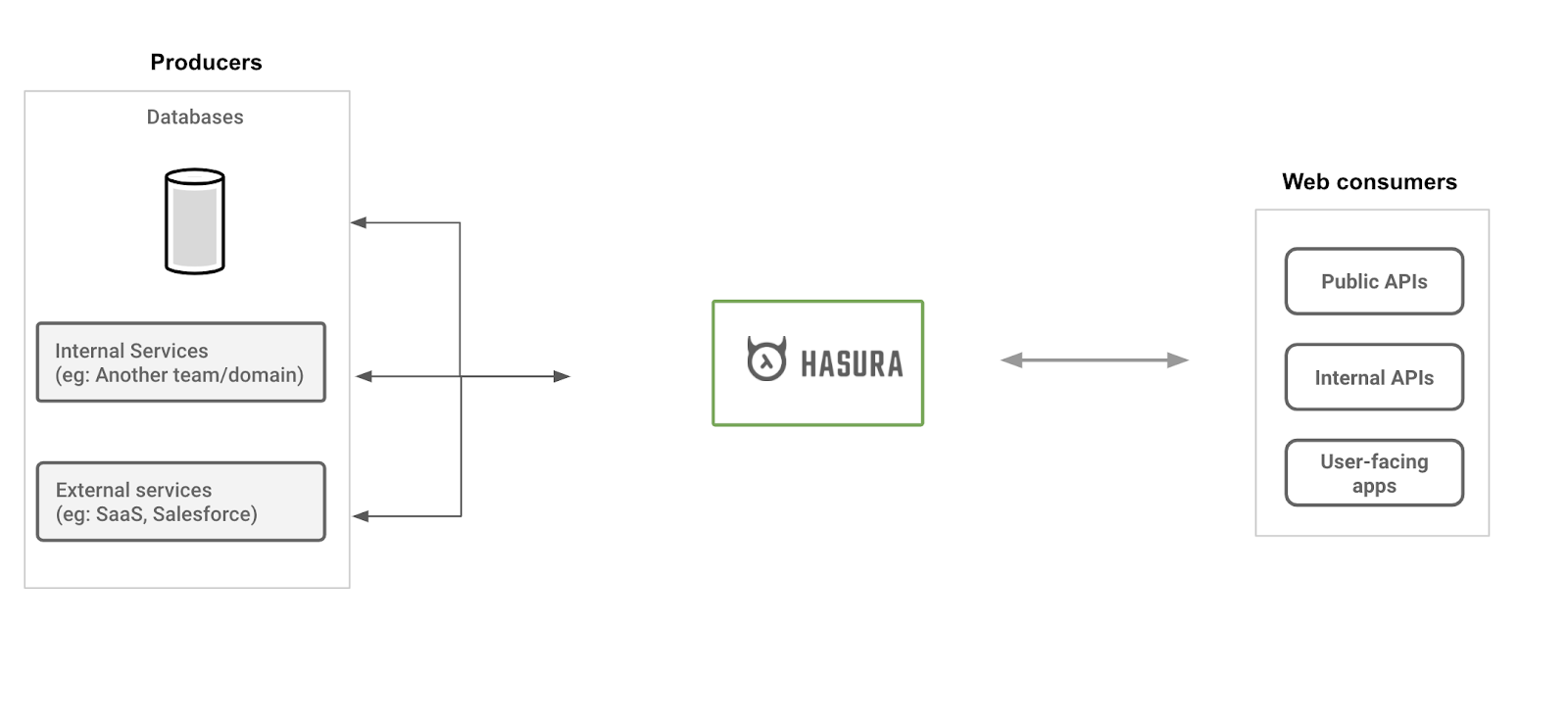
Design Inspiration
To create something that automates what devs were, up until that point, used to building by hand, we were quite inspired by databases.
Databases, or more specifically DBMSes, allow developers to operate on data without having to deal with actual raw files, are able to operate entirely at runtime, provide performance, security, availability, and are offered as a service.
And at Hasura, we endeavored to replicate this ethos but for data APIs.
“A convenient way to think about Hasura is that it is the frontend of a distributed database engine that works at the web-tier to support, ahem, web-scale loads.”
- Tanmai Gopal, Co-Founder and CEO, Hasura.
Hasura uses a metadata engine to comprehend industry-specific requirements of a data-access providing web service and uses that to give you web APIs that allow flexible and secure operations while also furnishing you with the SLAs and guarantees to ensure smooth functioning.
Be Production-Ready in Minutes
The tooling and concepts around Hasura have been designed in such a way as to ensure that getting Hasura up and running is easy and extremely quick. And it’s possibly the most important value that we provide to a business: reducing time to market.
Instant Data APIs
Using a UI, API call, or code in a git repository, developers can dynamically configure Hasura’s metadata once the service is running.
The following are stored by the metadata:
- Data source(s) connections.
- Models that map data sources and an API.
- Model relationships that exist between data sources and within the same data source.
- Model or method level authorization rules.
This metadata allows Hasura to generate a unified JSON API schema over GraphQL (now with REST Endpoints as well) and a production-ready web API.
Hasura is quite the JIT compiler, taking incoming GraphQL API calls over HTTP and then trying to achieve optimal performance while designating the downstream data sources to do the data fetching.
Hasura initially had support only for Postgres and the Postgres family (Aurora, Timescale, Yugabyte), because of the rising popularity of Postgres. With Hasura 2.0, you can now get instant data APIs on SQL Server, Big Query, and MySQL. From Hasura 2.0 onwards, you can also simultaneously connect with multiple databases.
Built-in Authorization
With developers consuming data in unsecured environments, data access cannot be automated without authorization rules. Hasura’s authorization engine gives developers the ability to embed declarative constraints at the model level, allowing Hasura to use the correct authorization rules for any API call.
And with these declarative authorizations being completely available at runtime through APIs, devs now have access to additional observability into the authorization structure examples of which are, say, tooling that’s now available to help one review and manage authorization rules, as well as visibility into what authorization rules were used or triggered by the end consumer through an API call.
Certain database engines offer a declarative system of Row Level Security and our authorization system kinda resembles that, but for the application layer. In fact, coincidentally, our authz system was built simultaneously as Postgres RLS was introduced!
Authz rules apply to all of the JSON data graph and their methods. For example, allowing access if document.collaborators.editors contains current_user.id, i.e., any property of the data spanning relationships, or allowing access if accounts.organization.id is equal to current_user.organization_id, therefore applying the authz rules to any property of the user accessing the data. Moreover, we can have 'roles': essentially a set of rules that encrypt/mask/tokenize portions of the data model or the data that’s returned by a method.
All of the above, allows Hasura to provide a “Google Cloud IAM-like” permissions system and to generally provide RBAC, ABAC, other hierarchical multi-tenant permissions, and so on.
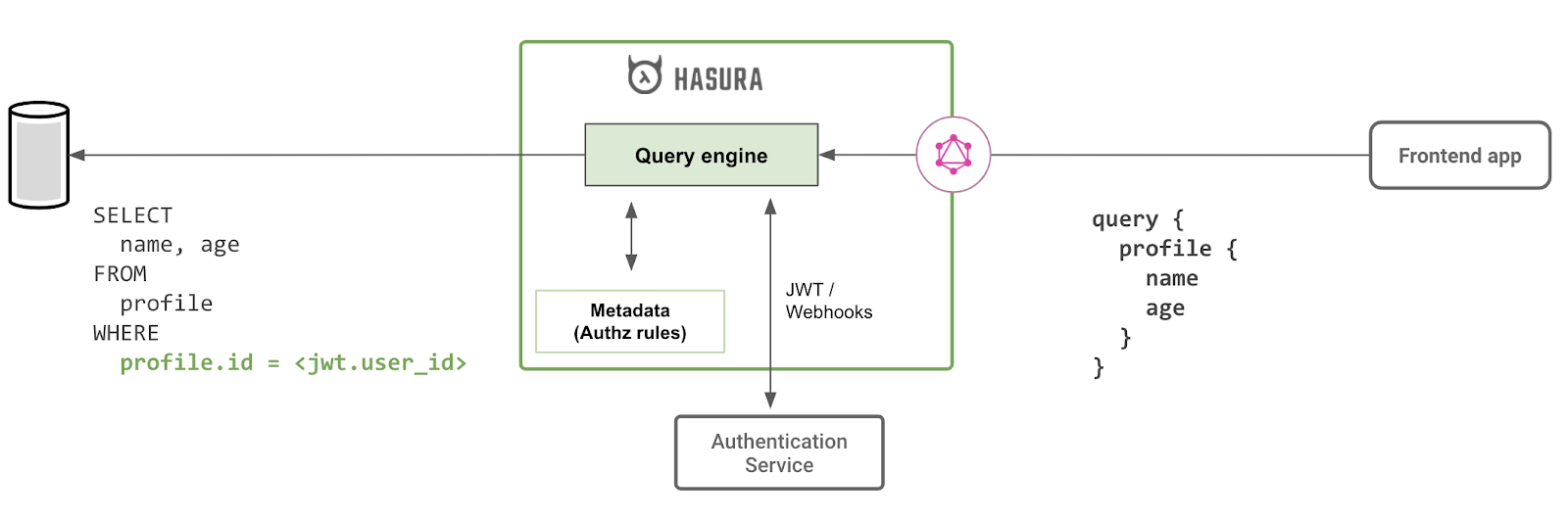
Declarative Authz System
Advantages of a declarative authz system:
- Authz and data access in a transaction — Quite often, the same system has both the data fetch and the authorization rule, allowing for the fetch and the authz check to occur "atomically" thus making sure that the authorization rule isn’t invalid by the time the data is fetched.
- Authz predicative push-down — Hasura can provide a meaningful benefit to performance, by an automatic push-down of the authz check in the data query itself, wherever possible. This also helps in avoiding additional lookups wherever it can be sidestepped.
- Authz caching — For hot queries, one would have to update and cache authentication info or authz checks, and this is something that Hasura can do automatically as required.
- Private-data caching can be automated — Hasura can automatically determine if the same data is going to be fetched by multiple GraphQL queries made by different users, and hence, knows “what to cache” because Hasura can 'think' about the authz rules. Previously, devs would’ve had to build this part of application-level caching manually, but now Hasura automatically does it!
Hasura works seamlessly with a whole host of amazing SaaS and open-source identity management and authentication “as-a-service” providers like Keycloak, Okta, Auth0, Azure AD, Firebase Auth, and more. In fact, Hasura also integrates with custom community-built solutions like hasura-backend-plus that provides an auth service for Hasura. Typically, in most existing environments, the auth is provided by an external service or system, and so we’ve decided to focus on the Authz (which Hasura does really well!) and let others handle the Auth. And Hasura works with a variety of Auth solutions!
Application-Level Caching
Hasura can implement API caching for dynamic data automatically because Hasura’s metadata configuration has got detailed information about both the data models as well as the authz rules that in turn have information about which user can access what data.
And this is very useful because, otherwise, developers often need to manually build web APIs that provide data access manually. Moreover, devs need to have deep domain knowledge so that they can also then build caching strategies that recognize what queries to the cache for which users/user groups, using caching stores like Redis to provide API caching.
But this is just a part of the problem.
The harder bit is cache invalidation. Developers use TTL-based caching to avoid worrying about caching invalidation vs consistency and let the API consumers deal with the inconsistency.
Hasura, can, in theory, provide automated cache invalidation as well because Hasura has deep integrations into the sources of data and all access to this data can go through Hasura, or use the data source’s CDC mechanism. This part of the caching problem is similar to the “materialized view update” issue.
So, in essence, we’ve ventured into automated application-level caching but have a long way to go through the potential is super encouraging.
Tanmai has spoken about this in detail at GraphQL Summit last year. Check it out!
Driving Stateless Business Logic
It’s getting harder and harder to drive stateless business logic in this new climate of polyglot data and microservices.
Event-driven patterns, that allow business logic to be as stateless as possible, have been developed to handle high-volume transactional loads and these help in coordinating a sequence of business logic actions that execute exactly once and don’t require roll-backs to handle failures. Business logic is invoked on an event and resembles “pure compute”. Any data required during the execution is accessed over HTTP APIs.
Now, this is super hard to do. So, we’ve made it such that Hasura uses an eventing system that gives devs a simple way to write stateless business logic that works with Hasura over HTTP.
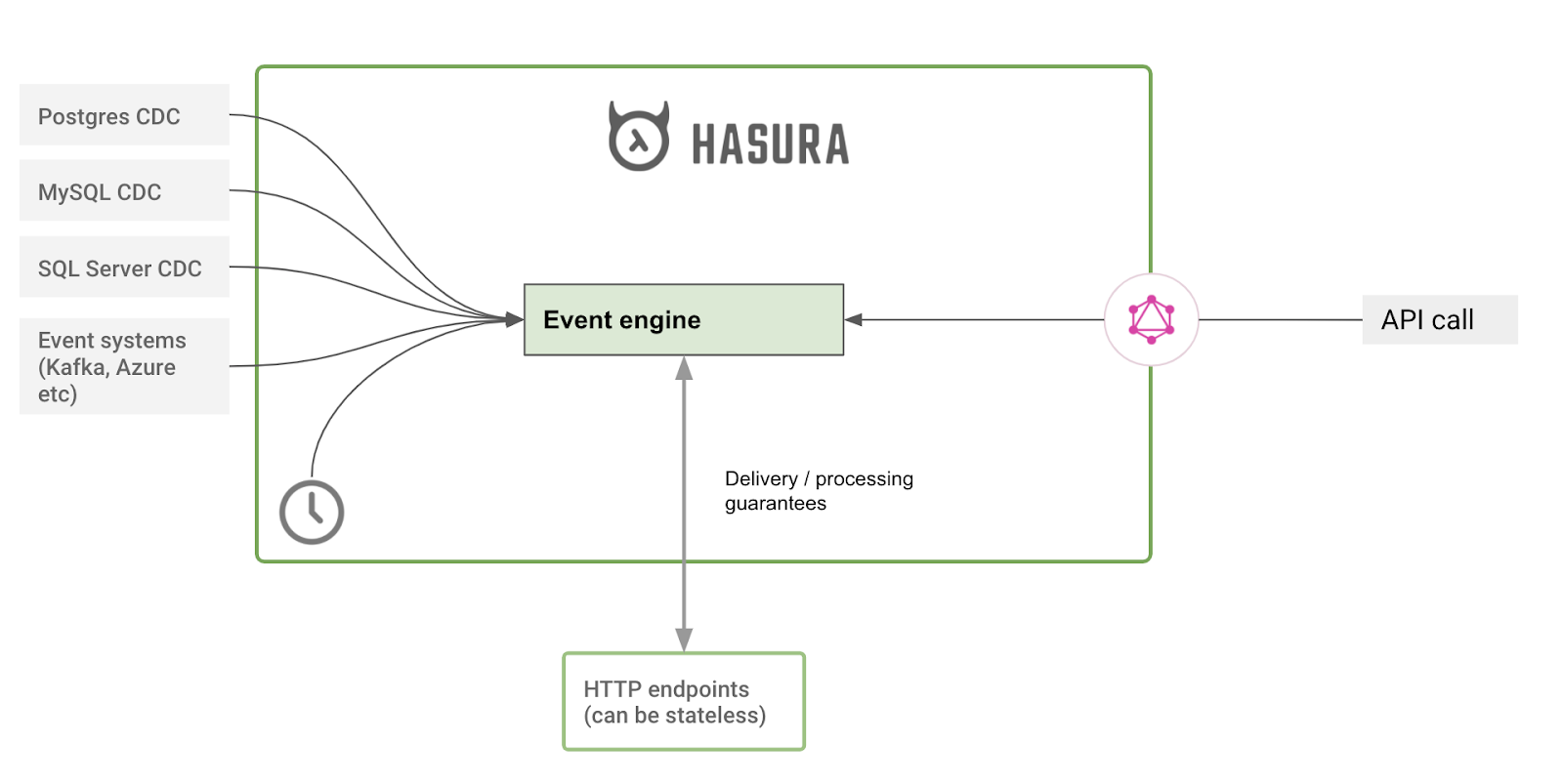
With Hasura capturing and delivering events over HTTP while making certain guarantees like at least-once and exactly-once, devs can now work on stateless business logic just as they did in a stateful environment.
Read more about Hasura’s eventing integrations like Change Data Capture, API events, and Time-based events.
Realtime APIs, Also Known As GraphQL Subscriptions
Realtime APIs over WebSockets are quite stateful and expensive, making them incredibly difficult to deal with in production. WebSockets also need another layer of web security implemented.
Meanwhile, Hasura integrates with databases and can provide a scalable realtime API to end API consumers, similar to a WATCH API or a GraphQL subscription to watch changes on a resource, and due to Hasura’s authz system, send the correct events to the right consumers.
Learn more about how Hasura gives you a scalable subscriptions API on Postgres.
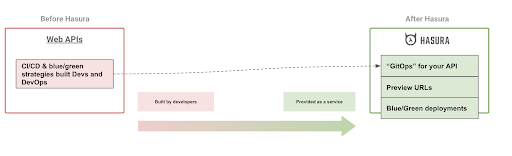
Change Management and Continuous Integration/Continuous Deployment
Preview URLs (ref: JAMStack ecosystems) allow for human stakeholders to manage development, staging, QA, etc. They’re endpoints that host different versions of a static application in different dev stages. A/B rollouts, Blue/green deployments that can be used to publish multiple versions of the app simultaneously while splitting traffic between them with some simple tinkering, DNS rules, or load-balancer configuration, are also super useful.
We want to bring this ability to dynamic APIs.
And since Hasura is entirely configured at runtime, is an API system, and can isolate its metadata configuration in an external system, it easily allows for the following:
- Previewing a metadata change when a new version of your API is deployed by you against the same data source.
- To ensure a smooth roll-out, run multiple versions of Hasura against the same data sources.
Federated Data and Control Plane
Hasura’s metadata system is fully dynamic and configurable via APIs at runtime, and for these metadata APIs, we’re building an authz system that will allow you as an API owner to federate control to the appropriate data source owners. Hasura gives you a federated control plane to make sure your online data that’s present across multiple sources is properly federated.
Learn more about data federation with Hasura’s Remote Joins — a GraphQL API to join across your database and other data sources.
Use Your Favorite Language or Frameworks With Hasura — No Lock-In!
Hasura uses can bring their favorite language, framework, runtime, and hosting vendor, because, at the heart of it all, Hasura is a service that integrates with other services over the network via native connections to data systems and over HTTP for API consumption or for driving business logic. This ethos of letting our users use Hasura as they see fit, allows us to build Hasura in a relatively decoupled environment, encouraging users to adopt the latest tech and use it with Hasura.
No-ops
The future is no-ops and less DevOps and Hasura, being a self-contained service, allows us to build an auto-scaling service integrating with APM and tracing tooling thus making sure that the data API service doesn’t foist a heavy operational burden. Also, since upstream data sources require it, Hasura natively integrates the health-check, availability, replication, scalability, and circuit breaking patterns, all in all making sure that our vision for the product as well as the business value that Hasura provides is recurring and growing.
Changing Data Models? No Problem
Hasura gets its APIs from the metadata configured and not from a database giving Hasura the capability to deal with all the issues that crop up from exposing data models directly, while still deriving benefits from such an approach.
And, to be honest, data models are meant to change for a number of reasons: they evolve with the business, they’re normalized or denormalized to make writing or reading data easier or faster, and in extreme cases databases are changed altogether.
Hasura metadata can itself contain the correct mappings allowing for devs to redefine their data model mappings while preserving the end APIs, and moreover, doing so without needing any extra DDL on the database.
For example, if a whole table ceased to be, Hasura’s metadata can contain a named query (and this analogous to database concepts like views) that persists in exposing the same API model, but now it’s mapped to the named query, ensuring that the data fetched is from multiple tables in place of the one.
Customizing Hasura’s API is Easy
By automatically generating a large portion of the needed APIs using metadata that you provide, Hasura allows you to extend the API by adding custom business logic to the mix. A CQRS model is encouraged while adding custom APIs for which all the requirements are already taken care of. This lets you then add your own API and plug it into Hasura as a set of REST endpoints, and this can be done in the language, hosting provider, or a framework of your choice.
Using Hasura for Existing Apps
Hasura has been designed to immediately add value: point Hasura to an existing data source be it a database or GraphQL or REST, add some of your configurations, and Bob’s your uncle.
In fact, a bunch of our customers use Hasura to add high-performance GraphQL queries and subscription support to existing apps while using their already existing APIs for writes. So, basically, you don’t need to start from scratch or build your stack from the ground up. You can use Hasura for incremental adoption.
If you need help thinking through your architecture, feel free to join our Discord or better still, find us on GitHub Discussions.
Hasura 2.0 — Multiple DBs, REST Endpoints, and More!
Try Hasura 2.0 on Hasura Cloud or try it with Docker. And check out Tanmai’s webinar.
Hasura 2.0 is backward compatible with all 85 releases of Hasura over the last 2 years because we’ve made sure that we never break user-facing APIs and we’ve managed that with 2.0 as well: users will get all the new features without having to refactor their work.
So, here are the 5 new features in order of importance.
1. Connecting Multiple Databases Simultaneously and Database Generalization
Hasura initially had support only for Postgres, which, in hindsight, was a pretty good choice on our part because of the rising popularity of Postgres and its ecosystem, as well as the fact that we could focus our efforts on the engineering and product side of things.
But with Hasura 2.0 we’re opening it out to more databases. This is being done in two ways:
- Allowing for multiple databases to be simultaneously connected.
- And the support for more databases.
1.1. Connecting to Multiple Databases Simultaneously
It’s been evident from the work we’ve done with our users, in particular, those who are dealing with enterprise and mission-critical workloads, multiple new or existing databases (even if just Postgres) are required.
Two leading use cases that we’ve observed:
- Multi-tenancy: Oftentimes, to facilitate scaling or to impose stricter data isolation, different tenants will have their data bucketed into different Postgres databases.
- Different workloads: Depending on the requirements, data will be consumed from different Postgres databases very differently. A Postgres database will be optimized very differently for search, or for time-series, or for high transaction volumes, or for any other purpose.
Now, Hasura 2.0 allows you to bring in multiple databases at the same time to a single instance of Hasura or a scaled-up cluster of Hasura instances. With 2.0, you can add or remove DB sources as and when required on a Hasura instance that’s running, instead of supplying a single env var.
1.2. Database Generalization
We’ve reworked our query compilation pipeline so that it can be now generalized to any database easily and not just Postgres, which was always just the starting point for us here at Hasura.
Another point to note is that existing or legacy mission-critical data isn’t actually always on Postgres, defeating the purpose of being able to query the source directly, which is especially important for fast-moving operational and real-time data. And ETL-ing this data that’s not on Postgres into Postgres is costly and therefore infeasible.
And finally, there are other databases and newer data workloads may go into those.
So, with all that in mind, Hasura 2.0 has support for SQL Server and BigQuery — our first OLAP database. Hasura Cloud works now with SQL Server or you could also try Hasura with Docker and SQL Server.
Our goal is to be able to add a new relational database engine within 2 weeks (which is why we’ve started with generalizing to relational databases) but the philosophy is to keep the final GraphQL API similar without normalizing all these databases to some common denominator — the aim is to bring out the unique flavor of each database while adding to that the benefits of Hasura like GraphQL, authorization, eventing, and everything else.
Help us prioritize which databases to bring into Hasura on our Github. We’ll be adding more over the course of the year.
1.3. Remote Joins
Hasura supports “joining data” in certain specific directions across heterogeneous sources to allow API consumers to view a semantically unified graph of their API models.
We’re now looking to add the following remote join functionalities: remote schemas to databases, remote schemas to remote schemas, and database to database.
2. Support REST Endpoints, and Not Just GraphQL
GraphQL APIs are arguably the best modern API tech available today. But that being said, REST is also still popular for a number of reasons. So, we’ve decided to make sure that Hasura supports both REST endpoints and not just GraphQL.
To explain why we came to this decision, let’s dive into what GraphQL does well and why it doesn’t always see the light of day in production.
GraphQL aimed to provide a specification for automating API composition on User Interfaces while creating a type-safe client-server contract over JSON. But its success is broader. In fact, true GraphQL fans will argue that Relay style GraphQL and GraphQL fragments should be far in vogue than it is today. This is probably because GraphQL solves a wider problem than just automating API and composition on the UI.
GraphQL has changed the way we think about APIs in 2 ways:
- Self-serve consumption: Without the need for handwritten documentation and tooling, API consumers can now browse, test, explore and integrate APIs in a much tighter feedback loop.
- Query what you want: Now, humans (yes, them!) aren’t required to build custom endpoints for their favorite data shape — API consumers can craft an API query to get exactly what they want. It’s actually pretty ridiculous when you think about all this in terms of databases — imagine a database that only serves your data in a fixed shape! Madness. So, we want and need this for our APIs and GraphQL is helping with this — performance, caching, security and everything else should just work!
So, that’s great and all, but, and this is a big but, GraphQL APIs aren’t always used in production even where it could have been technically possible, for 3 reasons:
- For mission-critical applications and in enterprise environments, the cost of adopting GraphQL may be too high because of the lack of GraphQL vendor tooling around GraphQL in production. Ops, caching, monitoring, error and QoS reporting, authz, security are new with GraphQL.
- There are folks who love GraphQL for the tooling but are not building frontend apps (for example on a public API or for devs making other services), and they may not want to or be able to use GraphQL clients in their code.
- REST APIs are here to stay. So, that means maintaining multiple API engines for all time just to make sure that some API consumers aren’t alienated. The cost of maintaining both a GraphQL API and a REST API simultaneously is mad.
Hence, Hasura 2.0 lets you create idiomatic REST endpoints based on GraphQL templates.
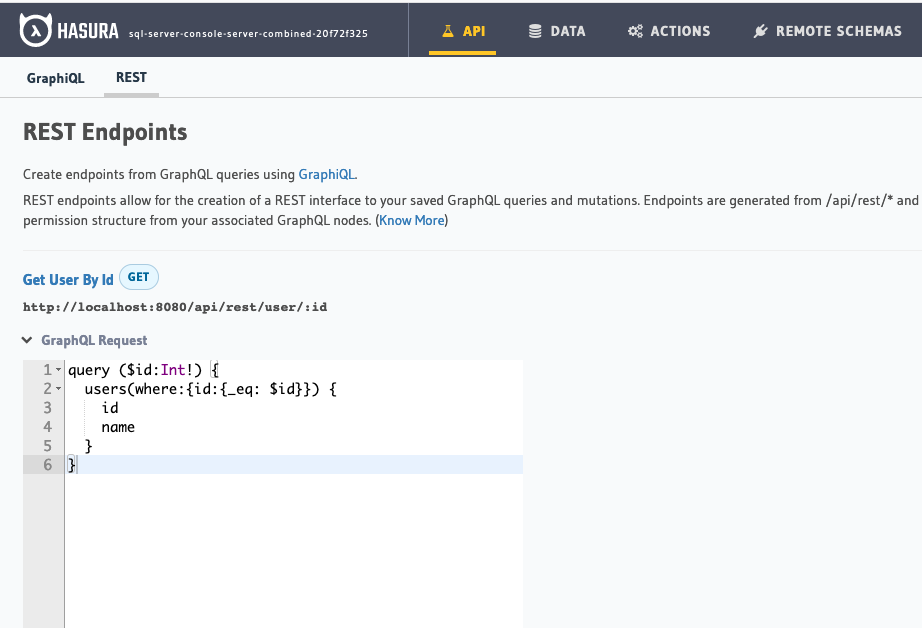
Create a REST endpoint from a GraphQL query template.
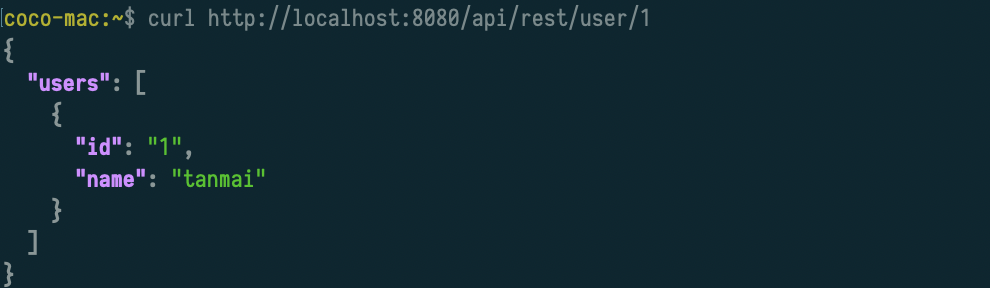
Making a REST API call to Hasura.
Now, whenever required, Hasura gives you the benefits of GraphQL and REST. Hasura makes use of GraphQL as an in-between representation and transforms a RESTful request with its parameters into a parameterized GraphQL query and then executes that query.
Here’s the REST to GraphQL interoperability specification on GitHub.
The key difference between what we’ve done here and said, the idea of 'persisted queries' is the fact that idiomatic REST is supported which means supporting error codes, caching headers, REST-style verbs, parameterization, and even OpenAPI/Swagger documentation for created endpoints.
3. Authz Engine
Hasura 1.x already had a highly evolved authz engine — analogous to RLS-style authz in databases — giving Hasura the ability to extend its authz policy across data sources without being limited to the authz features supported by a particular database.
With 2.0, Hasura now features authorization (role-based schemas and preset-arguments) on remote GraphQL services, such as internal GraphQL services or external GraphQL APIs.
In the future, this will be extended to create a generic and unified RLS-style authz layer across all data sources. The need for declarative and 'human observable' authz is becoming more and more important as data explodes.
Hasura 2.0 also features a policy inheritance system that allows composing fine-grained RLS or ABAC style policies without interrupting the run.
4. High Availability and Distributed Ops
A possible single point of failure is a GraphQL layer fronting multiple data sources. Hasura 1.x could already seamlessly run a cluster of replicas, scaled up, and they would sync with each other automagically.
And with 2.0, we wanted to make sure that folks could run a Highly Available and “distributed” Hasura cluster along with its interaction with a set of upstream data sources as easily and seamlessly as possible.
We wanted to ensure that Hasura’s interaction with upstream sources was faultless and scalable to prevent that single-point-of-failure problem.
Hasura 2.0 has a 'maintenance mode' that lets you upgrade Hasura and its connected sources without any downtime to the GraphQL API and event delivery systems.
5. Metadata APIs
Hasura is a GraphQL server and its configuration is entirely dynamic and API driven, and more importantly, doesn’t require a build step! This metadata API makes change management super easy while it can also be locked down in production if required.
Also, these metadata APIs allow users to fetch all of the configurations of a Hasura system on the fly. It’s super powerful.
And this in turn gives rise to the following metadata capabilities:
- Creating a data dictionary of the underlying data models — their documentation, frequently used columns, recommended query patterns, etc. Here’s a starter kit for building your own on top of Hasura.
- Observing security and authz config and rules on the fly — seeing which authz clauses are being used by certain requests.
- Making community and organization-specific base metadata configs and using this to inspire common standards and best practices.
So, these aren’t necessarily all available in Hasura 2.0, a lot more metadata tooling is on its way!
The one that we’re most excited about: Instant git push (or GitHub webhook) to deploy database migrations and Hasura metadata changes to your staging and production Hasura instances.
Hasura 2.0 Engineering Overview
We released 2.0 in Feb and it was a mammoth task with over 6 months of engineering effort.
What All Changed
We changed a bunch of things in the core of the product:
- Switching to the new "Parse, Don’t Validate" approach.
- Separating the storage of Hasura’s metadata from the Postgres database.
- Support for multiple Postgres backends.
- Support for new kinds of relational database backends, starting with SQL Server.
- Support for inherited roles.
- Support for REST endpoints in addition to GraphQL.
Even with all these changes, 2.0 is backward compatible with Hasura 1.x and you can read about how to migrate from Hasura 1.x to Hasura 2.0.
Parse, Don’t Validate!
“Parse, don’t validate” (or PDV) is a principle we used to get from v1.3.3 to v2.0 and it started in August 2020. Here’s an outline of PDV:
- When receiving unvalidated inputs, attempt to convert (i.e., parse) them into values whose types refine the types of the inputs, ruling out invalid states where possible, using the information learned during validation.
- Don’t simply check for invalid states and pass along the inputs regardless (i.e., don’t just validate).
For example, if we receive a list of data, and we want to validate the property that this list isn’t empty, then instead of just checking if the list is empty and passing along the input unchanged (because it isn’t empty), we can instead check if the input list is empty or not, and say, we can assign a stronger type, say, the type of non-empty to its value. This turns the validator into a parser where it parses possibly-empty lists into non-empty lists or fails with a validation error.
So, if I received date as a string, I can parse it into an actual date at the point of validation. This kinda thing is seen a lot when parsing JSON structures into typed representations.
Server Metadata
The Hasura GraphQL Engine configures running GraphQL servers with a data structure which we call metadata, and this metadata can be exported and worked on as a JSON/YAML doc, or indirectly manipulated by the server when performing actions such as tracking tables.
This metadata has information about everything required to take the data and convert it into a GraphQL service that works.
In Hasura 1.x, we would validate the input metadata and store it in the application’s schema cache. In 2.0, we’ve switched to parsing the input metadata, and refining it to collect everything we know about it after validation.
- We elaborate the unchecked table definitions in the input metadata by enriching it with relevant column info from the data source. This gets done in the schema cache.
- Unchecked relationships between tables are parsed into object graphs on the Haskell heap itself.
- By adding schema information discovered by introspection unchecked remote schema definitions in the input metadata get elaborated in the schema cache.
Dealing With Memory Issues
The PDV approach was useful because, after initial checks on the input data, the Haskell type system can be used to represent the condition on the checked data, thus enabling us to rule out a lot of error cases in our data. Alas, this approach was expensive: the application’s memory usage had increased on certain workloads.
We didn’t notice any regression during development since the new system was pretty much the same as the old one barring the memory usage issue, and we didn’t have enough performance benchmarks in our continuous integration pipeline — something that we’re fixing.
To illustrate how badly we’d missed out on noticing this, picture the following: we’d merged the PDV functionality to the main branch and had also merged several other changes as well before noticing the regression.
To solve it, we maintained two parallel branches while working to fix the source of the memory issues. This forced us to backport many fixes to the release branches though.
Luckily, we figured it out, with the help of the GHC/Haskell peeps at Well-Typed. The new ghc-debug tool allows us to inspect the Haskell heap at runtime, and find undesired patterns:
- A reference to a large value that was leaking leading that value to be retained unnecessarily on the heap, and,
- We weren’t taking advantage of sharing on the heap.
The baseline memory consumption had gone up vs the v1.33 release but we figured that this was just the price of the new abstractions being used, and were OK with it for the time being.
Supporting Multiple Sources
Hasura 2.0 supports multiple database sources, initially Postgres and SQL Server, and we’ll be adding more relational databases and eventually non-relational sources as well.
For users, adopting Hasura became that much easier: there’s no need to have a ready database or to create a new database.
Multiple Postgres
First, from an engineering perspective, we looked at the multiple Postgres sources problem, which isn’t as simple as one would think it is.
A few things cropped up: namespace collisions across sources, connection pools whose lifetimes were no longer tied to the lifetime of the running server, several fundamental changes to the UI, and changes to basic APIs that had assumed the existence of a single-source database.
To support the case of zero Postgres databases, we decoupled the Hasura metadata storage from the source database. This is now stored in a totally different database and in fact, for Hasura Cloud, we host it on our servers. We also improved the way we store this Hasura metadata by adding optimistic locking and simplifying the approach to synchronized schema updates across Hasura nodes in a high-availability setting.
Different Databases
Next, was to add support for multiple types of data sources, including SQL Server. Haskell’s strong type system and our comprehensive test suite helped us refactor all this.
The refactoring required us to rework almost everything about the operation pipeline. In 2.0, everything from parsing to type-checking to execution has been generalized. Several issues had to be considered:
- In Postgres, we pushed down N+1 queries and other operations to the database, with jsonb aggregations, but that may not work with other databases.
- Certain Postgres data types aren’t available in other databases.
- Different databases behave differently in a subtle way sometimes (like case sensitivity in naming tables and columns).
- Certain features would have to be completely turned off for other databases.
To solve all this, we introduced a bunch of new type classes into our code especially for the various backend operations we needed to support:
- The Backend type class: this became the root of the new hierarchy of these abstractions, defining the data types for various leaf nodes and relationships in our AST.
- The BackendSchema type class: responsible for any GraphQL root fields exposed by a data source.
- The BackendExecute type class: responsible for constructing execution plans, and,
- The BackendTransport type class is responsible for executing those plans.
The plan is that if one wants to implement a new backend for Hasura, these new type classes have to be used.
The design and implementation of these type classes were relatively straightforward but incorporating them into the wider product design raised some questions. We want the outermost layer, the API should just talk about database sources in general and not in terms of backend types such as Postgres and MSSQL. This means that in our source list, these databases need to be side by side in the same list, and Haskell’s type system isn’t happy about mixing values of different types in a single list.
Luckily, Haskell lets us combine different backend implementations into a single list using a feature called existential types. And this was what we used to solve the issue.
This approach is similar to using bounded quantification (to the extent that type classes are like interfaces in Object-Oriented Programming languages) — we delete enough type info to store values with different underlying implementations in the same list, but keep their specific implementations usable in the form of their type class instances.
The downside, just like with bounded quantification, we can’t make use of specific features to say, the Postgres implementation, but only access the sources via their type class instances.
Memory Issues, Again
With the end in sight, memory issues cropped up again. By this time, we’d already eliminated the memory leaks brought up by the PDV refactoring.
When workloads had long bursts of mutations, the expected increase in memory consumption was being observed but it wasn’t going back to baseline levels after the burst was complete — the garbage collector wasn’t doing its thing. In fact, the final memory consumption was a lot higher than expected.
Eventually, investigations and graph plotting showed that the memory usage reported by the operating system was routinely higher than what the GHC runtime was reporting, even after the burst of mutations had finished. It looked like the runtime system wasn’t promptly returning memory to the operating system.
The GHC experts at Well-Typed help us solve this problem. The GHC is expected to retain some allocated memory for future requirements, but this isn’t great for bursty workloads. Future versions of GHC will have additional flags to control the rate of return of memory to the OS.
Also, there was a bug in the GHC runtime system which has been addressed where pinned memory was being allocated suboptimally.
After all the fixes, the memory consumption returns to the expected baseline even after bursty mutations and similarly maintains a relatively healthy memory profile during workloads such as this.
Using Haskell for Hasura
Haskell type system’s strong guarantees allowed us to refactor confidently on complex development features but there’s a trade-off because of the costs involved as well. Companies using Haskell and similar languages need to invest deeply in the community, as proved by our work with Well-Typed in this space which was extremely useful. We will continue to invest in the Haskell community as we continue to build Hasura.
Hasura 2.0 was a massive milestone in our journey, with many large feature updates that set us up for the development of newer features in the future such as generalized joins and generalized permissions that will allow us to stitch together all of your different data sources into a single, unified graph with all of the additional Hasura features that we’ve featured so far.
Conclusion
Hasura 2.0 is now being used in production in organizations like BBVA, Credimi, Cynthesize, Airbus, Swiggy, ProPublica Illinois, Cherre, SoftBank, Lineup Ninja, KintoHub, and more. Startups like Pipe and Pulley are also using Hasura 2.0 to grow at scale.
So, that was an overview of How Hasura 2.0 works. This article draws heavily from, is deeply inspired by, and is basically a smushed-up version of three posts on our blog, namely: Hasura’s Design Philosophy, Announcing Hasura 2.0, and Hasura 2.0 Engineering Overview. I strongly recommend reading through those if you’re looking for a deeper understanding of how Hasura 2.0 works, though I’ve tried my best here to give you an amalgamated synopsis that covers the salient features. I hope this piece can be a good starting point before going into those articles.
And I hope you have fun checking out Hasura!
Opinions expressed by DZone contributors are their own.
Comments