How to Choose the Right Messaging System for Your Organization
I will begin to explain what message queuing, and streaming is. Then look at some core and advanced capabilities required for modern data architecture.
Join the DZone community and get the full member experience.
Join For FreeIn terms of messaging technologies, we have dozens of popular options on the market, while each of them may only support certain use cases in the queuing and streaming space. Before I explain how to choose the right messaging system, I think it’s worth taking some time to explain message queuing and streaming first. With a basic understanding of these concepts, we will then look at some core and advanced capabilities required for a messaging system for a modern data architecture. After that, I will give a high-level overview of Apache Pulsar, a cloud-native messaging and streaming platform, and explain what makes Pulsar suitable for some common messaging scenarios.
Queuing: Decoupling
A message queue (also known as a queue) is used to store messages with a first-in-first-out (FIFO) data structure. Messages stay on a queue until they are consumed by other applications or systems. Many programming languages have built-in message queues as data pipelines between tasks for asynchronous decouplings, such as java.util.Queue in Java.
Let’s see a real-world example to understand how a message queue works. Chris made a deal with John that he would buy John’s laptop. Instead of giving him the laptop in person, John chose to use a delivery service. After John gave the packed laptop to the delivery company, it shipped the package to the warehouse closest to Chris. After the package arrived, the company notified Chris that he could come to pick up the package at any time. Alternatively, John could give Chris the laptop directly while they must first decide the time and place to meet.
This dependence on time and place may cause some inconvenience to both of them. However, they can remove the dependence by choosing to use the delivery service. The delivery company only needs to notify Chris after his package has arrived, and then he can pick up the package whenever he is available. This is a more cost-efficient way, as neither of them needs to go to the same place at the same time just to make a simple deal. This is where a message queue comes into play.
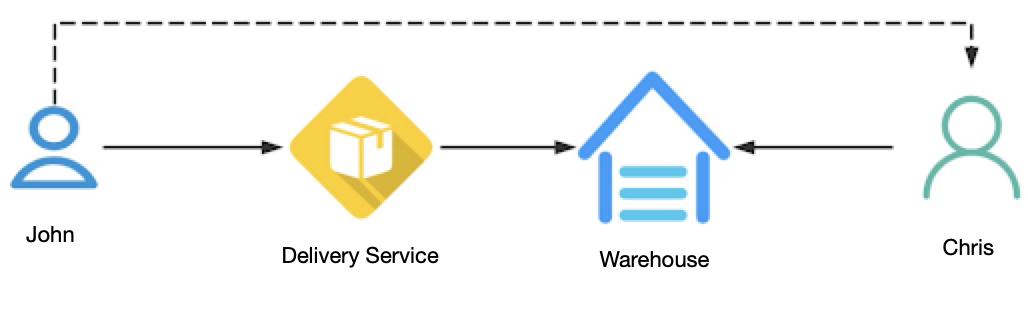
There are numerous similar cases in an organization’s business workflows. Upstream systems publish messages to a message queue, which uses a buffer to store the messages temporarily. After receiving notifications that the messages have arrived, downstream services then retrieve these messages from the queue, completing the entire process.
These downstream services are decoupled from each other. For example, an e-commerce system may be composed of multiple services, such as ordering, payment, and delivery. It does not make any sense to wait for all of them to be complete before we can finish the entire business process. After all, most of the requests can be processed asynchronously. Some non-critical workloads (for example, the Notification service) should not block the entire workflow.
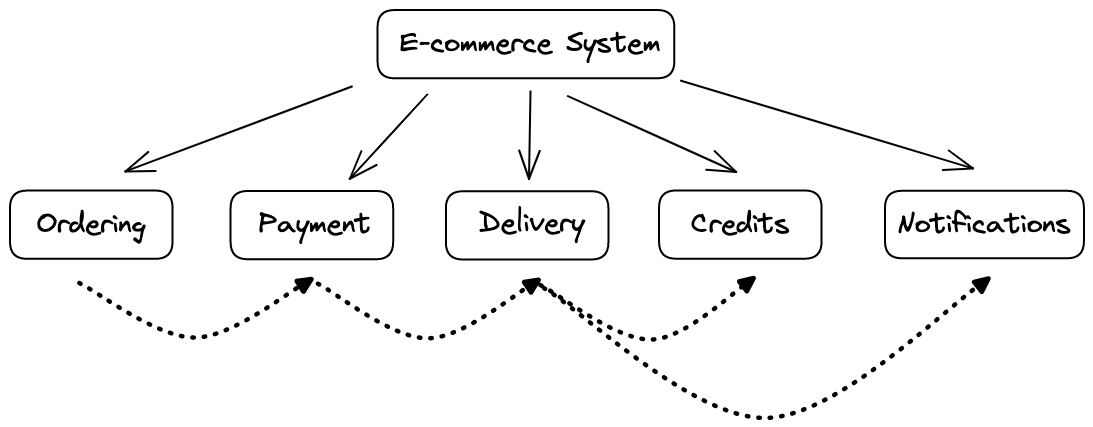
The image above depicts a canonical example of an e-commerce system. A message queue can help decouple different services. After a user finishes the payment, the process can be considered complete, with all the follow-ups implemented in an asynchronous way.
In this scenario, the basic requirements for the message queue are performance, latency, and persistency. You can understand them in the following ways based on the laptop delivery example mentioned above. All of them have a direct bearing on how the delivery service is evaluated.
- Performance: The number of packages the delivery service can ship at a time.
- Latency: How long it takes for packages to be delivered to the destination.
- Persistency: The number of packages that a warehouse can store.
Streaming: High Throughput
In the big data era, data has played an increasingly important role for enterprises. To better extract the value of our data, we need a unified platform to collect and integrate them for further processing. In this aspect, a messaging system can serve as the platform’s backbone to receive large streams of data, including application messages, service records, and business data in databases. This way, the messaging system can further feed real-time and offline warehouse services with raw data and even provide stream processing if necessary. For example, organizations can combine processing tools like Apache Flink and Spark Streaming with the messaging system in the workflow.
Compared with queuing, streaming requires the messaging system to be able to handle a considerable amount of data with ordering guarantees.
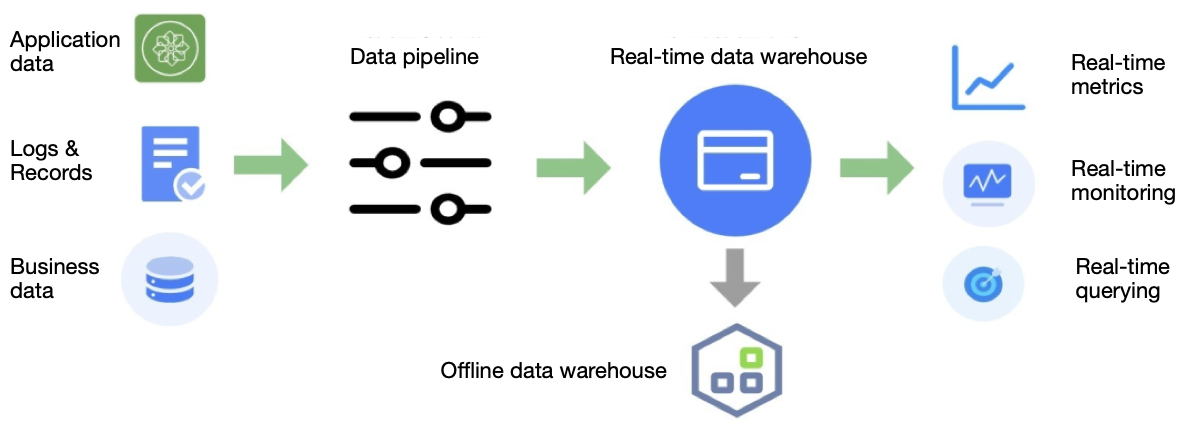
Now that you have gained a basic understanding of queuing and streaming let’s explore the capabilities necessary for a messaging system to meet the needs of modern business and infrastructure.
A Messaging System for the Modern Data Architecture
Core Capabilities
To select a distributed middleware solution, we need to first consider reliability, consistency, availability, and performance.
- Great reliability. Typical message queuing scenarios have high requirements for data reliability, where organizations cannot afford to lose any data. A best practice for it is to store multiple copies of data, ideally across different locations, which reduces the risk of data loss.
- Strong consistency. Keeping multiple replicas of data improves reliability, but it may also lead to inconsistencies among the copies. It is unacceptable that you have copy A storing a user’s bank balance of 10 dollars while the information stored in copy B reads 20 dollars. Consistency algorithms for distributed systems are designed to solve this problem, such as the Raft protocol.
- High availability. In a distributed system, node failures are one of the most common problems, so resilience and tolerance to such failures are essential. A highly available system must be able to recover automatically from disasters without impacting downstream business.
- High performance. The messaging system needs to handle large amounts of data in high throughput scenarios.
There are many message queuing and streaming systems available, but few of them can meet the above four requirements at the same time. For example, RabbitMQ, a mature traditional messaging system, provides excellent reliability, strong consistency, and high availability, but it cannot guarantee high performance; Kafka, a distributed event streaming platform, provides great performance and high availability, but it falls short in terms of high reliability and consistency in financial scenarios. Although you can use Kafka for these cases by tweaking configurations, its entire performance can decline sharply with higher latency.
The basic ability required for a messaging platform is pub/sub messaging. At its core, the pub/sub model provides an asynchronous way for decoupled components of a system to receive messages. Now, let’s take a closer look at the breakdown of the basic requirements for a messaging system in both queuing and streaming.
Queuing (Online Business)
- Flexible consumption. Online business scenarios require multiple consumers to work together to read messages for better performance. Ideally, the messaging platform should be able to provide different consumption modes. In addition, business applications should be able to scale as needed without being impacted by how messages are consumed.
- Exception handling. In case of consumer failures, the messaging system needs to be able to recover consumption at the offset where the previous consumer crashed. There should be a mechanism in place that allows the failed messages to be consumed again. For example, the messaging system can put failed messages into a retry queue. After the retry threshold is reached, the messages can go to a dead-letter queue. All these efforts contribute to the successful consumption of messages.
- Delayed or scheduled message delivery. In many use cases, you may not want your messages to be consumed immediately. For a monthly subscription service, for example, when a customer enters into a monthly agreement for the first time, a delayed message for the payment of the following month can be produced. You can use the message queue to trigger the actual payment.
- Transactions. The messaging platform should support atomic operations that ensure all messages are either consumed or rolled back. It needs to provide exactly-once semantics.
Streaming (Big Data)
- Ordering guarantees. For the vast majority of streaming use cases, ordering is necessary both on the producer side and the consumer side. For example, in change data capture (CDC) scenarios, database binlogs need to be streamed to the message queue.
- Rewinding. It is very important for consumers to be able to consume the same data repeatedly after it is persisted. With message rewinding, users are allowed to reset the offset so that consumers can reread specific historical data. This may happen in cases where a recomputation is needed as the original business logic is updated.
- Backlogs. If producers have published more messages than the consumers can process, unacknowledged messages can keep growing. This is not uncommon in production, and it is essential that the messaging system can keep a large number of backlogged messages. Preferably, it should support configurable backlog quotas to provide users with more flexibility.
One thing that I hope was not lost in this comparison between queuing and streaming is that some properties are relevant to both of them. In some queuing scenarios, for example, you may want to ensure ordered messages and adopt backlogs as well.
Operations and Maintenance
Whether an organization can successfully put a messaging system into production use is largely contingent on operators maintaining the platform. An operator-friendly system should provide key observability metrics, handly tools, and configurable policies for managing day-to-day operations. Specifically, the following are some key aspects to consider:
- Resource and security control. For operators, they want to know the level of control they can implement over a system before actually starting to use it. In terms of resources, the messaging system should support multi-tenancy and resource isolation. Operators need to have topic-level control over the traffic. In terms of security, the massaging system should support common authentication and authorization models, message encryption in transit and at rest, and topic-level access control policies.
- Querying. The messaging system should provide open APIs for its key information, such as topic statistics, backlogs, and message trajectories. This helps operators quickly diagnose problems.
- Monitoring. The messaging system should be able to provide key metrics out of the box, such as message production and consumption and resource utilization. In addition, they need to be forwarded to a monitoring and alerting platform for further analysis.
- Cloud-native architecture. A cloud-native messaging system is capable of elastic scaling and automatic failover and recovery without impacting the existing services.
Ecosystem
A messaging system communicating with various components is never about itself. Therefore, we also need to take a look at how other tools work with its underlying technology. For queuing, we focus on whether the system can support multiple protocols, such as HTTP, AMQP, and MQTT. For streaming, we need to consider whether the system can be natively integrated with the big data ecosystem; in addition, we have to evaluate data storage or synchronization performance, which is determined by how the system coordinates with popular storage solutions.
In the above sections, we focused on the requirements for a fully-featured messaging system to meet the needs of both queuing and streaming. In the next section, we will give a high-level view of the use cases of Apache Pulsar by introducing Pulsar’s unique architecture and key features.
What Is Apache Pulsar Used for?
Unification of Queuing and Streaming
Most organizations are using two separate messaging systems, RabbitMQ or RocketMQ for online business and Kafka for big data streaming. The reason for that is these systems cannot meet the needs of these two scenarios at the same time. This leads to additional cognitive and maintenance overhead for organizations.
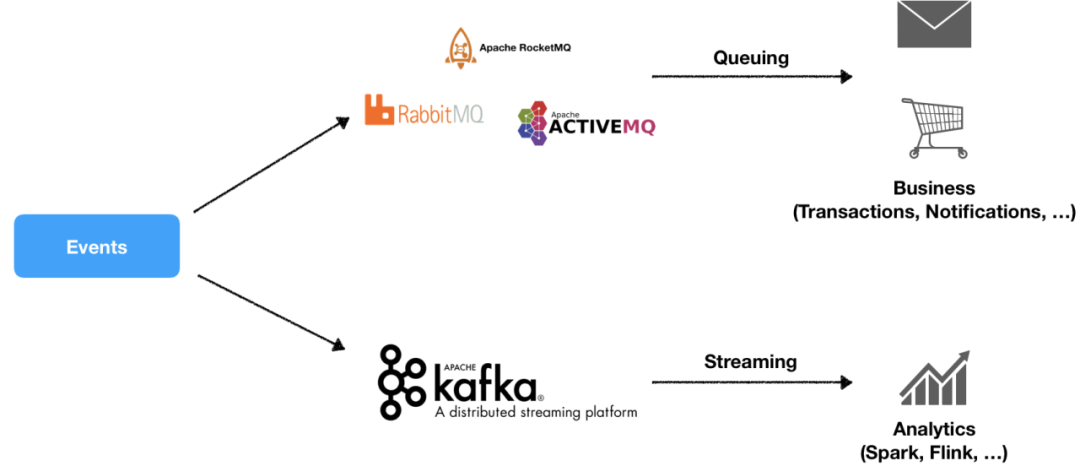
Apache Pulsar combines traditional queuing with streaming. Its storage layer, powered by Apache BookKeeper, provides stable IO performance, featuring strong consistency, read-write separation, high performance, and flexible SLAs. As storage is separated from computing, users can independently scale Pulsar brokers and BookKeeper bookies, which is a perfect solution to some of the pain points in Kafka (for example, data rebalancing).
An excellent example of using Pulsar for both scenarios is Midas, an internal billing platform at Tencent. Tencent built a message bus on top of Pulsar for its billing service, which handles tens of billions of messages per day. It covers core transaction flows, real-time reconciliation, and real-time monitoring.
Real-Time Data Warehouse
As organizations work to exploit the value of real-time data, they are building their own real-time data warehouses. The warehousing technology provides the ability to continuously process the data so that other systems can use it for different purposes. For example, when a new product is launched, operators can make informed data-driven strategies as the warehouse dynamically updates. For better visualization, they can even use a centralized dashboard to monitor all the real-time metrics about the product.
Pulsar provides a connector framework with Pulsar IO, which allows users to use Pulsar topics as input for real-time data from other systems. In the Pulsar ecosystem, there are plenty of Source Connectors that support data integration with Pulsar, such as the Pulsar Flink Connector. Furthermore, Pulsar has an abstract, flexible protocol layer with a protocol handler plugin that supports popular protocols, such as Kafka, MQTT, and AMQP. This means that users of these messaging platforms can easily migrate their applications to Pulsar.
Another helpful feature offered by Pulsar is tiered storage, which allows you to offload data of less immediate value to cheaper external systems, such as HDFS and Amazon S3. The data stored externally and those stored in BookKeeper can be used together for a centralized storage view with a unified API. By working with Flink, Pulsar integrates batch computing with stream computing, making it easier for users to build a real-time data warehouse.
BIGO, one of the fastest-growing technology companies providing live streaming services, built a real-time data warehouse on top of Pulsar and Flink. Their warehouse processes hundreds of billions of messages per day, powering real-time metrics computing, model training, and real-time A/B tests, among others.
In big data scenarios, organizations may have both real-time and offline data warehouses (the latter are frequently used for Hive-based data analysis). Currently, it is difficult for us to use a unified solution for storing data from both types of warehouses. The Apache Pulsar community is working on Pulsar’s integration with the data lake ecosystem. With Pulsar’s tiered storage, users can migrate data outside of BookKeeper and store them in a format supported by data lake systems. This will provide Pulsar users with better flexibility as they use tools in the data lake ecosystem or the wider big data ecosystem.
Internet of Things (IoT)
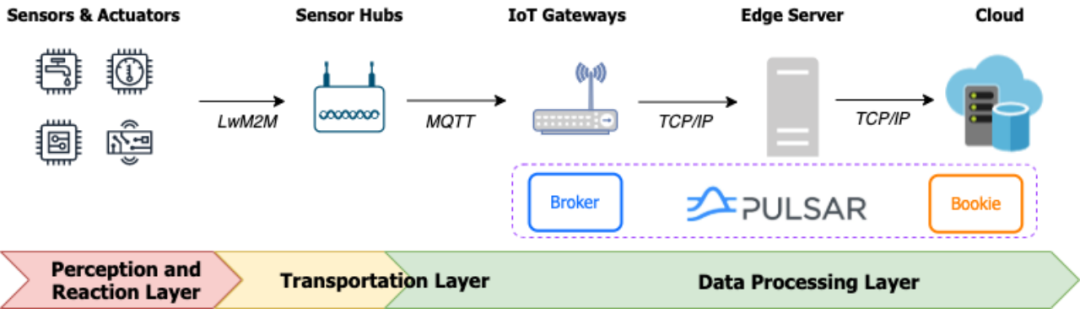
According to a report by IoT Analytics, the IoT market is expected to expand by 18% to 14.4 billion active connections in 2022. It is estimated that there will be about 27 billion connected IoT devices by 2025. These figures speak volumes about the need for high-performance and low-latency data pipelines, which should support sequential consumption and integration with numerous devices. These properties are essential to IoT and edge computing.
In this respect, Pulsar has a built-in runtime for stream processing, also known as Pulsar Functions, which are very useful for data processing in edge scenarios. ActorCloud, an open-source IoT platform launched by EMQ, used Pulsar Functions to implement its data processing management engine.
Others
Apache Pulsar also has other practical features, including:
- Geo-replication. Organizations can create geo-replication policies to prepare for disaster recovery scenarios. With either synchronous replication or asynchronous replication, you can replicate cluster data across regions to ensure availability and reliability. Different replication patterns, such as Aggregation and Standy, are available for a slew of big data use cases.
- Pulsar Functions. We briefly mentioned Pulsar Functions above, while it is a powerful stream processing system that deserves its own blog posts. Pulsar Functions provide lightweight capabilities for routing and converting data. For example, you can create functions that use a topic as an input and another as an output. It is suitable for simple ETL scenarios.
- Multi-tenancy. Pulsar has a built-in multi-tenancy mechanism that allows you to set tenants, namespaces, and topics. As such, you can allocate resources to them as needed without worrying about them impacting one another. You can also set data expiry and retention policies at different levels for better data management throughout their lifecycle.
Note that there is a considerable amount to cover on Pulsar, and fitting them all in this blog is impossible.
Conclusion
Any technology is designed to solve real-world problems. Apache Pulsar, as the first messaging system with a storage-compute separation architecture, has helped organizations to meet their business needs in scenarios where other alternatives fall short. If you are looking for a messaging solution for your organization, Pulsar may be a good choice.
Opinions expressed by DZone contributors are their own.
Comments