How to Put a Database in Kubernetes
Learn the key steps of deploying databases and stateful workloads in Kubernetes and meet cloud-native technologies that can streamline Apache Cassandra for K8s.
Join the DZone community and get the full member experience.
Join For Free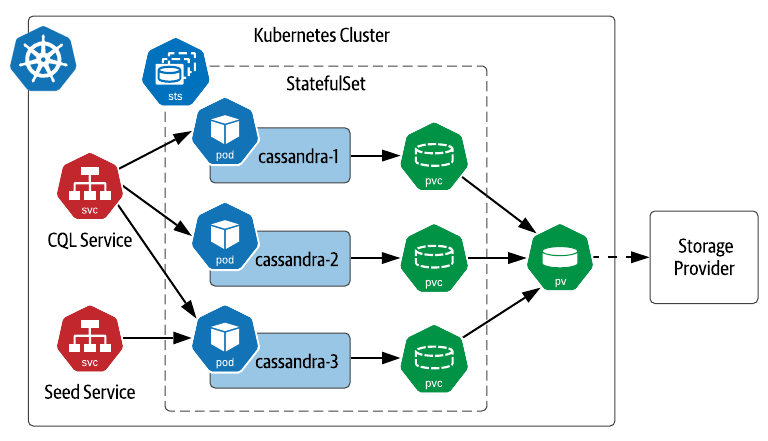
The idea of running a stateful workload in Kubernetes (K8s) can be intimidating, especially if you haven’t done it before. How do you deploy a database? Where is the actual storage? How is the storage mapped to the database or the application using it?
At KubeCon North America 2021, I gave a talk on “How to put a database in Kubernetes” where I demystified the deployment of databases and stateful workloads in K8s. Basically, it boils down to a few key steps:
- Get to know the Kubernetes primitives
- Pick a database
- Pick a storage provider
- Pick an operator
This blog post dives into the key steps of deploying databases and stateful workloads in K8s. In addition to my talk, you can learn more about these steps in the upcoming O’Reilly book, Managing Cloud Native Data on Kubernetes.
Get to Know the Kubernetes Primitives
Simply put: databases are just applications composed of compute, network, and storage. We can deploy them like any other K8s application and take advantage of resources that they provide: StatefulSets, Services, StorageClasses, PersistentVolumes, and PersistentVolumeClaims, and more.
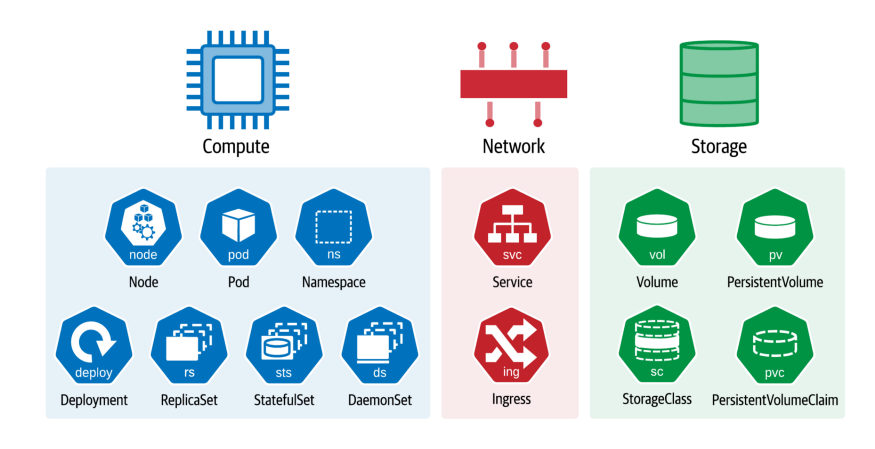
Figure 1: Kubernetes resources help us think of applications in terms of compute, network, and storage.
Getting comfortable with using these primitives will help you understand how databases and other data infrastructure are deployed on K8s. For example, a deployment of Apache Cassandra® will typically use a StatefulSet to launch pods across available Kubernetes worker nodes, with each Cassandra pod having its own PersistentVolumeClaim that can be preserved and reused if the pod needs to be replaced.
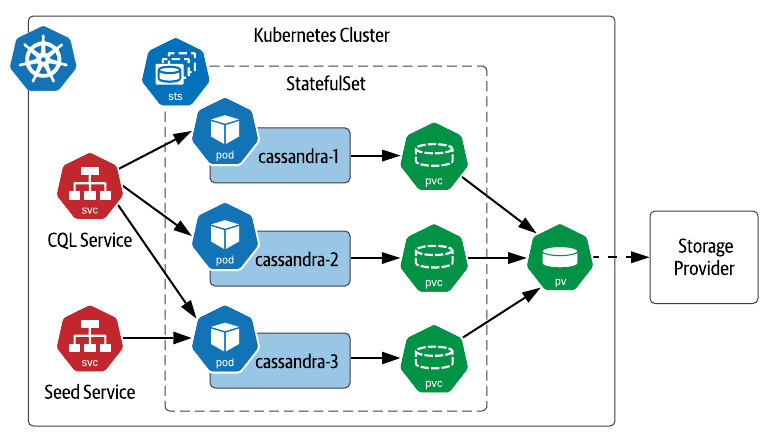
Figure 2: Simple deployment of Cassandra on Kubernetes using a StatefulSet.
For more great examples of using these primitives online, check the reference example in the Kubernetes documentation of deploying Cassandra using StatefulSets. We’re also building a collection of examples on GitHub in association with the book project and would love to see your issues and pull requests.
Once you’ve familiarized yourself with the basic building blocks of Kubernetes, there are three main considerations when setting up the right database for your application.
Pick a Database
To start, you’ll want to think about what kind of database your application needs. To help you make the right choice, consider the following factors:
- Database language: Does your application need SQL, NoSQL, developer-friendly data APIs?
- Capacity, performance, and scalability requirements: Will your data fit on a single node, or will you need a distributed database that can scale as your application grows?
- Deployment topology: Will your application be running in on-premises data centers, public clouds, or a mix of both?
Deciding on a database isn’t entirely independent from other decisions in your application design, and we’ll see more of this below. Note that your needs may also change as your application evolves.
Pick a Storage Provider
Unless the database you choose is just a cache holding ephemeral data, you’ll need to configure your database to use persistent storage. If you’re using one of the public clouds, you’ll have storage options available such as Elastic Block Storage (EBS) volumes in AWS.
However, there are many other options that are cloud-vendor independent. You can find a thriving ecosystem of K8s providers in the Cloud-Native Storage category of the CNCF Landscape.
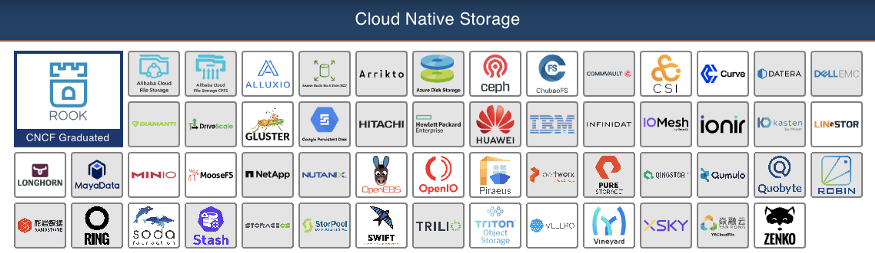
Figure 3: Cloud Native Storage projects on the CNCF Landscape as of September 2021.
These include a number of options for managing both local and networked storage, in formats such as block, file, and object storage. You’ll likely be able to find sample code that shows how to configure your selected database to use your chosen storage provider. For example, here’s a tutorial on running Apache Cassandra on OpenEBS, a popular open-source storage provider for K8s that you can run in a variety of environments.
Pick an Operator
If you intend on running more than a small handful of nodes of your selected database, you’ll benefit from automating your operations by using a K8s Operator. You can find a wide variety of operators for databases and other applications at the OperatorHub. When selecting an operator, you’ll want to make sure it’s open-source, and also check how actively it’s maintained.
There are operators for most popular databases, such as the Zalando Postgres-operator, or Cass-operator, which the Apache Cassandra community has recently banded around. Cass-operator is actually part of a larger project called K8ssandra, which builds on that operator to create a more comprehensive data platform around Cassandra. This includes tooling for maintenance and backups, along with an open-source data gateway called Stargate that supports a variety of developer-friendly APIs.
An Alternate Approach: Pick a Managed Service
Of course, even with an operator, running a database in K8s yourself may be more than you want to take on, especially if you’re a smaller team looking to maximize your leverage.
If this is you, you can still take advantage of one of the many managed database services available. If you need a highly scalable database combined with a great developer experience, DataStax Astra DB is one choice with a free tier. Astra DB is a managed Cassandra service that itself happens to be built on top of Kubernetes, and the Stargate APIs are available by default.
Meet a Community of Cloud-Native Data Practitioners
No matter what choices you end up making for your K8s-deployed applications, you can find a group of passionate developers pushing the state of the art forward in the Data on Kubernetes Community (DoKC).
Resources
Published at DZone with permission of Jeffrey Carpenter. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments