How to Read a PDF File in Apache JMeter
In this article, I'll show you how to download and read a PDF file in Apache JMeter by simply creating custom requests.
Join the DZone community and get the full member experience.
Join For FreeFirst, you need to understand how the application is designed (i.e. how the PDFs are getting loaded to the page). In most cases, PDFs load within iframe tags. But each request will generate unique PDFs. You need to capture which request generates the PDF in the page. This can be done using Fiddler or Developer Tools from the browser. I always use Google Developer Tools or IE Developer Tools.
Open the developer console in your browser and repeat the business actions. In my case, I saw one POST request which sent the session ID, auth ID, and some unique data. Its response was a PDF output. But, when I recorded it in JMeter, this particular request was not recorded.
Hence, I created a custom sampler in Apache JMeter and sent the data as generated in the developer tool. At last, I got the output below. By default, PDFs response will look like this.
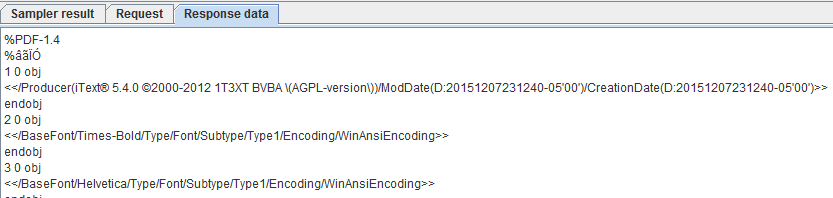
PDF Output
It is not in a readable format. To download the whole PDF, you need to add the elements below to your test plan.
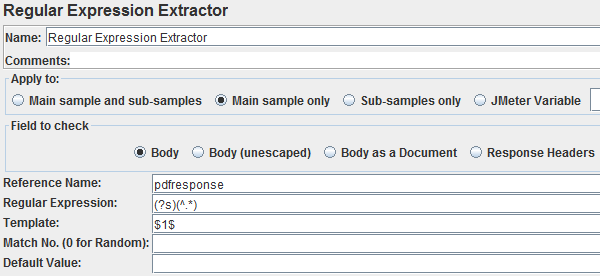
- Regular Expression Extractor is used to extract the complete response of the PDF. Use the following regular expression (?s)<^.*) which saves the complete response and save it to the variable pdfresponse:
2. Save Responses to a file which saves the complete response as a file.
Now configure Save Responses to a file as shown below which will save the PDF to your JMETER_HOME\bin folder:
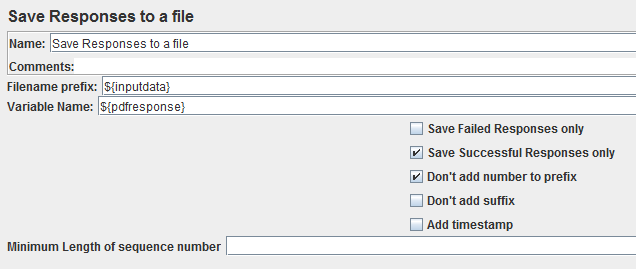
Save Responses to a file
To read/parse contents from the document, you need to download the jar file from following URL http://www.apache.org/dyn/closer.cgi/tika/tika-app-1.11.jar.
Published at DZone with permission of NaveenKumar Namachivayam. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments