How We Implemented Object Storage to Power an Image Management Service
Rethumb uses DreamObjects to handle vast amounts of image data reliably and with low latency. This article shows the technical aspects behind how it was developed.
Join the DZone community and get the full member experience.
Join For FreeTasks such as resizing images and performing other basic image manipulations call out for automation. However, in developing such a solution, we found that a highly scalable, fast-access data storage system would be essential. The end result, rethumb, uses DreamObjects to handle the vast amounts of image data involved, reliably and with low latency.
This article will show the technical aspects behind how rethumb was developed.
Rethumb allows users to create thumbnails, resize images, and get EXIF data from photos. This is done through automated processes using an HTTP API called from an HTML image tag, an HTTP client, or via any programming language a developer is using. Architecturally, rethumb uses Nginx for receiving API requests, PHP for processing, and DreamObjects (DreamHost’s object storage service) to store the images afterward – as well as MySQL for a database to keep track of the state and location of each image. We selected DreamObjects, finding it to be developer-friendly and a good fit for what we needed for a few reasons. It could handle any scale of data that we might reach a need for, it uses an API compatible with Amazon S3 for which mature PHP libraries are easily available, and it doesn’t include extra costs for basic operations like PUT and GET (which would otherwise really add up).
DreamObjects is an object storage system, where files are stored as objects and placed into buckets. On the surface, it appears somewhat like an FTP system, but with some important differences – and perhaps the most important is that there aren’t directories. Rather, buckets exist in a common space, objects have unique URLs, and buckets are part of those URLs.
In rethumb’s case, the service uses a single bucket, and each image is stored with a unique hash as a filename that is used for internal identification. For example, a URL like http://api.rethumb.com/v1/square/100/http://site.com/image.png could be stored as a2f5de456. Creating these hashes from the original request URLs makes looking up previously processed images very quick. This also, according to the DreamHost engineer who told us so when discussing intensive usage of files in buckets, helps maintain the health of the bucket. To give an idea of the scale we’re talking about, rethumb has around 30 million images and adds one or two million new images each month, and the requests for processed images are an order of magnitude higher.
Going with object storage is especially important to rethumb because it allows us to scale the system horizontally. This is a main feature in our infrastructure. With this service, we can add new machines to our setup without having to worry about syncing disks. All of the processed images must be stored somewhere, and it’s preferable to store them where every node of our network has access. We also see potential in using the object storage system as a backup storage for our database snapshots, having done some successful testing with Duplicity.
To upload files into DreamObjects, we use its REST API and libraries supporting Amazon S3. The DreamObjects RADOS S3 API uses RGW, a RADOS Gateway built on Ceph, and supports most essential Amazon S3 functions (certainly all that we need to store images for rethumb).
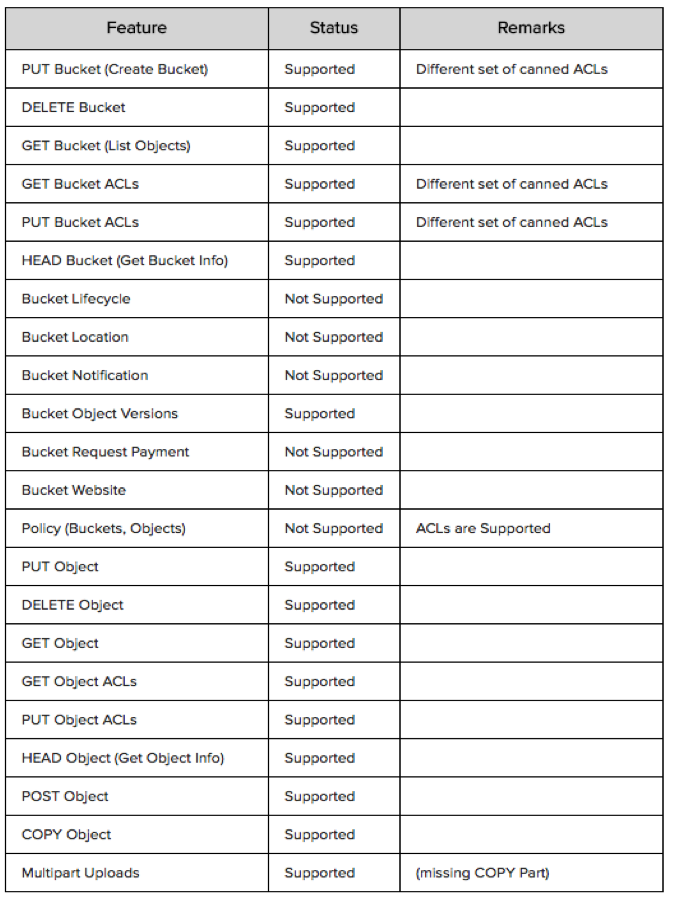
This API has two separate methods for accessing buckets, one that identifies a bucket as the top-level directory in the URL and another that identifies the bucket using a virtual bucket hostname, which requires domain certification and DNS wildcards to use. Because of this, rethumb uses the first method.
 Requests made to DreamObjects through the S3 API can be authenticated or unauthenticated (in which case DreamObjects considers the user anonymous). With rethumb, we use these methods to separate users by functionality and serve their various needs as is appropriate. Our users connecting to DreamObjects each have a standard key or secret pair. Users are separated into three different segments: those with standard read or write access, those able to perform backups, and those with access to perform maintenance operations.
Requests made to DreamObjects through the S3 API can be authenticated or unauthenticated (in which case DreamObjects considers the user anonymous). With rethumb, we use these methods to separate users by functionality and serve their various needs as is appropriate. Our users connecting to DreamObjects each have a standard key or secret pair. Users are separated into three different segments: those with standard read or write access, those able to perform backups, and those with access to perform maintenance operations.
The process flow of storing a rethumb image in DreamObjects is simple. First, a client (browser, curl, custom script, etc.) makes a new request to process an image. Then, rethumb checks the database to see if the image is already processed. If it is, rethumb tries to get it from a local disk cache. If it isn't available in the cache, rethumb requests it from DreamObjects and sends it to the client. The system then keeps a copy in a local cache for a few days.
If the request is a new one and the image is not yet processed, rethumb creates a job and sends it to a queue. One of the many workers in the system picks up that job, processes the image, and stores the result in DreamObjects. If the client is still waiting, rethumb sends it the processed image.
In this way, we can add front-end servers and workers without having to pass images between them and have established a fail-safe storage system for all of our clients’ images. Just as information such as text, numbers, and dates can be centralized in a database, rethumb uses DreamObjects to centralize images.
Here is a simple example of how rethumb uses DreamObjects in PHP. Two functions are displayed, one to get images and one to put them where they need to go:

All in all, we’ve found this development strategy gives us a simple-to-use API that can also deliver a powerful result as far as achieving fast and reliable object storage.
Opinions expressed by DZone contributors are their own.
Comments