HTTP Throttling Using Lyft Global Ratelimiting
Join the DZone community and get the full member experience.
Join For FreeSometime ago, for a project of mine, I was looking for a good rate-limiting service. For the scope of that project, the service would run along a front proxy and would rate-limit requests to third-party applications.
Nginx Plus and Kong certainly have rate-limiting features but are not OSS; while I am a bigger fan of OSS. Using Istio service mesh would have been a overkill. Therefore, I decided to use Envoy Proxy + Lyft Ratelimiting.
The aim for this blog is help you get started with the rate-limiting service and configure various combinations of rate-limiting scenarios.
Let’s dive in…
Understanding Lyft Ratelimiter
Ratelimit configuration consists of
- Domain: A domain is a container for a set of rate limits. All domains known to the Ratelimit service must be globally unique. They serve as a way for different teams/projects to have rate limit configurations that don’t conflict.
- Descriptor: A descriptor is a list of key/value pairs owned by a domain that the Ratelimit service uses to select the correct rate limit. Descriptors are case-sensitive. Examples of descriptors are:
(“database”, “users”)(“message_type”, “marketing”),(“to_number”,”2061234567")(“to_cluster”, “service_a”)(“to_cluster”, “service_a”),(“from_cluster”, “service_b”)
Descriptors can also be nested to achieve more complex rate-limiting scenarios.
We will be performing rate limiting based on various HTTP headers. Let’s have a look at the configuration file.
xxxxxxxxxx
domain: apis
descriptors:
- key: generic_key
value: global
rate_limit:
unit: second
requests_per_unit: 60
- key: generic_key
value: local
rate_limit:
unit: second
requests_per_unit: 50
- key: header_match
value: "123"
rate_limit:
unit: second
requests_per_unit: 40
- key: header_match
value: "456"
rate_limit:
unit: second
requests_per_unit: 30
- key: header_match
value: post
rate_limit:
unit: second
requests_per_unit: 20
- key: header_match
value: get
rate_limit:
unit: second
requests_per_unit: 10
- key: header_match
value: path
rate_limit:
unit: second
requests_per_unit: 5
#Using nested descriptors
- key: custom_header
descriptors:
- key: plan
value: BASIC
rate_limit:
requests_per_unit: 2
unit: second
- key: plan
value: PLUS
rate_limit:
requests_per_unit: 3
unit: second
In the configuration above, it can be clearly seen
- There are various different keys with different ratelimit values.
- We can use them globally for the entire vhost in envoy or even locally for a particular path.
- We can also have nested values of descriptors.
Envoy Front Proxy
Let’s see how we can use them in the envoy config now. Have a look at the configuration below:
xxxxxxxxxx
static_resources:
listeners:
- name: listener_0
address:
socket_address:
address: 0.0.0.0
port_value: 10000
filter_chains:
- filters:
- name: envoy.http_connection_manager
config:
stat_prefix: ingress_http
codec_type: AUTO
route_config:
name: local_route
virtual_hosts:
- name: nginx
domains:
- "*"
rate_limits:
- stage: 0
actions:
- generic_key:
descriptor_value: "global"
routes:
- match:
prefix: "/nginx_1"
route:
cluster: nginx_1
include_vh_rate_limits: true
rate_limits:
- actions:
- generic_key:
descriptor_value: "local"
- actions:
- header_value_match:
descriptor_value: "get"
headers:
- name: ":method"
prefix_match: "GET"
- actions: #This will be triggered if `X-CustomHeader` is present AND the X-CustomPlan header has a value of either BASIC or PLUS
- requestHeaders:
descriptor_key: "custom_header"
header_name: "X-CustomHeader"
- requestHeaders:
descriptor_key: "plan"
header_name: "X-CustomPlan"
- match:
prefix: "/nginx_2"
route:
cluster: nginx_2
include_vh_rate_limits: true
rate_limits:
- actions:
- generic_key:
descriptor_value: "local"
- actions:
- header_value_match:
descriptor_value: "123"
headers:
- name: "X-MyHeader"
prefix_match: "123"
- actions:
- header_value_match:
descriptor_value: "456"
headers:
- name: "X-MyHeader"
prefix_match: "456"
- actions:
- header_value_match:
descriptor_value: "post"
headers:
- name: ":method"
prefix_match: "POST"
- actions:
- header_value_match:
descriptor_value: "path"
headers:
- name: ":path"
prefix_match: "/nginx"
http_filters:
- name: envoy.rate_limit
config:
domain: apis
failure_mode_deny: false
rate_limit_service:
grpc_service:
envoy_grpc:
cluster_name: rate_limit_cluster
timeout: 0.25s
- name: envoy.router
clusters:
- name: nginx_1
connect_timeout: 1s
type: strict_dns
lb_policy: round_robin
hosts:
- socket_address:
address: nginx1
port_value: 80
- name: nginx_2
connect_timeout: 1s
type: strict_dns
lb_policy: round_robin
hosts:
- socket_address:
address: nginx2
port_value: 80
- name: rate_limit_cluster
type: strict_dns
connect_timeout: 0.25s
lb_policy: round_robin
http2_protocol_options: {}
hosts:
- socket_address:
address: ratelimit
port_value: 8081
admin:
access_log_path: "/dev/null"
address:
socket_address:
address: 0.0.0.0
port_value: 9901
Here's is how it works:
- We have defined a single vhost named nginx which matches all domains.
- There is global rate-limit defined for this vhost. The descriptor value is global.
- Next, we have 2 clusters under this vhost. Namely, nginx1 and nginx2. Routes for path /nginx1 are routed to nginx1 cluster and similarly for nginx2.
- For nginx1, there is generic rate limit defined by descriptor value local and then we have rate-limits for different values of standard HTTP headers such as method, path etc., and some custom HTTP headers such as X-CustomHeader.
- We have similar rate-limiting set for nginx2 cluster.
- These 2 nginx clusters defined here actually refer to 2 different nginx containers running as part of docker-compose stack.
The overall architecture can be visualized as:
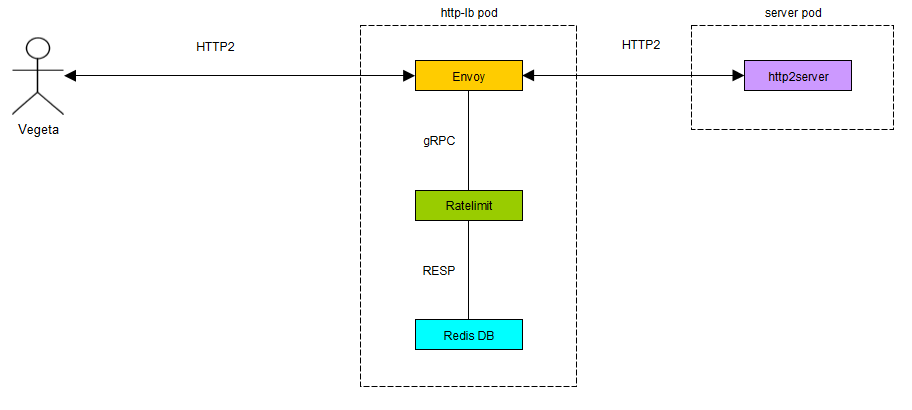
All configuration files for this set-up can be found here. Since they are running on the same network as the ratelimiter and envoy proxy, they can be accessed easily using the container name.
In order to run the set-up just clone the repo and do
xxxxxxxxxx
docker-compose up
Once the stack is up, you will have
- 2 nginx containers running on port
9090and9091of localhost. - Envoy proxy to intercept and relay requests to nginx servers. Envoy admin console can be reached at
localhost:9901. - Envoy will be listening as
localhost:10000. - Ratelimiting service container with configured rate limits which will be used to envoy.
- Redis container which is used by the Ratelimiting service.
It is important to understand that all the applicable actions for a particular path in a cluster are aggregated by the ratelimiter for the result i.e.,
Logical OR of all the applicable limits
Let’s Test Our Setup
Firstly we need to install Vegeta, a load testing framework. It can be done by
xxxxxxxxxx
brew update && brew install vegeta
Test Scenario 1:
Case: GET request on /nginx_1/ at 100 requests per second
Expected Result: 10% requests successful. ( Logical OR of "descriptor_value": "global" , "descriptor_value": "local" and "descriptor_value": "get" )
Command: echo "GET http://localhost:10000/nginx_1/" | vegeta attack -rate=100 -duration=0 | vegeta report
Actual Result
xxxxxxxxxx
$ echo "GET http://localhost:10000/nginx_1/" | vegeta attack -rate=100 -duration=0 | vegeta report
Requests [total, rate, throughput] 1008, 100.12, 10.92
Duration [total, attack, wait] 10.071526192s, 10.06832056s, 3.205632ms
Latencies [mean, 50, 95, 99, max] 4.718253ms, 4.514212ms, 7.426103ms, 9.089064ms, 17.916071ms Bytes In [total, mean] 68640, 68.10
Bytes Out [total, mean] 0, 0.00
Success [ratio] 10.91%
Status Codes [code:count] 200:110 429:898
Error Set: 429 Too Many Requests
— — —
Test Scenario 2:
Case:POST request on /nginx_1/ at 100 requests per second.
ExpectedResult: 50% requests successful. ( Logical OR of "descriptor_value": "global" and "descriptor_value": "local" )
Command: echo "POST http://localhost:10000/nginx_1/" | vegeta attack -rate=100 -duration=0 | vegeta report
ActualResult:
xxxxxxxxxx
$ echo “POST http://localhost:10000/nginx_1/" | vegeta attack -rate=100 -duration=0 | vegeta report
Requests [total, rate, throughput] 4344, 100.02, 50.56
Duration [total, attack, wait] 43.434227783s, 43.429286664s, 4.941119ms
Latencies [mean, 50, 95, 99, max] 5.190485ms, 5.224978ms, 7.862512ms, 10.340628ms, 20.573212ms
Bytes In [total, mean] 1370304, 315.45
Bytes Out [total, mean] 0, 0.00
Success [ratio] 50.55%
Status Codes [code:count] 200:2196 429:2148
Error Set: 429 Too Many Requests
— — —
Test Scenario 3:
Case: GET request on /nginx_2/ at 100 requests per second with X-MyHeader: 123
Expected Result: 5% requests successful ( Logical OR of "descriptor_value": "global", "descriptor_value": "local", "descriptor_value": "123", and "descriptor_value": "path")
Command: echo "GET http://localhost:10000/nginx_2/" | vegeta attack -rate=100 -duration=0 -header "X-MyHeader: 123" | vegeta report
Actual Result:
xxxxxxxxxx
$ echo "GET http://localhost:10000/nginx_2/" | vegeta attack -rate=100 -duration=0 -header "X-MyHeader: 123" | vegeta report
Requests [total, rate, throughput] 3861, 100.03, 5.18
Duration [total, attack, wait] 38.604406747s, 38.597776398s, 6.630349ms
Latencies [mean, 50, 95, 99, max] 4.96685ms, 4.673049ms, 7.683458ms, 9.713522ms, 16.875025ms Bytes In [total, mean] 124800, 32.32
Bytes Out [total, mean] 0, 0.00
Success [ratio] 5.18%
Status Codes [code:count] 200:200 429:3661
Error Set: 429 Too Many Requests
— — —
Test Scenario 4:
Case: POST request on /nginx_2/ at 100 requests per second with X-MyHeader: 456
Expected Result: 5% requests successful ( Logical OR of "descriptor_value": "global", "descriptor_value": "local", "descriptor_value": "post", "descriptor_value": "456", and "descriptor_value": "path")
Command: echo "POST http://localhost:10000/nginx_2/" | vegeta attack -rate=100 -duration=0 -header "X-MyHeader: 456" | vegeta report
Actual Result:
xxxxxxxxxx
$ echo “POST http://localhost:10000/nginx_2/" | vegeta attack -rate=100 -duration=0 -header “X-MyHeader: 456” | vegeta report
Requests [total, rate, throughput] 2435, 100.04, 5.13
Duration [total, attack, wait] 24.346703709s, 24.339554311s, 7.149398ms
Latencies [mean, 50, 95, 99, max] 5.513994ms, 5.255698ms, 8.239173ms, 10.390515ms, 20.287931ms
Bytes In [total, mean] 78000, 32.03
Bytes Out [total, mean] 0, 0.00
Success [ratio] 5.13%
Status Codes [code:count] 200:125 429:2310
Error Set: 429 Too Many Requests
— — —
Test Scenario 5:
Case: GET request on /nginx_1/ at 100 requests per second with X-CustomHeader: XYZ and X-CustomPlan: PLUS
Expected Result: 3% requests successful ( Logical OR of "descriptor_value": "global", "descriptor_value": "local", "descriptor_value": "get", "descriptor_key": "custom_header", and "descriptor_key": "plan")
Command: echo "GET http://localhost:10000/nginx_1/" | vegeta attack -rate=100 -duration=0 -header "X-CustomHeader: XYZ" -header "X-CustomPlan: PLUS" | vegeta report
Actual Result:
xxxxxxxxxx
$ echo “GET http://localhost:10000/nginx_1/" | vegeta attack -rate=100 -duration=0 -header “X-CustomHeader: XYZ” -header “X-CustomPlan: PLUS” | vegeta report
Requests [total, rate, throughput] 2372, 100.05, 3.16
Duration [total, attack, wait] 23.71156424s, 23.707710415s, 3.853825ms Latencies [mean, 50, 95, 99, max] 5.396743ms, 5.179951ms, 7.981171ms, 10.084753ms, 15.086778ms
Bytes In [total, mean] 46800, 19.73
Bytes Out [total, mean] 0, 0.00
Success [ratio] 3.16%
Status Codes [code:count] 200:75 429:2297
Error Set: 429 Too Many Requests
— — —
Test Scenario 6:
Case: GET request on /nginx_1/ at 100 requests per second with X-Header: XYZ and X-CustomPlan: PLUS
Expected Result: 10% requests successful ( Logical OR of "descriptor_value": "global", "descriptor_value": "local", "descriptor_value": "get")
Command: echo "GET http://localhost:10000/nginx_1/" | vegeta attack -rate=100 -duration=0 -header "X-Header: XYZ" -header "X-CustomPlan: PLUS" | vegeta report
Actual Result:
xxxxxxxxxx
$ echo “GET http://localhost:10000/nginx_1/" | vegeta attack -rate=100 -duration=0 -header “X-Header: XYZ” -header “X-CustomPlan: PLUS” | vegeta report
Requests [total, rate, throughput] 1578, 100.07, 10.78
Duration [total, attack, wait] 15.773500478s, 15.769158977s, 4.341501ms
Latencies [mean, 50, 95, 99, max] 4.748516ms, 4.514902ms, 7.076671ms, 8.518779ms, 16.077828ms
Bytes In [total, mean] 106080, 67.22
Bytes Out [total, mean] 0, 0.00
Success [ratio] 10.77%
Status Codes [code:count] 200:170 429:1408
Error Set: 429 Too Many Requests
Scalability
In a production scenario, you might want to run multiple instances of your proxy which can refer to the same ratelimit cluster. The front proxy is basically stateless.
As far as the ratelimiting service is concerned, I would recommend scaling it horizontally and moving out Redis Cache to a cloud-based service like RedisLabs or AWS Elastic-cache.
Also, using separate Redis for Per Second Limits is highly recommended. All you need to do is:
- Set the env var,
REDIS_PERSECOND:"true" - Set Redis endpoint,
REDIS_PERSECOND_URL
Conclusion
We can clearly see that the actual results are pretty close to expected results. We can accomplish all kinds of complex rate limiting scenarios using this and perform request throttling. Feel free to reach out should you have any questions around this.
Published at DZone with permission of Sudip Sengupta. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments