IBM App Connect Enterprise CI Builds With On-Demand Service Provisioning
This article explores the challenges faced by CI pipelines for integration applications and how they can be helped by the use of on-demand service provisioning.
Join the DZone community and get the full member experience.
Join For FreeThe industry-wide move to continuous integration (CI) build, and test presents a challenge for the integration world due to the number and variety of resource dependencies involved, such as databases, MQ-based services, REST endpoints, etc. While it is quite common to automate testing using dedicated services (a “test” or “staging” database, for example), the fixed number of these services limits the number of builds that can be tested and therefore limits the agility of integration development.
Containerization provides a way to increase CI build scalability without compromising quality by allowing a database to be created for each run and then deleted again after testing is complete. This does not require the integration solution to be deployed into containers in production and is compatible with deploying to integration nodes: only the CI pipeline needs to be able to use containers and only for dependent services.
Quick summary: Start a containerized database, configure ACE policy, and run tests; a working example can be found at ot4i.
Background
Integration flows often interact with multiple external services such as databases, MQ queue managers, etc., and testing the flows has historically required live services to be available. This article is focused on databases, but other services follow the same pattern.
A common pattern in integration development relies on development staff building applications and doing some level of testing locally, followed by checking the resulting source into a source-code management system (git, SVN, etc.). The source is built into a BAR file in a build pipeline and then deployed to an integration node for further testing, followed by promotion to the next stage, etc. While the names and quantity of the stages differ between different organizations, the overall picture looks something like this:
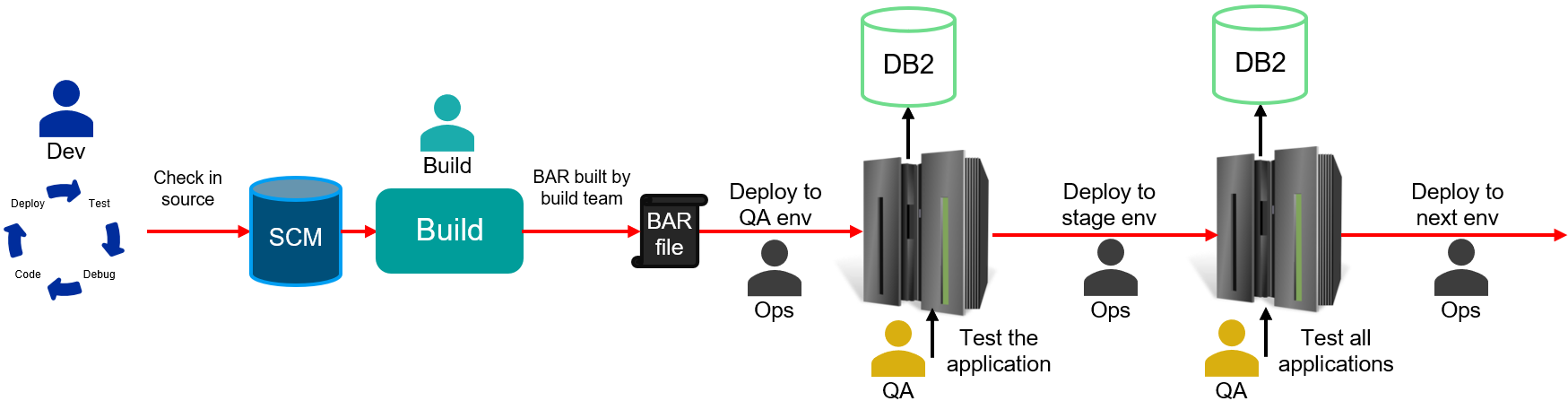
This style of deployment pipeline allows organizations to ensure their applications behave as expected and interact with other services correctly but does not usually allow for changes to be delivered both quickly and safely. The key bottlenecks tend to be in the test stages of the pipeline, with build times as a less-common source of delays. While it is possible to speed up delivery by cutting back on testing (risky) or adding large numbers of QA staff (expensive), the industry has tended towards a different solution: continuous integration (CI) builds with finer-grained testing at earlier stages to catch errors quickly.
With a CI pipeline enabled and automated finer-grained testing added, the picture changes to ensure more defects are found early on. QA and the other stages are still essential, but these stages do not see the same level of simple coding bugs and merge failures that might have been seen with the earlier pipelines; such bugs should be found in earlier stages, leaving the QA teams able to focus on the more complex scenarios and performance testing that might be harder to achieve in earlier stages.
A simple CI pipeline (which could be Jenkins, Tekton, or many other tools) might look something like this:
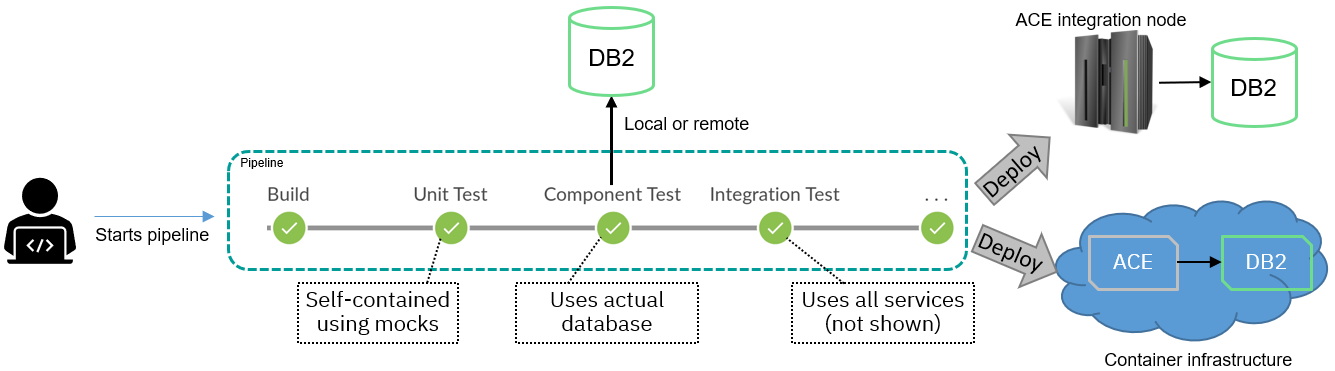
Note that (as discussed above) there would usually be environments to the right of the pipeline, such as staging or pre-prod, that are not shown in order to keep the diagram simple. The target of the pipeline could be containers or integration nodes, with both shown in the diagram; the DB2 database used by the pipeline could also be in either infrastructure.
The pipeline steps labeled “Unit Test” and “Integration Test” are self-explanatory (with the services used by integration testing not shown), but “Component Test” is more unusual. The term “component test” was used in the ACE product development pipeline to mean “unit tests that use external services” and is distinct from integration testing because component tests only focus on one service. See ACE unit and component tests for a discussion of the difference between test styles in integration.
This pipeline benefits from being able to shift testing “left,” with more testing being automated and running faster: the use of ACE v12 test capabilities (see JUnit support for flow testing for details) allows developers to run the tests on their own laptops from the toolkit as well as the tests being run automatically in the pipeline, and this can dramatically reduce the time required to validate new or modified code. This approach is widely used in other languages and systems, relying heavily on unit testing to achieve better outcomes, and can also be used in integration. This includes the use of component tests to verify interactions with services, resulting in the creation of large numbers of quick-to-run tests to cover all the required use cases.
However, while shifting left is an improvement, it is still limited by the availability of live services to call during the tests. As development agility becomes more important and the frequency of build/test cycles becomes greater due to mandatory security updates as well as code changes, the need to further speed up testing becomes more pressing. While it is possible to do this while still using pre-provisioned infrastructure (for example, creating a larger fixed set of databases to be used in testing), there are still limits on how much testing can be performed at one time: providing enough services for all tests to be run in parallel might be theoretically possible but cost-prohibitive, and the next section describes a cheaper solution.
On-Demand Database Provisioning
While the Wikipedia article on shift-left testing says the “transition to traditional shift-left testing has largely been completed,” this does not appear to be true in the integration world (and is debatable in the rest of the industry). As the point of a lot of integration flows is to connect systems together, the availability of these systems for test purposes is a limiting factor in how far testing can be shifted left in practice.
Fortunately, it is possible to run many services in containers, and these services can then be created on-demand for a pipeline run. Using a DB2 database as an example, the pipeline picture above would now look as follows:
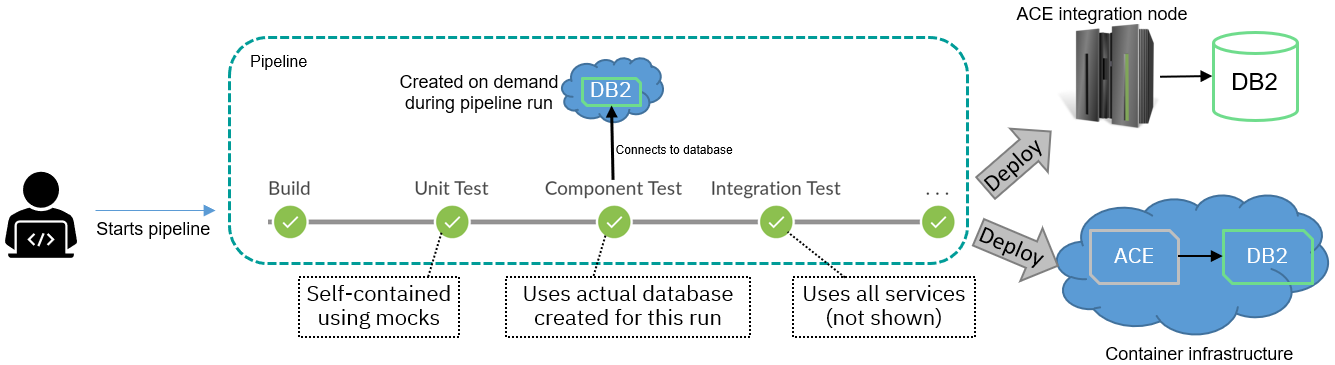
This pipeline differs from the previous picture in that it now includes creating a database container for use by tests. This requires the database to be set up (schemas, tables, etc. created) either during the test or in advance, but once the scripts and container images are in place, then the result can be scaled without the need for database administrators to create dedicated resources. Note the target could still be either integration nodes or containers.
Creating a new database container every time means that there will never be data left in tables from previous runs, nor any interference from other tests being run by other pipeline runs at the same time; the tests will be completely isolated from each other in both space and time. Access credentials can also be single-use, and multiple databases can be created if needed for different tests that need greater isolation (including integration testing).
While isolation may not seem to be relevant if the tests do nothing, but trigger reads from a database, the benefits become apparent when inserting new data into the database: a new database will always be in a clean state when testing starts, and so there is no need to keep track of entries to clean up after testing is complete. This is especially helpful when the flow code under test is faulty and inserts incorrect data or otherwise misbehaves, as (hopefully) tests will fail, and the whole database (including the garbage data) will be deleted at the end of the run. While it might be possible to run cleanup scripts with persistent databases to address these problems, temporary databases eliminate the issue entirely (along with the effort required to write and maintain cleanup scripts).
More Test Possibilities
Temporary databases combined with component testing also make new styles of testing feasible, especially in the error-handling area. It can be quite complicated to trigger the creation of invalid database table contents from external interfaces (the outer layers of the solution will hopefully refuse to accept the data in most cases), and yet the lower levels of code (common libraries or sub-flows) should be written to handle error situations where the database contains unexpected data (which could come from code bugs in other projects unrelated to integration). Writing a targeted component test to drive the lower level of code using a temporary database with invalid data (either pre-populated or created by the test code) allows error-handling code to be validated automatically in an isolated way.
Isolated component testing of this sort lowers the overall cost of a solution over time: without automated error testing, the alternatives tend to be either manually testing the code once and then hoping it carries on working (fast but risky) or else having to spend a lot of developer time inspecting code and conducting thought experiments (“what happens if this happens and then that happens?”) before changing any of the code (slow but safer). Targeted testing with on-demand service provision allows solution development to be faster and safer simultaneously.
The underlying technology that allows both faster and safer development is containerization and the resulting ease with which databases and other services can be instantiated when running tests. This does not require Kubernetes, and in fact, almost any technology would work (docker, Windows containers, etc.) as containers are significantly simpler than VMs when it comes to on-demand service provision. Cloud providers can also offer on-demand databases, and those would also be an option as long as the startup time is acceptable; the only critical requirements are that the DB be dynamic and network-visible.
Startup Time Considerations
On-demand database containers clearly provide isolation, but what about the time taken to start the container? If it takes too long, then the pipeline might be slowed down rather than sped up and consume more resources (CPU, memory, disk, etc.) than before.
Several factors affect how long a startup will take and how much of a problem it is:
- The choice of database (DB2, Postgres, etc.) makes a lot of difference, with some database containers taking a few seconds to start while others take several minutes. This is not usually something that can be changed for existing applications, though for new use cases, it might be a factor in choosing. It is possible to test with a different type of database that is used in production, but this seriously limits the tests.
- The amount of setup needed (tables, stored procedures, etc.) to create a useful database once the database has started. This could be managed by the tests themselves in code, but normally it is better to use the existing database scripts responsible for creating production or test databases (especially if the database admins also do CI builds). Using real scripts helps ensure the database looks as it should, but also requires more work up-front before the tests can start.
- Available hardware resources can also make a big difference, especially if multiple databases are needed to isolate tests. This is also affected by the choice of database, as some databases are more resource-intensive than others.
- The number of tests to be run and how long they take affect how much the startup time actually matters. For a pipeline with ten minutes of database testing, a startup time of one minute is less problematic than it would be for a pipeline with only thirty seconds of testing.
Some of these issues can be mitigated with a small amount of effort: database container images can be built in advance and configured with the correct tables and then stored (using docker commit if needed) as a pre-configured image that will start more quickly during the pipeline runs. The database can also be started at the beginning of the pipeline so it has a chance to start while the compile and unit test phases are running; the example in the ACE demo pipeline repo (see below) does this with a DB2 container.
Limitations
While on-demand databases are useful for functional testing, performance testing is harder: database containers are likely to be sharing hardware resources with other containers, and IO may be unpredictable at times. Security may also be hard to validate, depending on the security configuration of the production databases. These styles of testing may be better left to later environments that use pre-provisioned resources, but the earlier pipeline stages should have found most of the functional coding errors before then.
To be most effective, on-demand provisioning requires scripts to create database objects. These may not always be available if the database has been built manually over time, though with the moves in the industry towards database CI, this should be less of a problem in the future.
Integration Node Deployments
Although the temporary database used for testing in the pipeline is best to run as a container, this does not mean that the pipeline must also end with deployment into container infrastructure such as Kubernetes. The goal of the earlier pipeline stages is to find errors in code and configuration as quickly as possible, and this can be achieved even if the application will be running in production in an integration node.
The later deployment environments (such as pre-prod) should match the production deployment topology as closely as possible, but better pipeline-based testing further left should mean that fewer bugs are found in the later environments: simpler code and configuration issues should be caught much earlier. This will enhance agility overall even if the production topology remains unchanged.
In fact, it is often better to improve the earlier pipeline stages first, as improved development efficiency can allow more time for work such as containerization.
Example of Dynamic Provisioning
The ACE demo pipeline on OT4i (google “ace demo pipeline”) has been extended to include the use of on-demand database provision. The demo pipeline uses Tekton to build, test, and deploy a database application (see description here), and the component tests can use a DB2 container during the pipeline run:
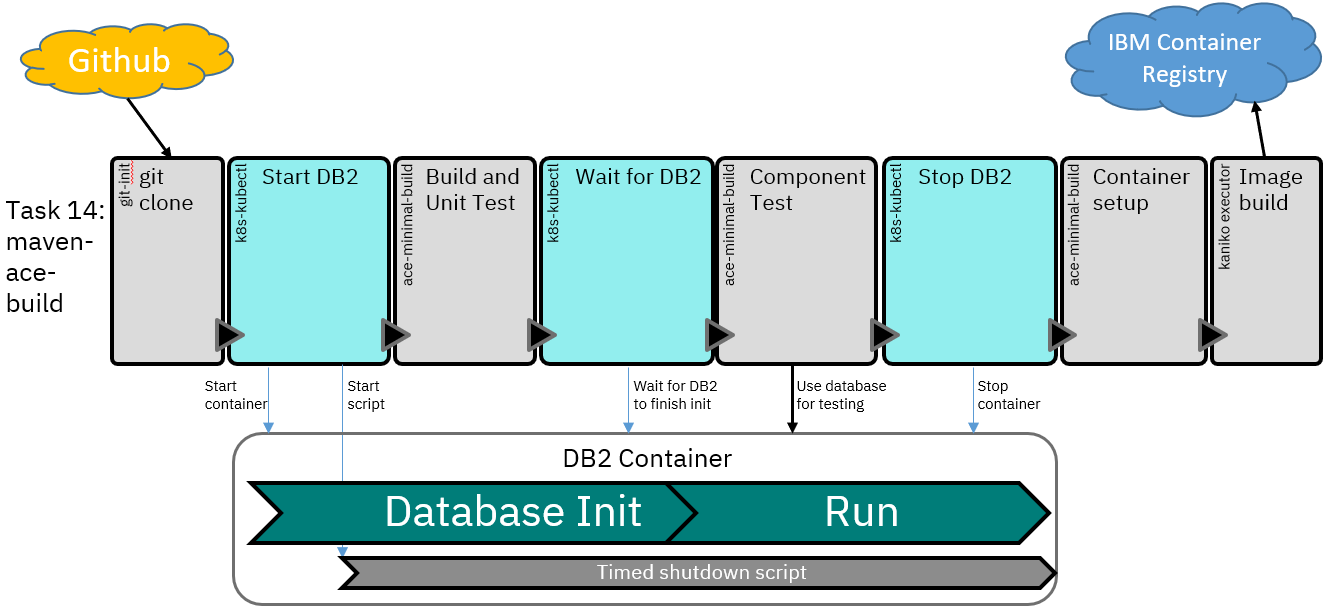
The pipeline uses the DB2 Community Edition as the database container (see DB2 docs) and can run the IBM-provided container due to not needing to set up database objects before running tests (tables are created by the tests). Due to the startup time for the container, the database is started in the background before the build and unit test step, and the pipeline will wait if needed, for the database to finish starting before running the component tests.
A shutdown script is started on a timer in the database container to ensure that it does not keep running if the pipeline is destroyed for any reason; this is less of a concern in a demo environment where resources are free (and limited!) but would be important in other environments.
Note that the DB2 Community Edition license is intended for development uses but still has all the capabilities of the production-licensed code (see DB2 docs here), and as such, is a good way to validate database code; other databases may require licenses (or be completely free to use).
Summary
CI pipelines for integration applications face challenges due to large numbers of service interactions, but these issues can be helped by the use of on-demand service provisioning. This is especially true when combined with targeted testing using component-level tests on subsections of a solution, allowing for faster and safer development cycles.
This approach is helped by the widespread availability of databases and other services in containers that can be used in pipelines without requiring a wholesale move to containers in production. Used appropriately, the resulting shift of testing to the left has the potential to help many integration organizations develop high-quality solutions with less effort, even without a wholesale move to containers in all environments.
Published at DZone with permission of Trevor Dolby. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments