IBM i Business Logic API With Mule
I walk through the process of exposing IBM i Business logic via APIs using Mulesoft Anypoint platform and Web Transaction Framework.
Join the DZone community and get the full member experience.
Join For FreeOverview
Unlocking IBM i Business logic and data is a priority for many companies. There is a number of IBM i (AS400, iSeries) tools and technologies that can be used to expose existing back-end programs as APIs. In this post, we will use the Mulesoft Anypoint integration platform and the info-view Web Transaction Framework to create a RESTful API that calls an RPG program. This is a continuation of the IBM i (AS400, iSeries) integration with Mulesoft Anypoint series. Previous articles can be found here:
IBM i Integration Use Cases
Building IBM i Data API With Mule
In the previous post, we created Mule API that retrieves IBM i Business data directly from DB2 for i Database. The approach works great for simple data structures and normalized models. In most legacy applications, however, the stored data must first be processed through a complex business logic, which is typically a part of the existing back-end system, i.e., an RPG program. API implementation must execute the business logic programs and handle the request and response data mapping.
Passing Request and Response Data
In general, the data passed to IBM i API or returned back can be quite complex and include variable size payloads. For example, an order typically has a header and a variable number of lines, payment options, taxes, special instructions, etc. IBM i programs typically work with a fixed number of input and output data elements. It’s possible to pass a reference to dynamic lists but it requires more effort and doesn’t support streaming for large data sets.
A more flexible approach is using the staging tables on IBM i:
- The Mule API parses JSON or XML request parameters and saves the request data into IBM i Staging, using a unique “transaction ID.”
- The Mule API calls IBM i Program, passing the transaction ID.
- The IBM i Program reads a request data from the staging table and executes business logic.
- The IBM i Program saves the response into IBM i Staging tables and notifies Mule when done.
- The Mule API retrieves the response data from staging tables and builds JSON or XML response.
The benefit of this approach is a clean separation of duties between IBM i and Mule applications. Mule handles HTTP, security, formatting to and from JSON and XML, schema validation, etc. IBM i Programs focus on executing business logic.
As all good things in life, this comes at a cost: extra I/O associated with persisting and retrieving the data. In the case of small fixed size payloads and high transaction volumes, the data can be passed directly via IBM i Program parameters.
Solution Design
The high-level design includes Mulesoft API that invokes IBM i Business logic program and exchanges the request and response data via Web Transaction Framework (WebTF) and staging DB2 for i Tables.
The flow diagram below explains the detailed steps and areas of responsibility for Mule and IBM i sides:
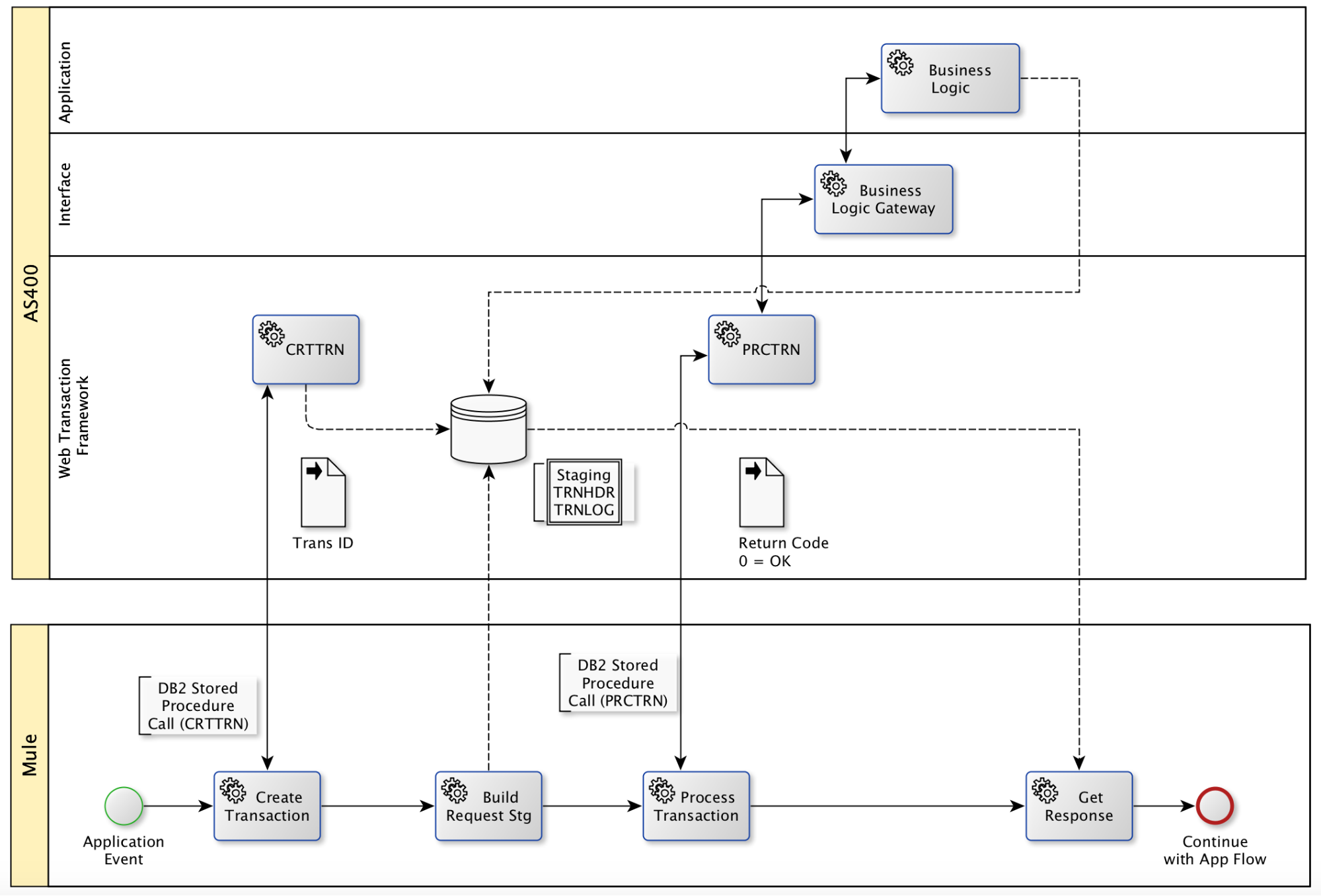
Implementation
Finally, let’s get to coding! As you will see, building an API that executes IBM i Business logic is pretty straightforward and includes the following steps:
- Mule: Create RAML API definition in API Designer or Anypoint Studio
- Mule: Generate implementation stubs from RAML in Anypoint Studio
- IBM i: Define new Web Transaction type and interface program
- IBM i: Optionally create staging tables for request and response
- Mule: Call WebTF stored procedure CRTTRN to create new transaction
- Mule: Optionally insert request data into DB2 staging table(s)
- Mule: Optionally call WebTF stored procedure PRCTRN to process transaction
- Mule: Optionally retrieve response data from DB2 staging tables
- Mule: Transform the response data into API response format
As discussed above, in the case of complex request and response structures, the data is exchanged via staging tables while simple payloads can be passed directly via Web Transaction Framework calls
Mule: RAML and Flow Stubs
For this example, we will use the same Product Price API RAML definition that we created for Data API post. Follow exactly the same steps as in Data API tutorial to create a new Mule project, define the IBM i Database connector, import the RAML API definition, and generate Mule flow stubs.
IBM i: Define WebTF Transaction and Staging Files
First, we need to decide whether to stage the request and response parameters or pass them via WebTF calls. Our RAML definition takes a single parameter productName and expects back a list of prices (regular, sales, etc.). We can easily pass a single parameter via WebTF call. However, we will need a staging table for the response, as we don’t know in advance how many price records can be returned.
Next, let's define WebTF transaction using CALL EDTTYPES command then pressing F6 to create new:
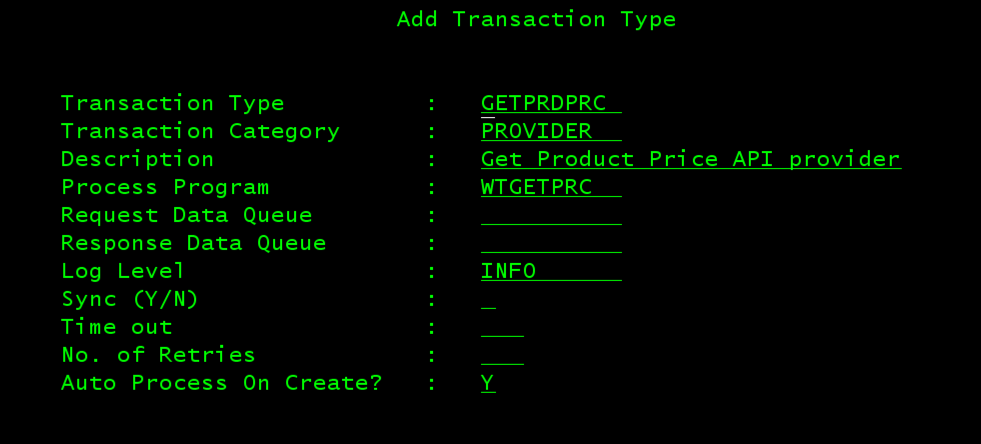
Note: since we don’t need to build request staging table, we set Auto Process on Create to Y. When Mule calls CRTTRN, it will create a new transaction, then immediately call the specified interface program WTGETPRC.
Next, let’s create the Response staging table:
--*CRT: RUNSQLSTM COMMIT(*NONE) ERRLVL(30) :*
set schema muledemos;
drop table wtgetprcr;
-- Response Staging
create table WTGETPRCR (
id bigint not null generated always as identity primary key,
transid bigint not null with default,
productID bigint not null with default,
productName char(30) not null with default,
priceGroup char(10) not null with default,
productPrice decimal(11,2) not null with default,
errorYN char(1) not null with default,
errorMsg char(254) not null with default);The processing program populates a staging file with product and pricing info as well as an error flag, tied to a specific transaction ID.
Next, we will create a WebTF processing program WTGETPRC that gets product name, calls “business logic” back-end program then saves the data to response staging table above.
For the purpose of this example, let's assume that we have an existing RPG program GETPRDPRC that retrieves a list of price groups and product prices for given product, or returns an error message if product not found. Below is a program definition:
d main pr extpgm('GETPRDPRC')
d productName 30a const
d productID 20i 0
d priceGroup 10a dim(100)
d productPrice 11s 5 dim(100)
d returnCd 3s 0
d returnMsg 254a WebTF implementation program WTGETPRC will call GETPRDPRC and save the response to the staging table.
We will use demo program DEMO02R that comes with WebTF distribution as a template for WTGETPRC. The program logic is very simple - call GETPRDPRC, then save the result to response staging table with current trans ID as a key. The interface program is just a simple wrapper around existing business logic program that handles the request / response data mapping and perhaps some basic translations, but delegates all heavy lifting to the existing programs:
/free
productName = %trim(reqData);
returnCd = *zeros;
getPrice(productName:productID:priceGroup:
productPrice:w#returnCd:w#returnMsg);
if returnCd < 0;
exec sql
insert into wtgetprcr (transid,productName,
errorYN, errorMsg)
values(:transID, :productName, 'Y', :w#returnMsg);
returnCd = w#returnCd;
else;
for i = 1 to 100;
if priceGroup(i) = *blanks;
leave;
endif;
w#pricegrp = pricegroup(i);
w#price = productPrice(i);
exec sql
insert into wtgetprcr (transid,productid, productName,
priceGroup, productPrice, errorYN)
values (:transID,:productid, :productName,
:w#priceGrp, :w#price, 'N');
endfor;
endif;
//*inlr = *on;
return;
/end-free After the program is created, we can quickly test it, something like:
monitor;
crttrn('GETPRDPRC':' ': 'TABLE' : transID : returnCd:returnMsg);
on-error;
dsply 'Program bombed!';
endmon;
if returnCd <> 0 ;
dsply 'Transaction Processing failed!';
endif;
*inlr = *on;
return;Mule: Call WebTF and Get the Response From Staging
Now that we defined and implemented WebTF transaction and interface program, we can easily call it from Mule then get back the results.
We already have the Mule project created with API definition and auto-generated stubs. Make sure jt400.jar (AS400 JDBC driver) is on the project Build path. For Maven projects, add the following dependency to pom.xml:
<dependency>
<groupId>net.sf.jt400</groupId>
<artifactId>jt400</artifactId>
<version>8.5</version>
</dependency>Add the Database connector to the flow get:/products/{productname} and define configuration similar to how it was done for Data API
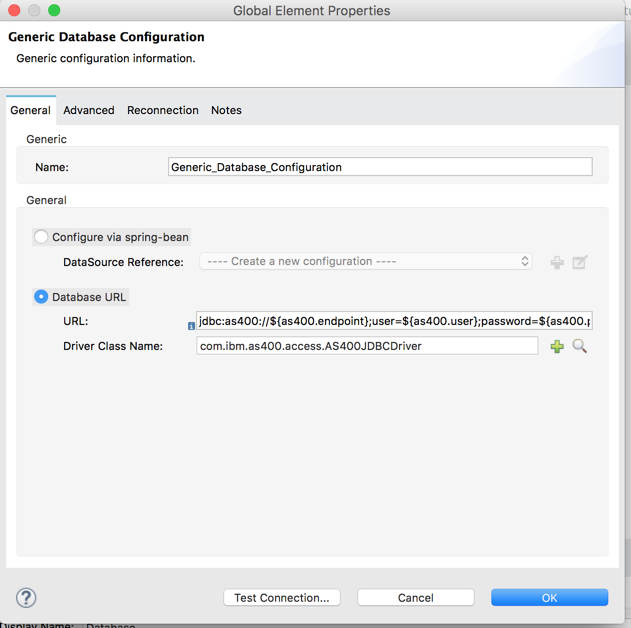
Note: the connection string may have to include the library list required for back-end logic execution, as well as WebTF library.
jdbc:as400://${as400.endpoint};user=${as400.user};password=${as400.password};libraries=${as400.libraries};naming=*systemBelow is an example of a library list definition. The leftmost library will be on top of the list.
as400.libraries=WEBTF,MULEDEMOS,*LIBLFor production configuration, make sure to set up connection pooling for the database, defining appropriate initial and max number of connections in the pool. Otherwise, Mule will open and close the connection every time a DB operation is performed. This can work well for development and testing, as the WebTF program is closed on IBM i side after each call, but affects the interface performance. When connection pooling is configured, the DB connections and the associated WebTF interface programs stay open between the calls, minimizing the start up and shut down overhead.
Back to Database processor, select operation Stored Procedure, set the parameterized query to:
CALL CRTTRN (:transType,:altTrnID,:reqData,:transID,:returnCd,:returnMsg)And add CRTTRN parameters as follows:

The output of the stored procedure call is a map of parameter name and value pairs.
Next, add another database processor right next to CRTTRN call to retrieve the response from the staging table. Set operation to Select and use the following query:
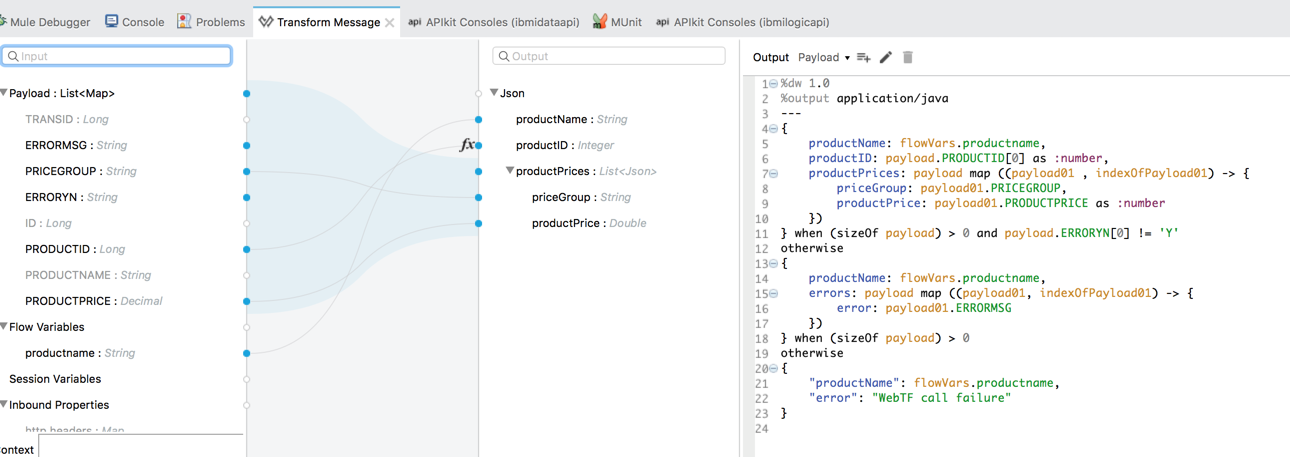
select * from WTGETPRCR where transid = #[payload.transID]Next, add Transform Message step, define the output format using sample JSON file exactly as we did for the Data API, then map the response to our target data structure:
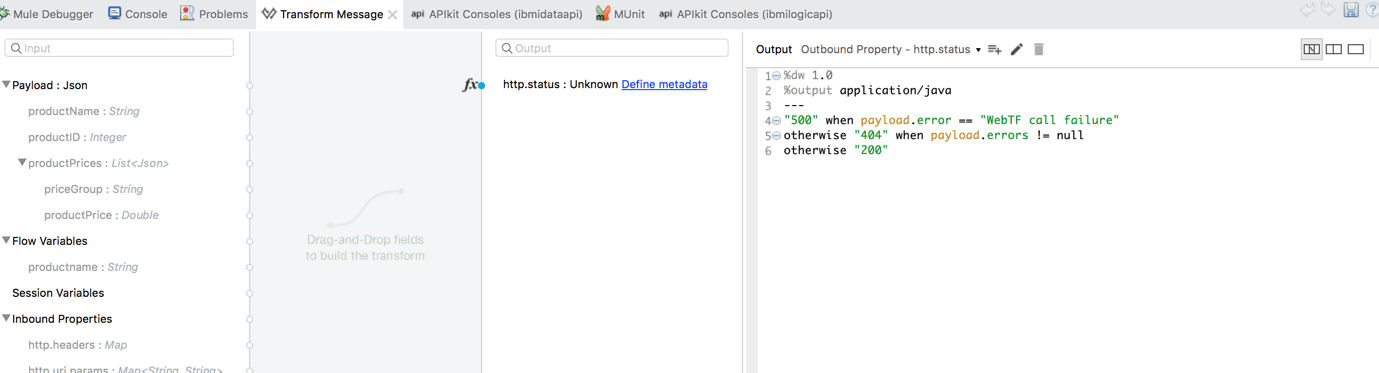
Next, drag another Transform Message processor to set the HTTP response code to 200 if no errors, 404 if there are any errors returned in the staging file, and 500 if there are no records at all in the staging file:
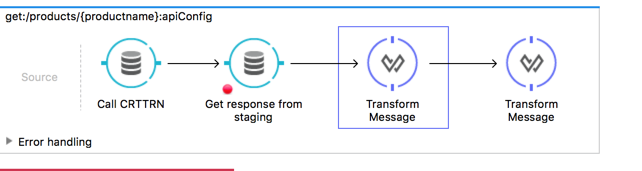
And that’s it. The resulting flow looks like this:
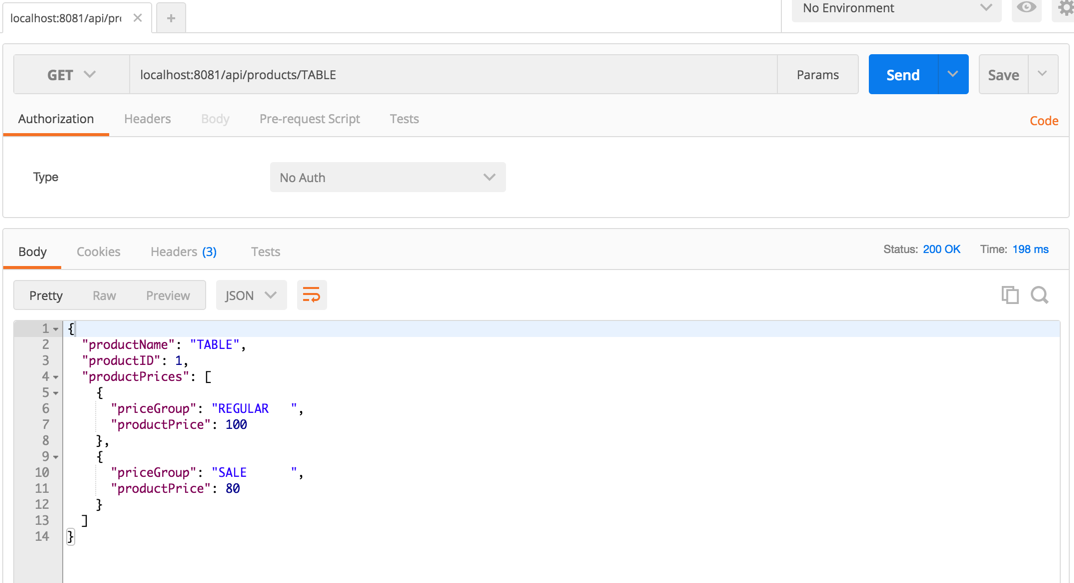
Set mule-app.properties and test the application with Postman or any other API client:
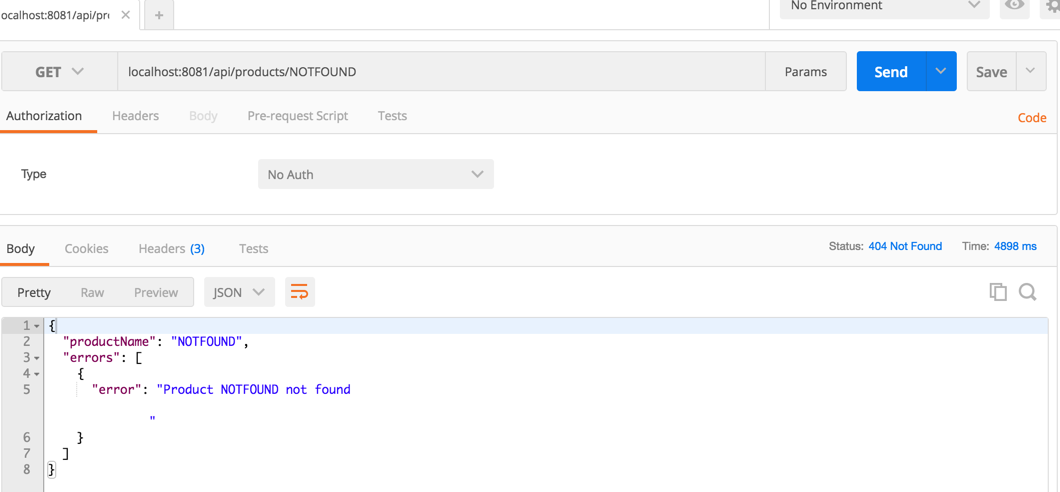
Try a product that’s not defined in our database:
Finally, we can check all transactions with their start / end timestamp, request parameter, and status, in WebTF table TRNHDR.

This operational data is very valuable and can used for alerting and monitoring directly on IBM i or better yet streamed to the event and log aggregation and alerting and monitoring tool, i.e., Splunk or ELK.
Conclusion
We walked through the process of exposing IBM i Business logic via APIs using Mulesoft Anypoint platform and Web Transaction Framework.
The Mule development is very straightforward and focuses on designing RAML API, calling WebTF stored procedure, working with staging tables for complex request and response structures, and transforming resultset to required JSON output. Anypoint platform provides great low code tools that greatly simplify these tasks even for beginner Mulesoft developer. Really, there’s nothing special IBM i skills needed here; just a regular API, database, and Data Weave development.
The IBM i part of development is also very simple and includes defining WebTF type, creating staging tables for complex request and response (if needed), and building simple WebTF processing programs that wrap calls to business logic and stage the response. WebTF provides unified structure for implementing and operating integration components, as well as demo code that can be used as a template for quickly creating new programs. There is nothing specific to Mule or external APIs here, and IBM i Development does not require any JSON or XML parsing or building or using any special tools or APIs. It’s just a regular database, data transformation, and program call operations that all IBM i developers are very comfortable with.
Separation of duties is a great concept and works very well in this example. Based on our team’s experience, it is very helpful when the dev team and individual developers and architects can address both Mule and IBM i sides, eliminating “lost in translation,” time lags, and many other issues. Investing in IBM i teams Mule training offers significant long-term return on investment. For the quick wins during initial implementation, consider partnering with cross-functional Mulesoft and IBM i team.
The code for this article can be found here.
Published at DZone with permission of Dmitriy Kuznetsov. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments