Intro to Yelp Web Scraping Using Python
The article is to help newbies to understand a web scraper, introducing its basic logic and a practical case, creating a Yelp crawler with Python and Octoparse.
Join the DZone community and get the full member experience.
Join For FreeOriginally published June 17, 2020
Like many programmers who hold degrees that are not even relevant to computer programming, I was struggling to learn coding by myself since 2019 in the hope to succeed in the job. As a self-taught developer, I’m more practical and goal-oriented about things that I’ve learned. This is why I like web scraping particularly, not only it has a wide variety of use cases such as product monitoring, social media monitoring, content aggregation, etc, but also it’s easy to pick up.
The essential idea of web scraping is to extract information snippets from the websites and export them into an easily readable format. If you’re a data-driven person, you will find great values in web scraping. Luckily, there are free web scraping tools available to capture web data automatically without coding.
The web context is more complex than we could imagine. Having said that, we need to put in the time and effort to maintain the scraping work, not to mention massive scraping from multiple websites. On the flip side, scraping tools save us from writing up codes and endlessly maintaining work.
To give you an idea of the pros and cons of python scraping and website scraping tools, I will walk you through the entire work of python. And then I will compare the process with a web scraping tool.
Let’s get started!
Web Scraping With Python
Project:
website: Yelp.com
Scraping content: business title, ratings, review counts, phone number, price range, address, neighborhood
You will find full coding here: https://github.com/whateversky/yelp
Prerequisite
Pycharm — for fast-checking and fixing the coding errors
The general scraping process will look like this:
First, we create a spider to define how we will perform and extract data from Yelp. In other words, we send GET requests, and then set rules for scrapers to crawl the website.
Then, we parse the web page content and return the dictionary with extracted data. Having said that, we tell the spider that it must return either an Item object or a Requested object.
Finally, export extracted data returned from the spider.
I only focus on the spider and parser. However, we certainly need to understand web structures before data extraction. While coding, you will also find yourself constantly inspecting the webpage all the time to access the divs and classes. To inspect the website, go to your favorite browser and right-click. Choose “Inspect” and find the “XHR” tab under the Network.
You will find corresponding listing information including store names, phone numbers, locations, and ratings. As we expand the “PaginationInfo”, it shows us that there are 30 listings on each page, and have a total number of 6932 listings. So by the end of this video, we should be able to get that many results. Now let’s head to the fun part:
Spider
First, open Pycharm and set up a new project. Then set up a python file, and name it “yelp_spider”
Getting Page:
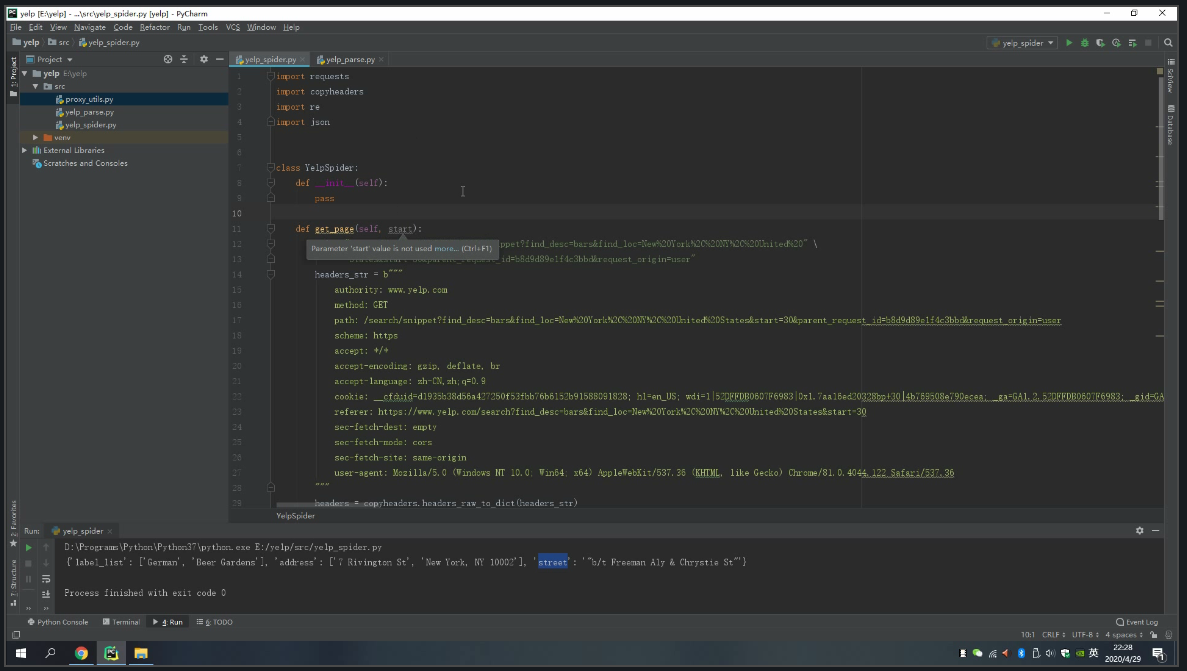
We create a get_page method. This will pass a query argument that contains all the listing web URLs and then returns the page JSON. Note that I also add a user-agent string to spoof the webserver to bypass any scraper detection. We can just copy and paste the Request Headers. It is not necessary but you will find it useful most of the time if you tend to scrape a website repeatedly.
I add .format argument to format the urls so it returns an endpoint follows a pattern, in this case, all the listing pages from search result of “Bar in New York city”
def get_page(self, start_number):
url = “https://www.yelp.com/search/snippet?find_desc=bars&find_loc=New%20York%2C%20NY%2C%20United%20States&start={}&parent_request_id=dfcaae5fb7b44685&request_origin=user” \ .format(start_number)
.format(start_number)
Getting Detail:
We just successfully in harvesting the urls to the listing pages, we can now tell the scraper to visit each detail page using the get_detail method.
The detail page URL consists of a domain name and a path that indicates the business.

As we already gathered the listing URLs, we can simply define the URL pattern which includes a path appended to https://www.yelp.com. This way it will return a list of detail page URLs
xxxxxxxxxx
def get_detail(self, url_suffix): url = “https://www.yelp.com/” + path
Next, we still need to add a header to make the scraper look more human. It’s similar to a common etiquette for us to knock before entering.
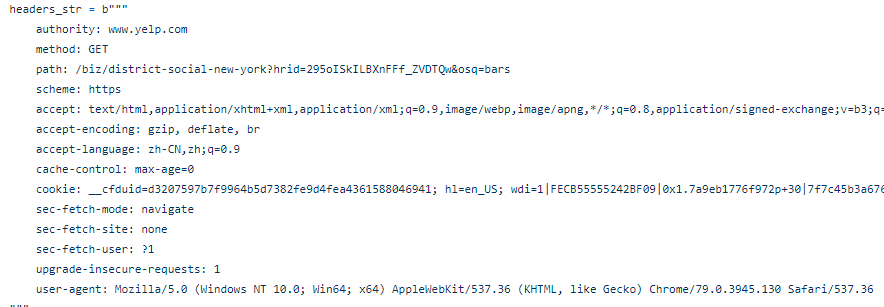
Then I created a FOR loop combined with IF statements to locate the tags that we are going to get. In this case, the tags that contain the business name, rating, review, phone, etc.
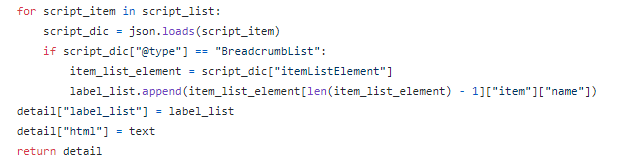
Unlike listing pages that will return JSON format, detail pages normally respond to us in HTML format. Therefore I strip away the punctuations and extra spaces to make them look clean and neat while parsing.
Parsing
As we visit those pages one by one, we can instruct our spider to obtain the detailed information by parsing the page.
First, create a second file called “yelp_parse.py” under the same folder. And start with import and execute YelpSpider.
Here I add a pagination loop since there are 30 listings split across multiple pages. The “start_number” is an offset value, which is “0” in this case. It increases numbers by 30 as we finish crawling the current page. In this manner, the logic will like this:
- Get first 30 listings
- Paginate
- Get 31-60 listings
- Paginate
- Get 61-90 listings….
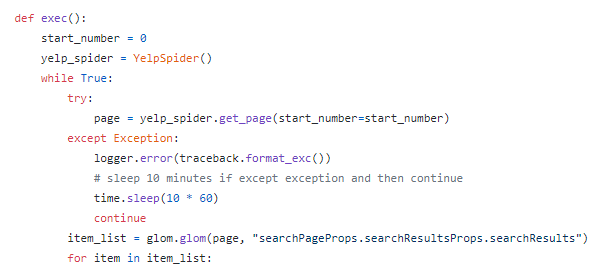
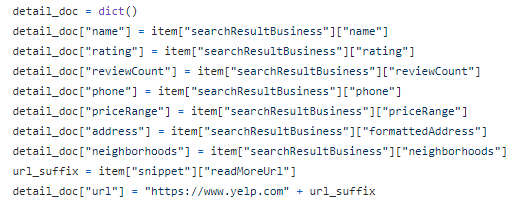
Last but not least, I create a dictionary to pair the key and values with respective data attributes including business name, rating, phone, price range, address, neighborhoods, and so forth.
Scraping with web scraping tool:
With python, we directly interact with the webserver, portals, and source code. Ideally, this method would be more effective but involves programming. As the website is so versatile, we need to constantly edit the scraper and adapt to the changes. So do the Selenium and the Puppeteer, they’re close relatives but come with limitations compared to Python for large-scale extraction.
On the other hand, web scraping tools are more friendly. Let’s take Octoparse as an example:
Octoparse’s latest version OP 8.1 applies the Train Algorithm which detects the data attributes when the web page gets loaded. If you ever experienced the iPhone’s face unlock which applies Artificial Intelligence, “detection” is not a strange term to you.
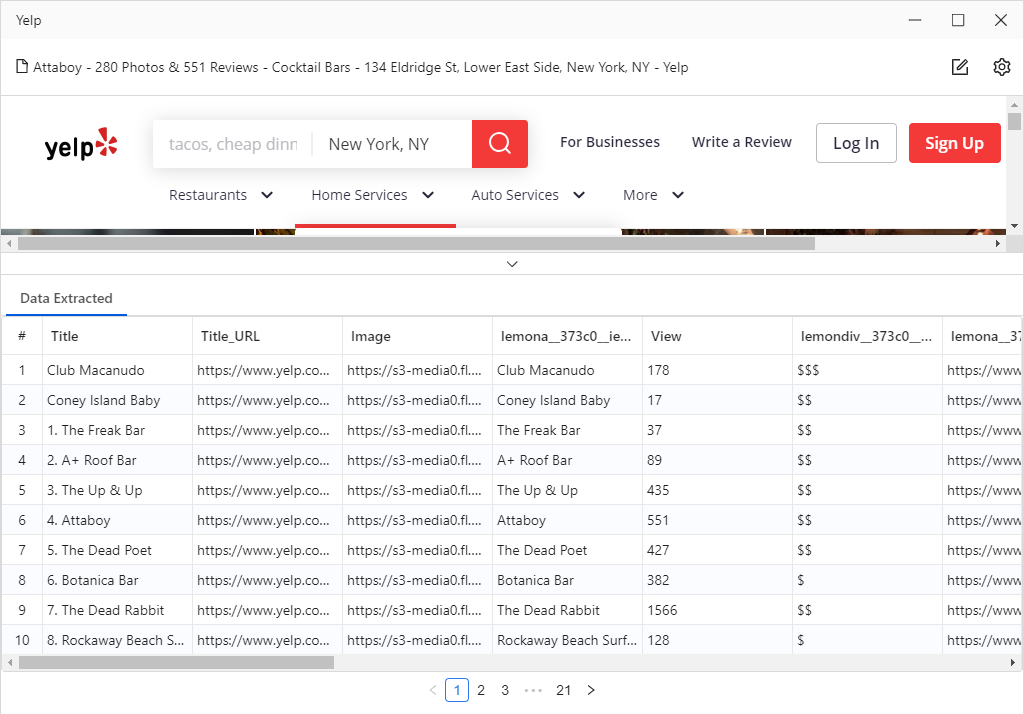
Likewise, Octoparse will automatically break down the web page and recognize various data attributes, for instance, business name, contacts information, reviews, locations, ratings, etc.
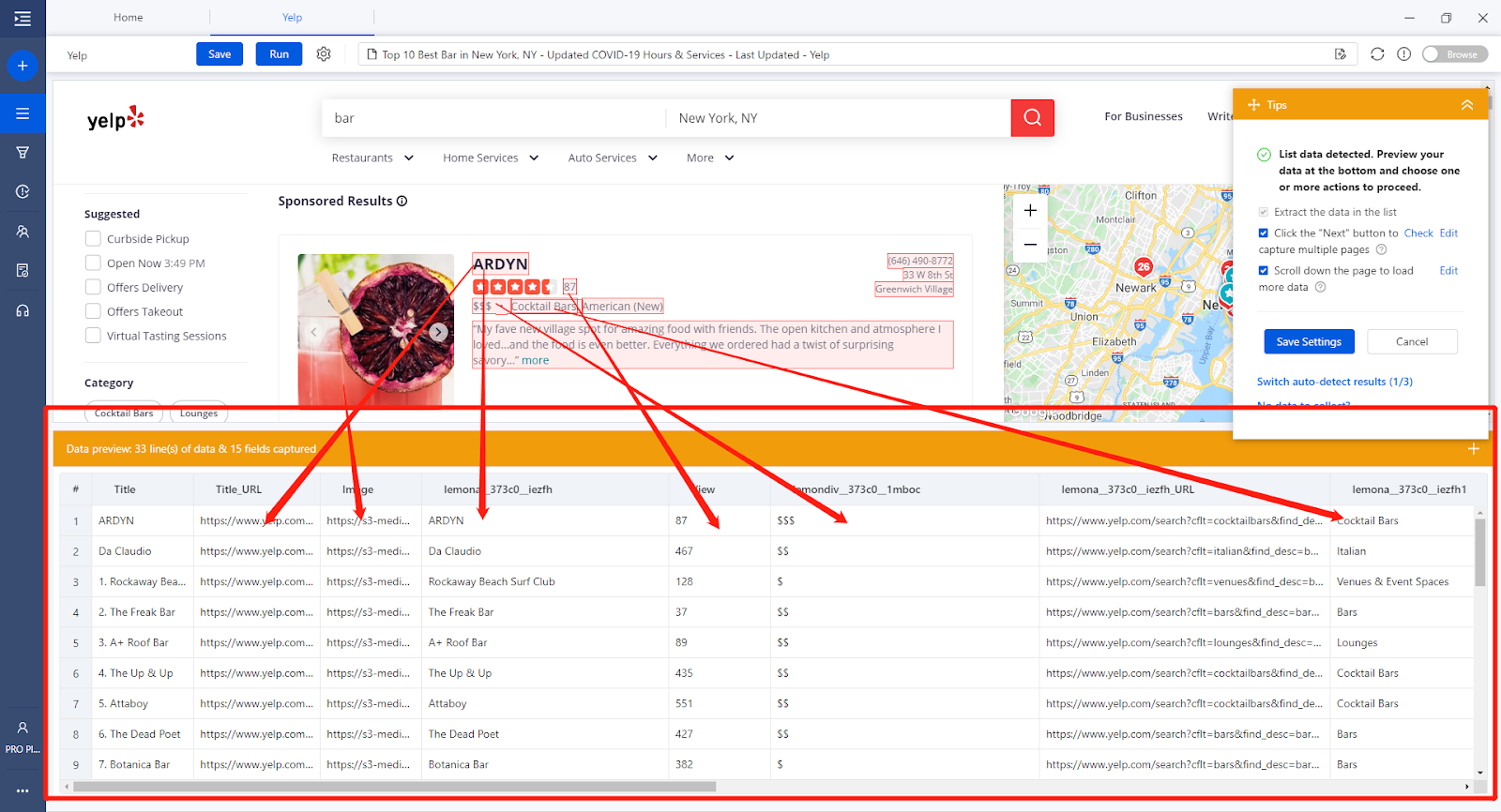
Take yelp as an example. Once the web page gets loaded, it parses the web element automatically and reads the data attributes automatically. Once the detection process gets done, we can see all the data that Octoparse captured for us from the preview section, nice and neat! Then You will notice the workflow has been created automatically. The workflow is like a scraping roadmap, and the scraper will follow the direction to capture the data.
We’ve created the same thing in the python section, but they were not visualized with clear statements and graphs like Octoparse. Programming is more logical and abstract which is not easy to conceptualize without a firm grounding in this field.
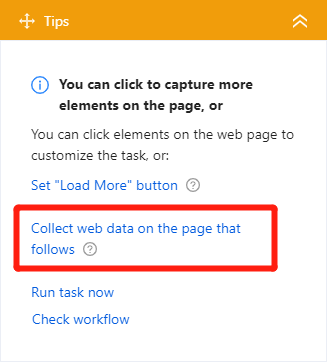
But that’s not all, we want to get information from detailed pages. It’s easy peasy. Just follow the guide from the tips panel and find “Collect web data on the page that follows”.
Then choose title_url which can bring us to the detail page.
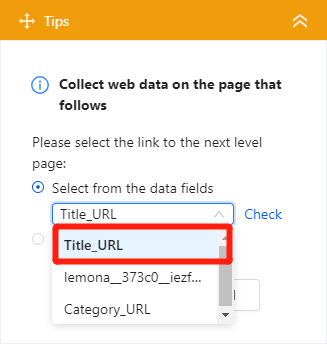
Once we confirm the step, a new step will add to the workflow automatically. Then the browser will display a detail page and we can click any data attribute within the page. For example, when we click the business title “ARDYN”, the tips guide will respond with a set of actions for us to choose from. Simply click the “Extract the text of the selected element” command, it will take care of the rest and add the action to the workflow. Similarly, repeat the above step to get “ratings”, “review counts”, “phone number”, “price range”, “address”.

Once we set all the things up, we can execute the scraper upon confirmation.
Final Thoughts: Scraping Using Python vs Web Scraping Tools
They both can get you similar results but different in performance. With python, there is certainly a lot of groundwork that needs to take place before implementation. Whereas, scraping tools are a lot more friendly on many levels.
If you are new to the world of programming and want to explore the power of web scraping, nonetheless to say, a web scraping tool is a great starting point. As you set foot in the door of coding, there’re wider choices and combinations that I believe will spark new ideas and make things more effortless and easier.
Published at DZone with permission of Liz Zhang. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments