Is Standard Java Logging Dead?
Does JUL still have a place in the ecosystem? See how a variety of third-party logging tools stack up against Java's built-in logging power.
Join the DZone community and get the full member experience.
Join For Freefor more like this, visit the takipi blog .

the java log levels showdown: severe fatal error omg panic
capitalized log levels induce high levels of stress. what if, instead of error we’d just use “oops”? on a more serious note, we’ve recently run a huge data crunch over github’s top java projects and the logging statements they use , revealing the log level breakdown of the average java project.
in this post, we’ll explore the resulting data set from another angle, shed some more light on the dataset, and put the focus on the use of standard java.util.logging levels versus more popular frameworks like log4j (+ log4j 2), and logback.
step right in.
meet the players
logging utilities can be roughly divided into two categories: the logging facade and the logging engine.
as far as logging facades go, you pretty much have two choices: slf4j and apache’s commons-logging. in practice, 4 out of 5 java projects choose to go with slf4j . based on data from the top java libraries in 2016 on github . the motivation for using a logging facade is pretty definitive and straightforward, an abstraction on top of your logging engine of choice — allowing you to replace it without changing the actual code and logging statements.
as to the logging engine, the most popular picks are logback, which is an evolved version of log4j , log4j itself, and its new version since the development was passed on to the apache software foundation, log4j2. trailing behind is java’s default logging engine, java.util.logging aka jul.
pointing fingers and calling names
on the “superficial” side of things, each of the logging frameworks has slightly different names for their logging levels.
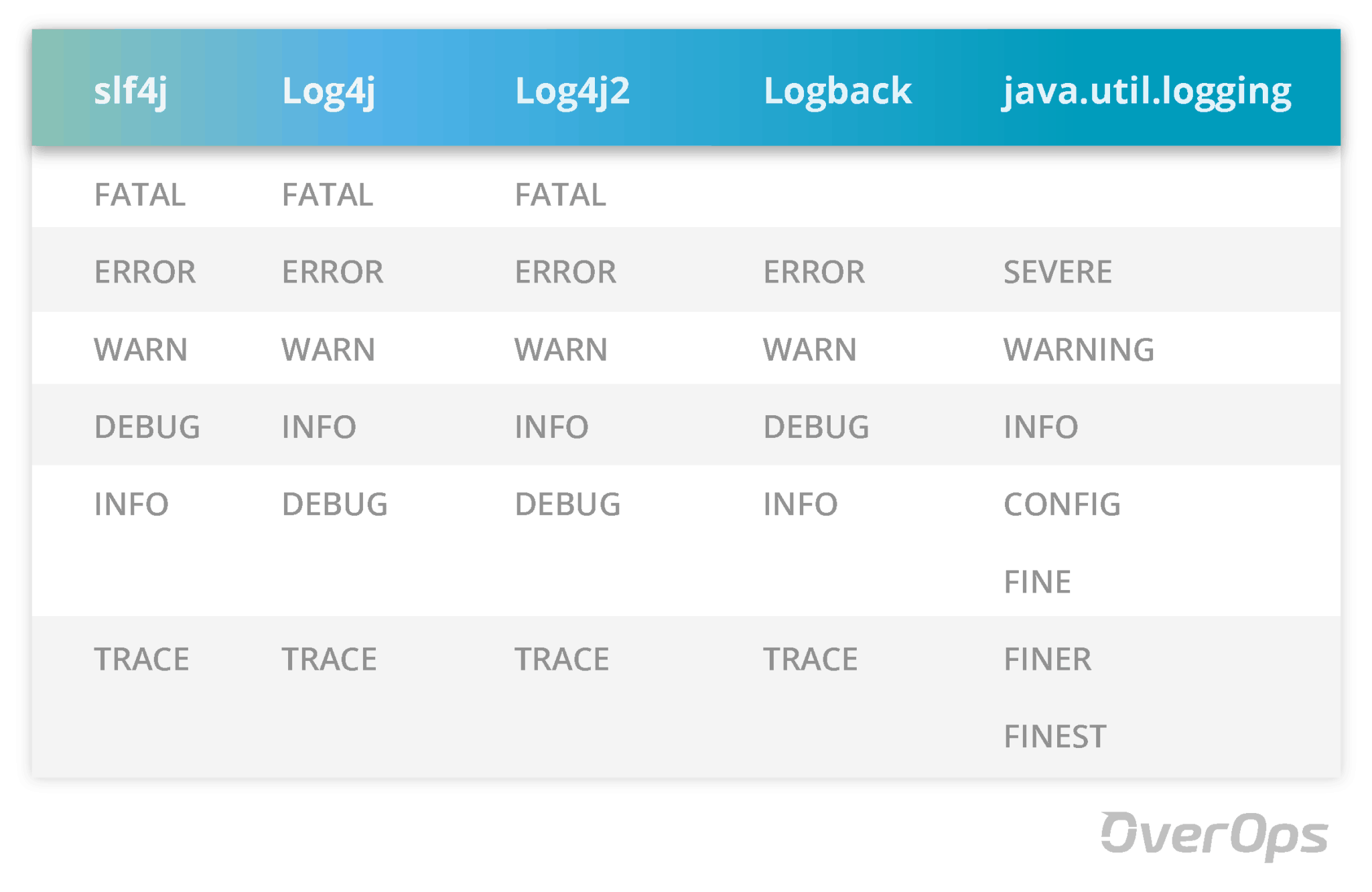
in the rare case where slf4j is used with java.util.logging, the following mapping takes place:
finest -> trace
finer -> debug
fine -> debug
info -> info
warning -> warn
severe -> error
another thing to notice here is that logback and java.util.logging have no fatal equivalent. behind those error names, are simple integer values, that help control the logging level in a running application. each library also contains values for off and all, which basically set the logger level to actually transmit everything, or nothing. setting a logger level at warn for instance, would only log warn messages and above – it's practically the default setting for production environments.
by the way, one of the cool things about the tool that we’re building , is that you can get log messages lower than warn in production, even if you’ve set the logger level to warn . check out this video for a quick (25 sec) demonstration .
how does level naming look in practice?
for the data crunch, we focused on the top starred java projects with at least 100 logging statements in either of the methods. examining the data set of projects, here’s what we found:
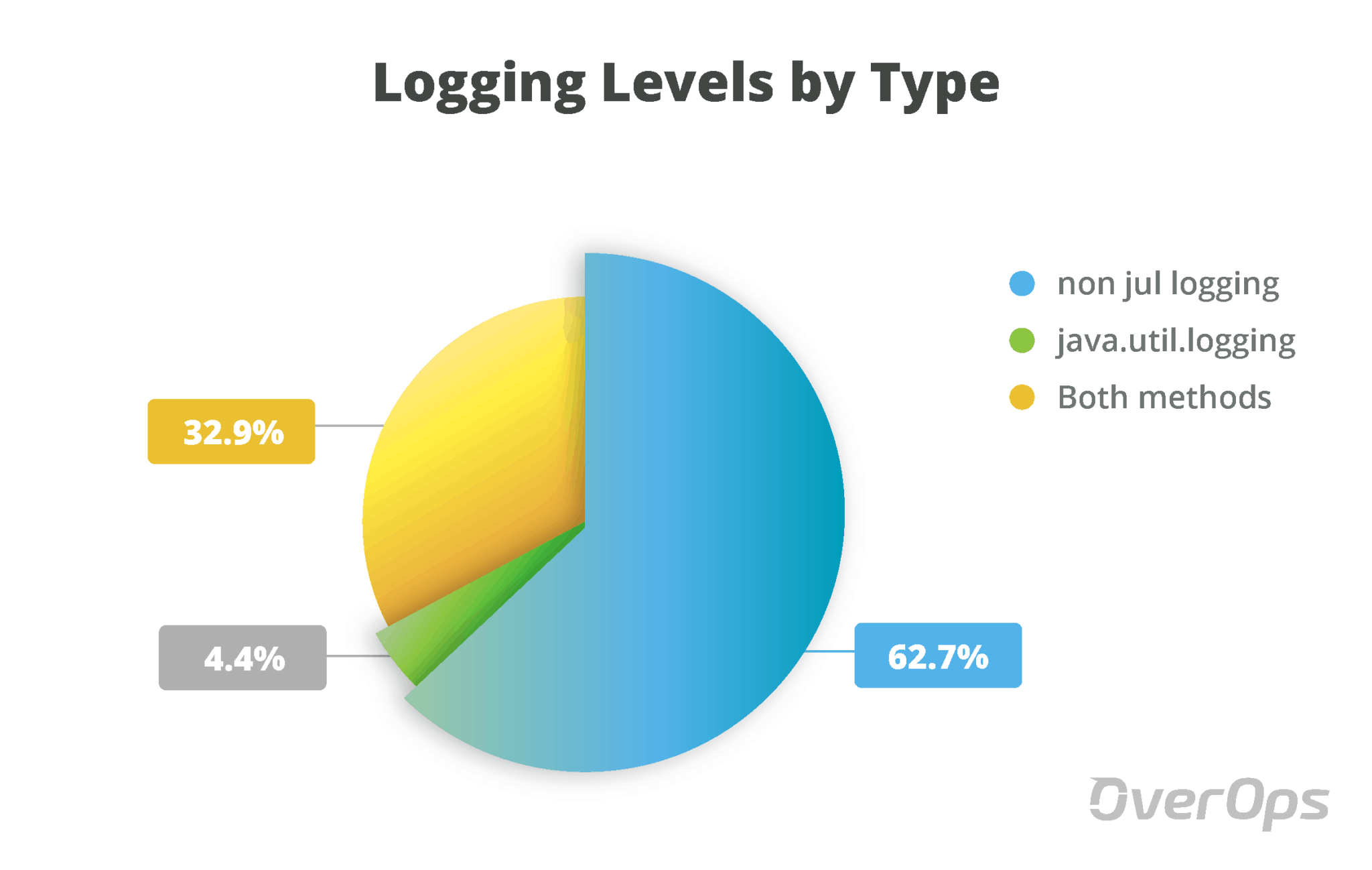
only 4.4% of projects exclusively used the java.util.logging naming scheme.
the average non-jul logging project, looked like this (examining 1,313 projects):

to look at the average java.util.logging project, we filtered it down to include only projects who had at least 100 statements from levels that don’t overlap with the non-jul naming scheme (warning and info). this left us with a smaller dataset, so it might not be big enough to make definite conclusions from:

with that said, it looks like in both situations, roughly ⅔ of logging statements are disabled in production , since only warn and above are activated in that case.
fun fact: as an extra datapoint, we also looked at all/off levels. turns out only 8.6% of the projects examined used them both.
how did we reach the data?
the starting point for this research is the github archive , and its datasets on google bigquery. we wanted to focus on qualified java projects, excluding android, sample projects, and simple testers. a natural choice was to look at the most starred projects, taking in the database of the top 400,000 repositories.
we ended up with 15,797 repositories with java source files, 4% of the initial dataset. but it didn’t stop there. looking at the number of logging statements, we decided to only focus on projects with at least 100 different statements. the dataset is available right here .
we believe this to be a fairly representative sample of what we were trying to achieve. for the full walkthrough and the steps we took to reach the data, including the exact sql queries, check out the last part in this post .
final thoughts
this post stresses out that java.util.logging is, well, practically dead. most serious projects choose to go with 3rd party logging frameworks. did you find anything else that we might have missed in the dataset? do you have other interesting questions that can be answered through this or similar data?
feel free to suggest your ideas in the comment section below.
Published at DZone with permission of Alex Zhitnitsky. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments