Java UDFs and Stored Procedures for Data Engineers: A Hands-On Guide
See how to build Java-based stored procedures and UDFs in Snowflake using Snowpark APIs for scalable, efficient data workflows, including async processing and file handling.
Join the DZone community and get the full member experience.
Join For FreeJava has long been the backbone of enterprise applications, but its role in data engineering is growing rapidly. Today, modern data platforms like Snowflake are giving Java developers first-class support to write powerful, flexible, and scalable data logic directly inside the database environment.
This guide demonstrates how Java developers can leverage familiar tools — like classes, streams, and DataFrames — to build user-defined functions (UDFs) and stored procedures for real-time and batch data processing. By writing this logic in Java, you can encapsulate business rules, perform asynchronous operations, interact with structured or unstructured data, and maintain robust, reusable codebases within your data workflows.
We’ll explore practical patterns for using Java to read dynamic files, execute logic across large datasets, and orchestrate non-blocking operations, all using standard Java concepts, enhanced by Snowflake’s integration where needed. Whether you're building a custom transformation layer or ingesting external files, these examples are grounded in Java fundamentals with modern data-driven use cases.
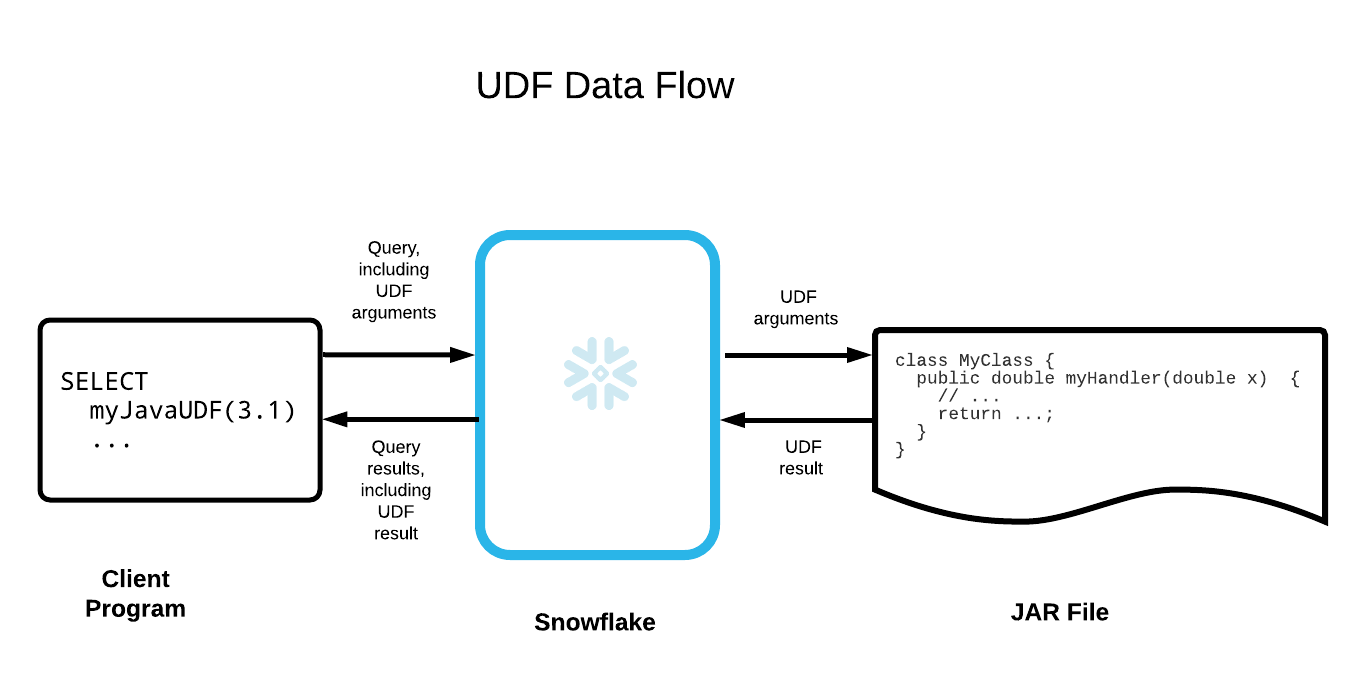
Stored Procedures for Java Developers
Stored procedures allow Java developers to embed business logic directly into the data layer, making it possible to automate complex workflows, orchestrate data transformations, and run administrative tasks all using familiar Java syntax and structure. With support for in-line or pre-compiled Java classes, developers can define handler methods that accept parameters, return single values or tabular results, and interact with data via platform-specific APIs like Snowpark. These procedures are ideal for scenarios that require conditional logic, looping, exception handling, and integration with external resources or files.
Java stored procedures also support advanced features such as role-based execution (caller’s vs. owner’s rights), asynchronous operations, and logging for monitoring and debugging — making them a powerful tool for scalable and maintainable data applications in cloud environments like Snowflake.
CREATE OR REPLACE PROCEDURE file_reader_java_proc_snowflakefile(input VARCHAR)
RETURNS VARCHAR
LANGUAGE JAVA
RUNTIME_VERSION = 11
HANDLER = 'FileReader.execute'
PACKAGES=('com.snowflake:snowpark:latest')
AS $$
import java.io.InputStream;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import com.snowflake.snowpark_java.types.SnowflakeFile;
import com.snowflake.snowpark_java.Session;
class FileReader {
public String execute(Session session, String fileName) throws IOException {
InputStream input = SnowflakeFile.newInstance(fileName).getInputStream();
return new String(input.readAllBytes(), StandardCharsets.UTF_8);
}
}
$$;
CALL file_reader_java_proc_snowflakefile(BUILD_SCOPED_FILE_URL('@sales_data_stage', '/car_sales.json'));Asynchronous Processing With Java Stored Procedures
Asynchronous processing is a critical pattern for building responsive, non-blocking systems, and now, Java developers can bring that same approach to data workflows. Using JDBC within a stored procedure, you can execute long-running tasks asynchronously via methods like executeAsyncQuery(). For instance, the getResultJDBC() procedure uses SYSTEM$WAIT(10) to simulate a delay, showing how to trigger a non-blocking operation inside a data platform. This pattern is especially useful when orchestrating workflows that involve waiting on external services or time-consuming computations.
By offloading these tasks asynchronously, you avoid tying up compute resources and allow other operations to continue in parallel, making your data processes more efficient and scalable — all with standard Java patterns and APIs.
CREATE OR REPLACE PROCEDURE getResultJDBC()
RETURNS VARCHAR
LANGUAGE JAVA
RUNTIME_VERSION = 11
PACKAGES = ('com.snowflake:snowpark:latest')
HANDLER = 'TestJavaSP.asyncBasic'
AS
$$
import java.sql.*;
import net.snowflake.client.jdbc.*;
class TestJavaSP {
public String asyncBasic(com.snowflake.snowpark.Session session) throws Exception {
Connection connection = session.jdbcConnection();
SnowflakeStatement stmt = (SnowflakeStatement)connection.createStatement();
ResultSet resultSet = stmt.executeAsyncQuery("CALL SYSTEM$WAIT(10)");
resultSet.next();
return resultSet.getString(1);
}
}
$$;
User-Defined Functions (UDFs) With Java
User-defined functions (UDFs) let Java developers bring custom logic directly into SQL queries, making them a powerful tool for extending built-in functionality with familiar Java code. UDFs are lightweight, reusable functions that always return a value — ideal for tasks like string manipulation, calculations, data formatting, or even simple validations. Unlike stored procedures, which are invoked as standalone SQL commands, UDFs are embedded directly into queries, allowing you to apply logic row by row across large datasets.
For example, let’s say you’re working with a column that contains arrays of strings, and you want to concatenate those values into a single sentence. With a Java UDF, you can write a simple static method using String.join, package it into a JAR, and then call it in your SQL as if it were a native function.
For example, imagine processing product tags, names, or user inputs stored as arrays. This approach helps standardize and flatten those values in line with your analytics workflows.
The best part? You get to maintain your logic in clean, testable Java code while keeping execution inside the data platform for performance and scalability.
CREATE OR REPLACE TABLE string_array_table(id INTEGER, a ARRAY);
INSERT INTO string_array_table (id, a) SELECT
1, ARRAY_CONSTRUCT('Hello');
INSERT INTO string_array_table (id, a) SELECT
2, ARRAY_CONSTRUCT('Hello', 'Jay');
INSERT INTO string_array_table (id, a) SELECT
3, ARRAY_CONSTRUCT('Hello', 'Jay', 'Smith');
CREATE OR REPLACE FUNCTION concat_varchar_2(a ARRAY)
RETURNS VARCHAR
LANGUAGE JAVA
HANDLER = 'TestFunc_2.concatVarchar2'
TARGET_PATH = '@~/TestFunc_2.jar'
AS
$$
class TestFunc_2 {
public static String concatVarchar2(String[] strings) {
return String.join(" ", strings);
}
}
$$;
SELECT concat_varchar_2(a)
FROM string_array_table
ORDER BY id;Understanding Parallel Execution of Java UDFs
When deploying Java user-defined functions (UDFs) in a distributed environment like Snowflake, it’s essential to understand how they execute in parallel, both across JVMs and within each JVM.
- Across JVMs: Java UDFs run across multiple workers in the underlying compute infrastructure, each of which may launch its own JVM. These JVMs operate independently, so there's no shared memory or state between them. This means static variables, caches, or singletons won’t persist across workers.
- Within a JVM: A single JVM can invoke the same UDF method concurrently on multiple threads. As a result, your handler method must be thread-safe. Avoid shared mutable state or use synchronization when necessary.
If your UDF is marked IMMUTABLE, Snowflake optimizes execution by reusing results for repeated calls with the same input, like memoization. This is particularly useful for deterministic functions, and it’s a good practice to flag them as immutable when appropriate to boost performance.
/*
Create a Jar file with the following Class
class MyClass {
private double x;
// Constructor
public MyClass() {
x = Math.random();
}
// Handler
public double myHandler() {
return x;
}
}
*/
CREATE FUNCTION my_java_udf_1()
RETURNS DOUBLE
LANGUAGE JAVA
IMPORTS = ('@sales_data_stage/HelloRandom.jar')
HANDLER = 'MyClass.myHandler';
CREATE FUNCTION my_java_udf_2()
RETURNS DOUBLE
LANGUAGE JAVA
IMPORTS = ('@sales_data_stage/HelloRandom.jar')
HANDLER = 'MyClass.myHandler';
SELECT
my_java_udf_1(),
my_java_udf_2()
FROM table1;Creating and Calling a Simple In-Line Java UDF
This example illustrates how to create and call a straightforward in-line Java User-Defined Function (UDF) that simply returns the VARCHAR value it receives.
The function is defined with the optional CALLED ON NULL INPUT clause. This ensures that the function is executed even if the input value is NULL. Although the function would return NULL whether or not the clause is included, you can adjust the function to handle NULL values differently, such as returning an empty string instead.
CREATE OR REPLACE FUNCTION echo_varchar(x VARCHAR)
RETURNS VARCHAR
LANGUAGE JAVA
CALLED ON NULL INPUT
HANDLER = 'TestFunc.echoVarchar'
TARGET_PATH = '@~/testfunc.jar'
AS
'class TestFunc {
public static String echoVarchar(String x) {
return x;
}
}';
SELECT echo_varchar('Hello Java');
Passing a GEOGRAPHY Value to an In-Line Java UDF
This example demonstrates how to pass a GEOGRAPHY value to an in-line Java UDF, enabling spatial data processing within the function.
CREATE OR REPLACE FUNCTION geography_equals(x GEOGRAPHY, y GEOGRAPHY)
RETURNS BOOLEAN
LANGUAGE JAVA
PACKAGES = ('com.snowflake:snowpark:1.2.0')
HANDLER = 'TestGeography.compute'
AS
$$
import com.snowflake.snowpark_java.types.Geography;
class TestGeography {
public static boolean compute(Geography geo1, Geography geo2) {
return geo1.equals(geo2);
}
}
$$;
CREATE OR REPLACE TABLE geocache_table (id INTEGER, g1 GEOGRAPHY, g2 GEOGRAPHY);
INSERT INTO geocache_table (id, g1, g2)
SELECT 1, TO_GEOGRAPHY('POINT(-122.35 37.55)'), TO_GEOGRAPHY('POINT(-122.35 37.55)');
INSERT INTO geocache_table (id, g1, g2)
SELECT 2, TO_GEOGRAPHY('POINT(-122.35 37.55)'), TO_GEOGRAPHY('POINT(90.0 45.0)');
SELECT id, g1, g2, geography_equals(g1, g2) AS "EQUAL?"
FROM geocache_table
ORDER BY id;Stored Procedures vs UDFs: Know the Difference
Here’s a quick comparison:
| Feature | Stored Procedure | User-Defined Function (UDF) |
|---|---|---|
| Purpose | Perform admin or batch operations using SQL. | Return a computed value, often used in queries. |
| Return Value | Optional — may return status or custom values. | Required — must return a value explicitly. |
| SQL Integration | Called as stand-alone SQL commands. | Embedded inline in SQL (e.g., SELECT MyFunc(col)). |
| Best For | DDL/DML, workflows, automation. | Transformations, expressions, calculations. |
- UDFs return a value; stored procedures need not
- UDF return values are directly usable in SQL; stored procedure return values may not be
- UDFs can be called in the context of another statement; stored procedures are called independently
- Multiple UDFs may be called with one statement; a single stored procedure is called with one statement
- UDFs may access the database with simple queries only; stored procedures can execute DDL and DML statements
Final Thoughts
This article explored key techniques for building robust Java-based solutions using Snowpark APIs. We covered creating and calling Java stored procedures and UDFs, performing asynchronous operations, handling unstructured data through file access, and returning tabular results. These tools allow you to enhance your workflows with custom logic, parallelism, and integration with external data formats.
As you continue to develop with Java and Snowpark, consider how these features can optimize your data workflows and enable more complex processing scenarios. Whether you're encapsulating business logic, processing files at scale, or improving performance through parallel execution, Snowpark's support for Java provides the flexibility to build scalable and maintainable solutions.
Opinions expressed by DZone contributors are their own.
Comments