Introduction to Kubernetes for Application Developers
This brief introduction to Kubernetes will give you a high-level overview and resource links to deepen your understanding.
Join the DZone community and get the full member experience.
Join For FreeKubernetes is a highly configurable and complex open-source container orchestration engine. Therefore, it is very easy to feel completely overwhelmed when learning it. The goal of this article is to present the very basic concepts at the core of it while keeping the focus on the development side.
Concepts
First, let’s start with some concepts we will play with in this article.
Kubernetes is running and orchestrating containers. I assume here that you are already familiar with containers, if not, have a look at containers first.
Workloads
A workload is an application running on Kubernetes. Workloads are run inside a Pod.
Pod
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes.
A Pod (as in a pod of whales or pea pod) is a group of one or more containers, with shared storage and network resources, and a specification for how to run the containers. A Pod’s contents are always co-located and co-scheduled, and run in a shared context. A Pod models an application-specific "logical host": it contains one or more application containers which are relatively tightly coupled. In non-cloud contexts, applications executed on the same physical or virtual machine are analogous to cloud applications executed on the same logical host.
Workload Resources
Kubernetes provides several built-in workload resources. We will focus here on two of those, the Deployment and the ReplicaSet.
- Deployment. A Deployment provides declarative updates for Pods and ReplicaSets. You describe a desired state in a Deployment, and the Deployment Controller changes the actual state to the desired state at a controlled rate. You can define Deployments to create new ReplicaSets or to remove existing Deployments and adopt all their resources with new Deployments.
- ReplicaSet. A ReplicaSet's purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods. How a ReplicaSet works
Networking
In order for applications to work together, they need to communicate and be accessible to other applications and the outside world. This is managed through networking.
We will focus here on the Service and Ingress notions.
Service
An abstract way to expose an application running on a set of Pods as a network service. With Kubernetes you don’t need to modify your application to use an unfamiliar service discovery mechanism. Kubernetes gives Pods their own IP addresses and a single DNS name for a set of Pods, and can load-balance across them.
Ingress
In order to redirect public traffic into the cluster, we need to define an Ingress.
An API object that manages external access to the services in a cluster, typically HTTP. Ingress may provide load balancing, SSL termination and name-based virtual hosting.
Wrapping It Up
If we had to summarize those concepts in a few words, we would have this:
| Pod | A group of one or more containers, sharing storage and network resources, with their run instructions that are deployed together. |
| Deployment | A declarative way of defining the desired state for Pods and how to deploy and roll it out. |
| ReplicaSet | Guarantees the availability of a specified number of identical Pods. |
| Service | A single access point (IP/port) with load balancing to a set of Pods. |
| Ingress | A gateway to the cluster with routing to services. |
Interacting With a Kubernetes Cluster
The kubectl command-line tool is the best way to interact with a Kubernetes cluster.
In order to understand the example application that will follow, let’s introduce the main concepts and patterns behind it.
kubectl <verb> <resource>
A general pattern for the kubectl command is the kubectl <verb> <resource> one.
Where:
<verb>is (but not limited to):createget,describe,patch,delete,expose, …<resource>is a Kubernetes resource:pod,deployment,service, …
Note |
You can add an
|
kubectl apply
A typical usage is to apply a Kubernetes resource file. Such a file (usually yaml or JSON) contains the definition of one or more resources that will be applied to the cluster.
For example: kubectl apply -f https://uri.to/resources.yaml
A Sample Application
Prerequisites
It is required to have a Kubernetes cluster available with:
kubectlconfigured to target the Kubernetes cluster for reproducing the examplesA Dashboard installed
A Metrics server installed
An Ingress Controller installed
In case you do not already have this, follow instructions in the appendix.
Deploy It
Let’s use a sample echoserver application as an example. This application will echo the HTTP request information received (URI, method, headers, body, …) in the response it will return. It is provided as a container image named k8s.gcr.io/echoserver:1.4.
We can create a deployment for this application with the following command:
❯ kubectl create deployment echoserver --image=k8s.gcr.io/echoserver:1.4
deployment.apps/echoserver createdWe can validate our deployment has correctly been created
❯ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/echoserver-75d4885d54-cbvhh 1/1 Running 0 11m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d22h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/echoserver 1/1 1 1 11m
NAME DESIRED CURRENT READY AGE
replicaset.apps/echoserver-75d4885d54 1 1 1 11mWe do see our deployment deployment.apps/echoserver has been created. It instantiated a ReplicaSet replicaset.apps/echoserver-75d4885d54 which in turn created pod pod/echoserver-75d4885d54-cbvhh which runs our container.
In the dashboard, the Workloads overview will look like this.
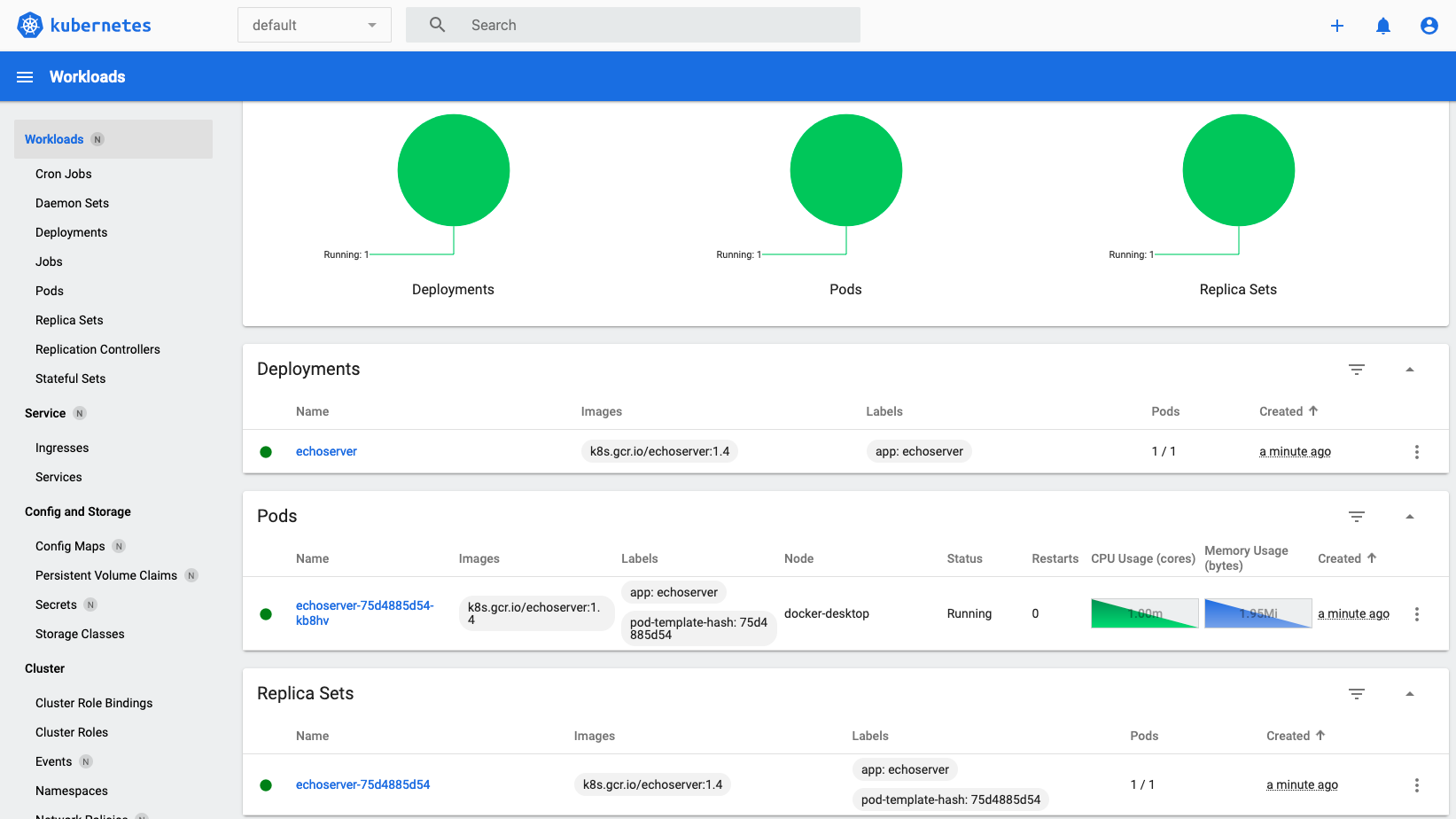
Figure 1. Workloads overview in the Kubernetes dashboard
and our deployment:
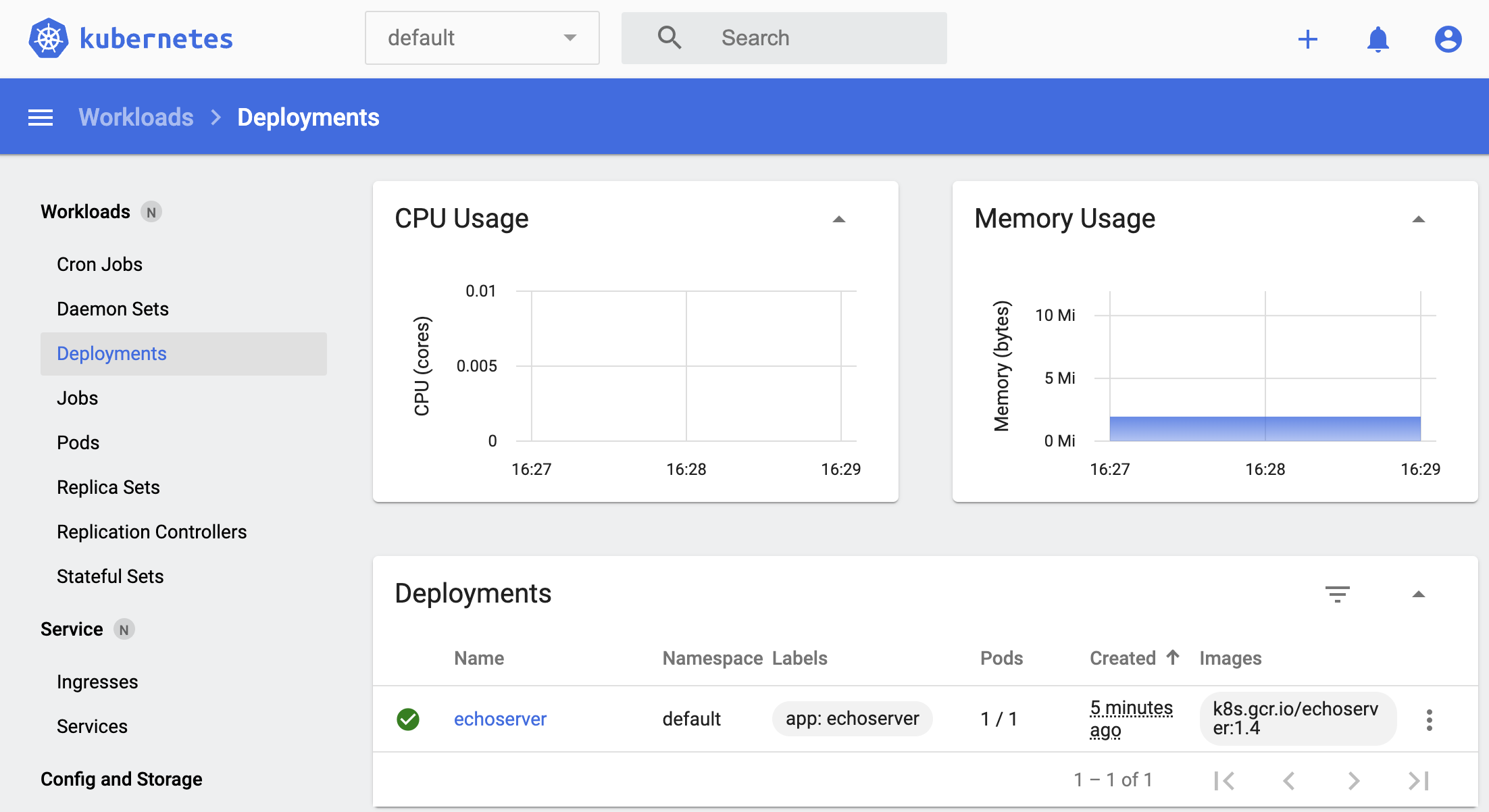
Figure 2. Deployments in the Kubernetes dashboard
Make It Accessible
Now that the application is deployed, we need to make it accessible. In order to do so, we need to create a service pointing to our pods and expose it externally via an ingress.
Let’s create a service that will listen on port 80 and forward the traffic to one of the pod in the deployment on its port 8080.
❯ kubectl expose deployment echoserver --port 80 --target-port 8080
service/echoserver exposedNow, let’s expose the service externally and route traffic matching for which the HTTP host is echoserver.localdev.me.
❯ kubectl create ingress echoserver --class=nginx --rule='echoserver.localdev.me/*=echoserver:80'
ingress.networking.k8s.io/echoserver createdNote |
The ingress controller will in our example read the host field of incoming HTTP requests and perform routing to internal services based on its value. However, a prerequisite is that the request reaches the ingress controller and this implies the DNS
|
We can see the service and ingress.
❯ kubectl get all,ingress
NAME READY STATUS RESTARTS AGE
pod/echoserver-75d4885d54-cbvhh 1/1 Running 0 21m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/echoserver ClusterIP 10.99.239.96 <none> 8080/TCP 2m16s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d22h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/echoserver 1/1 1 1 21m
NAME DESIRED CURRENT READY AGE
replicaset.apps/echoserver-75d4885d54 1 1 1 21m
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/echoserver nginx echoserver.localdev.me localhost 80 66mIn the dashboard, our service will appear as below.
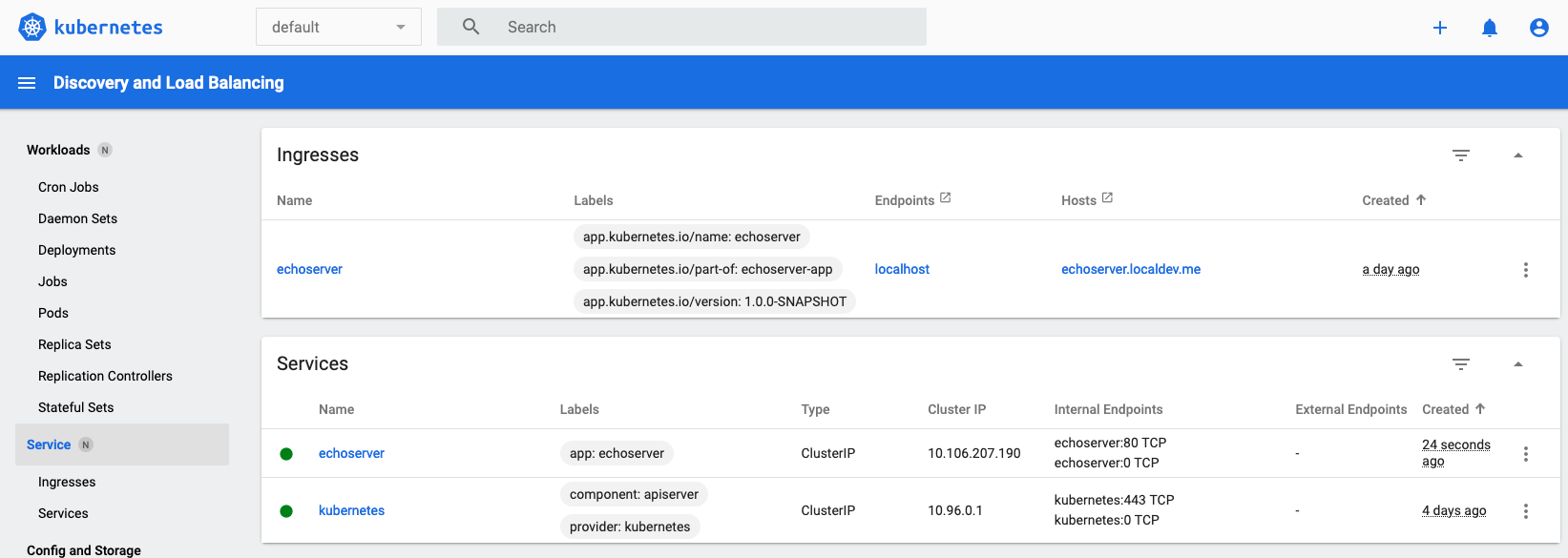
Figure 3. Services in the Kubernetes dashboard
Now that everything is in place, we can target http://echoserver.localdev.me with curl:
❯ curl echoserver.localdev.me
CLIENT VALUES:
client_address=10.1.0.34
command=GET
real path=/
query=nil
request_version=1.1
request_uri=http://echoserver.localdev.me:8080/
SERVER VALUES:
server_version=nginx: 1.10.0 - lua: 10001
HEADERS RECEIVED:
accept=*/*
host=echoserver.localdev.me
user-agent=curl/7.64.1
x-forwarded-for=192.168.65.3
x-forwarded-host=echoserver.localdev.me
x-forwarded-port=80
x-forwarded-proto=http
x-forwarded-scheme=http
x-real-ip=192.168.65.3
x-request-id=c447aa00579e6df16f6b1b854867de12
x-scheme=http
BODY:
-no body in request-Scale Scale Scale
One interesting feature of Kubernetes is its ability to understand application requirements in terms of resources like CPU and/or memory. Thanks to a metrics server, resource consumption is measured and the cluster can react to it.
But in order for the cluster to react, it first needs to know the application requirements. Kubernetes defines two levels: requests and limits.
Requests are the minimum resources that will be allocated. If it is not possible to allocate those resources, the pod or container creation will fail.
Limits are the maximum resources that will be allocated. A higher limit than the request value allows for the application to burst for short periods of time. This is especially useful if a warmup phase is necessary or for unpredictable workloads that can’t wait for additional pods to be scheduled and ready to serve traffic.
Let’s patch our deployment to define CPU requests and limits. Here we will define very low limits in order to play with autoscaling. Let’s say a request of 1 milliCPU and a limit of 4 milliCPU. A milliCPU is an abstract CPU unit that aims to be consistent across the cluster. 1000 milliCPU usually boils down to 1 hyperthread on hyperthreaded processors.
❯ kubectl patch deployment echoserver --patch '{"spec": {"template": {"spec": {"containers": [{"name": "echoserver", "resources": {"requests": {"cpu": "1m"}, "limits": {"cpu": "4m"}}}]}}}}'
deployment.apps/echoserver patchedWe can now enable Horizontal Pod Autoscaling (HPA) for our deployment from 1 to 4 instances with a target CPU threshold of 50 percent.
❯ kubectl autoscale deployment echoserver --cpu-percent=50 --min=1 --max=4
horizontalpodautoscaler.autoscaling/echoserver autoscaledWe can then generate load with JMeter and see the number of pod replicas increasing until the maximum of 4 is defined in our configuration.
❯ kubectl get hpa echoserver --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
echoserver Deployment/echoserver <unknown>/50% 1 4 0 5s
echoserver Deployment/echoserver 1000%/50% 1 4 1 60s
echoserver Deployment/echoserver 700%/50% 1 4 4 2mIn the beginning, we had 0 replicas in the echoserver hpa as the hpa was just started. However a pod from the previous deployment was handling the traffic, but that pod wasn’t part of the hpa listed below.
Meanwhile, in the dashboard, we can see the load of each pod replica.
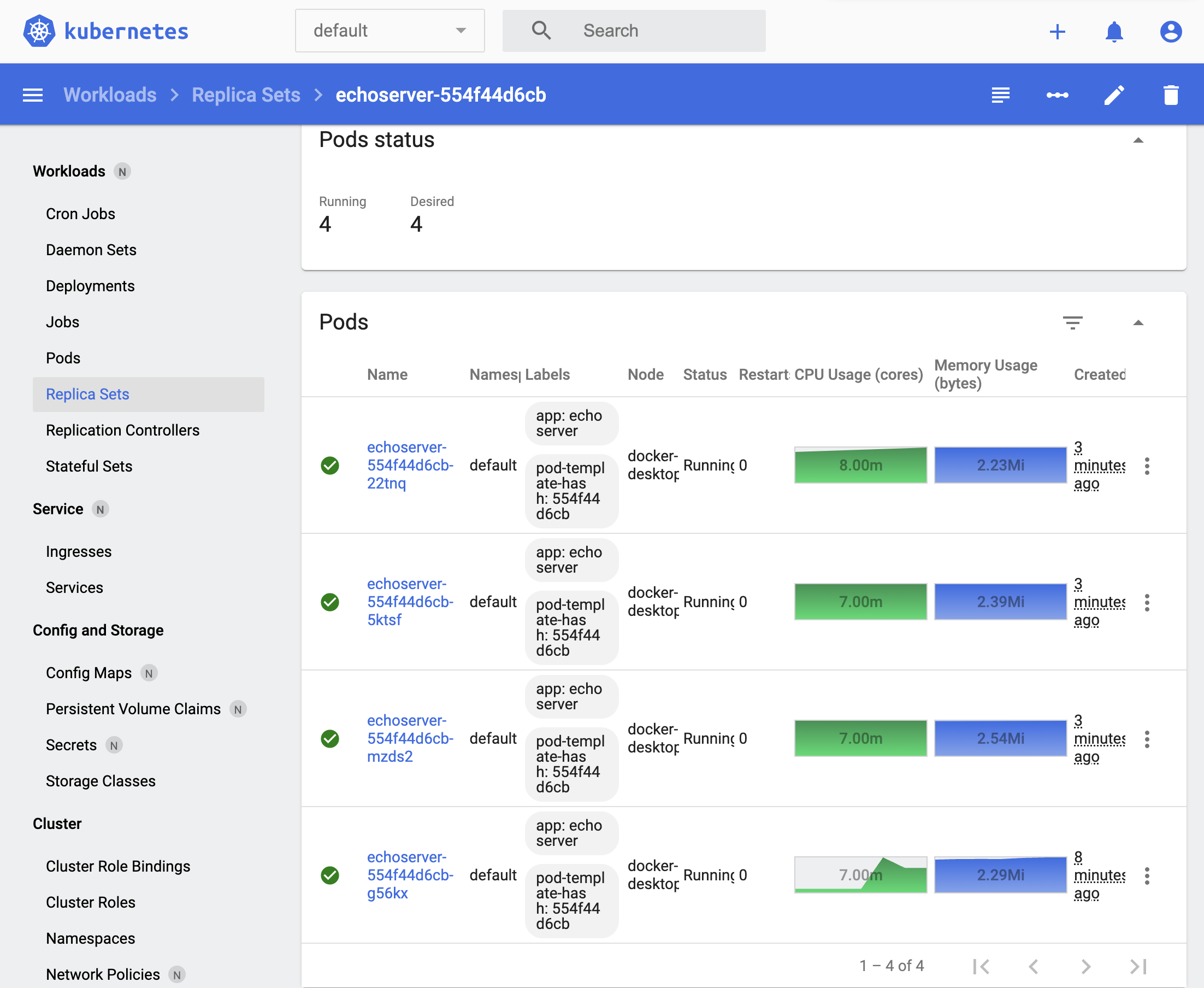
Figure 4. ReplicaSet autoscaling in the Kubernetes dashboard
Declarative Configuration
Until now we used the kubectl tool in an imperative way. It is an easy way to start, but not really the best way to deploy an application in a reproducible way.
To this end we can define our Kubernetes resources (deployments, services, ingress) as JSON or yaml files and apply them to the cluster using the kubectl apply -f <file> pattern.
First, let’s delete our application
❯ kubectl delete deployment,svc,ingress,hpa echoserver
deployment.apps "echoserver" deleted
service "echoserver" deleted
ingress.networking.k8s.io "echoserver" deleted
horizontalpodautoscaler.autoscaling "echoserver" deletedNow let’s apply the following Kubernetes resources configuration.
❯ kubectl apply -f https://loicrouchon.fr/posts/kubernetes-introductions-for-developers/echoserver.yml
service/echoserver created
ingress.networking.k8s.io/echoserver created
deployment.apps/echoserver created
horizontalpodautoscaler.autoscaling/echoserver createdHere is the content of the resources yaml file. It contains the following resources:
The
echoserverDeployment with CPU requests and limits.The
echoserverService pointing to theechoserverDeployment.The
echoserverIngress exposed onechoserver.localdev.meand targeting theechoserverService.the
echoserverHorizontal Pod Autoscaler.
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: echoserver
app.kubernetes.io/part-of: echoserver-app
app.kubernetes.io/version: 1.0.0-SNAPSHOT
name: echoserver
spec:
ports:
- name: http
port: 80
targetPort: 8080
selector:
app.kubernetes.io/name: echoserver
app.kubernetes.io/part-of: echoserver-app
app.kubernetes.io/version: 1.0.0-SNAPSHOT
type: ClusterIP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
labels:
app.kubernetes.io/name: echoserver
app.kubernetes.io/part-of: echoserver-app
app.kubernetes.io/version: 1.0.0-SNAPSHOT
name: echoserver
spec:
ingressClassName: nginx
rules:
- host: echoserver.localdev.me
http:
paths:
- backend:
service:
name: echoserver
port:
number: 80
path: /
pathType: Prefix
status:
loadBalancer:
ingress:
- hostname: localhost
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/part-of: echoserver-app
app.kubernetes.io/version: 1.0.0-SNAPSHOT
app.kubernetes.io/name: echoserver
name: echoserver
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/part-of: echoserver-app
app.kubernetes.io/version: 1.0.0-SNAPSHOT
app.kubernetes.io/name: echoserver
template:
metadata:
labels:
app.kubernetes.io/part-of: echoserver-app
app.kubernetes.io/version: 1.0.0-SNAPSHOT
app.kubernetes.io/name: echoserver
spec:
containers:
- env:
- name: KUBERNETES_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
image: k8s.gcr.io/echoserver:1.5
imagePullPolicy: Always
name: echoserver
ports:
- containerPort: 8080
name: http
protocol: TCP
resources:
limits:
cpu: 10m
memory: 20Mi
requests:
cpu: 5m
memory: 5Mi
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 2
periodSeconds: 2
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
labels:
app.kubernetes.io/part-of: echoserver-app
app.kubernetes.io/version: 1.0.0-SNAPSHOT
app.kubernetes.io/name: echoserver
name: echoserver
spec:
maxReplicas: 4
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: echoserver
targetCPUUtilizationPercentage: 50You can find out more about this declarative approach by reading:
Rolling Out a New Version of an Application
Let’s say we want to roll out a new version of our application. Instead of k8s.gcr.io/echoserver:1.4 we want to use the new k8s.gcr.io/echoserver:1.5 container image.
To do that we can edit the echoserver.yml we saw above and replace the image: k8s.gcr.io/echoserver:1.4 in the containers specification of the Deployment resource with image: k8s.gcr.io/echoserver:1.5.
Now let’s apply the configuration again:
❯ kubectl apply -f https://loicrouchon.fr/posts/kubernetes-introductions-for-developers/echoserver.yml
service/echoserver unchanged (1)
ingress.networking.k8s.io/echoserver unchanged (1)
deployment.apps/echoserver configured (2)
horizontalpodautoscaler.autoscaling/echoserver unchanged (1)Unchanged resources, will not be updated
Updated resource, the deployment will be retriggered
In the console, we can see our deployment being updated with the new image. A new ReplicaSet is started and a new pod is created.
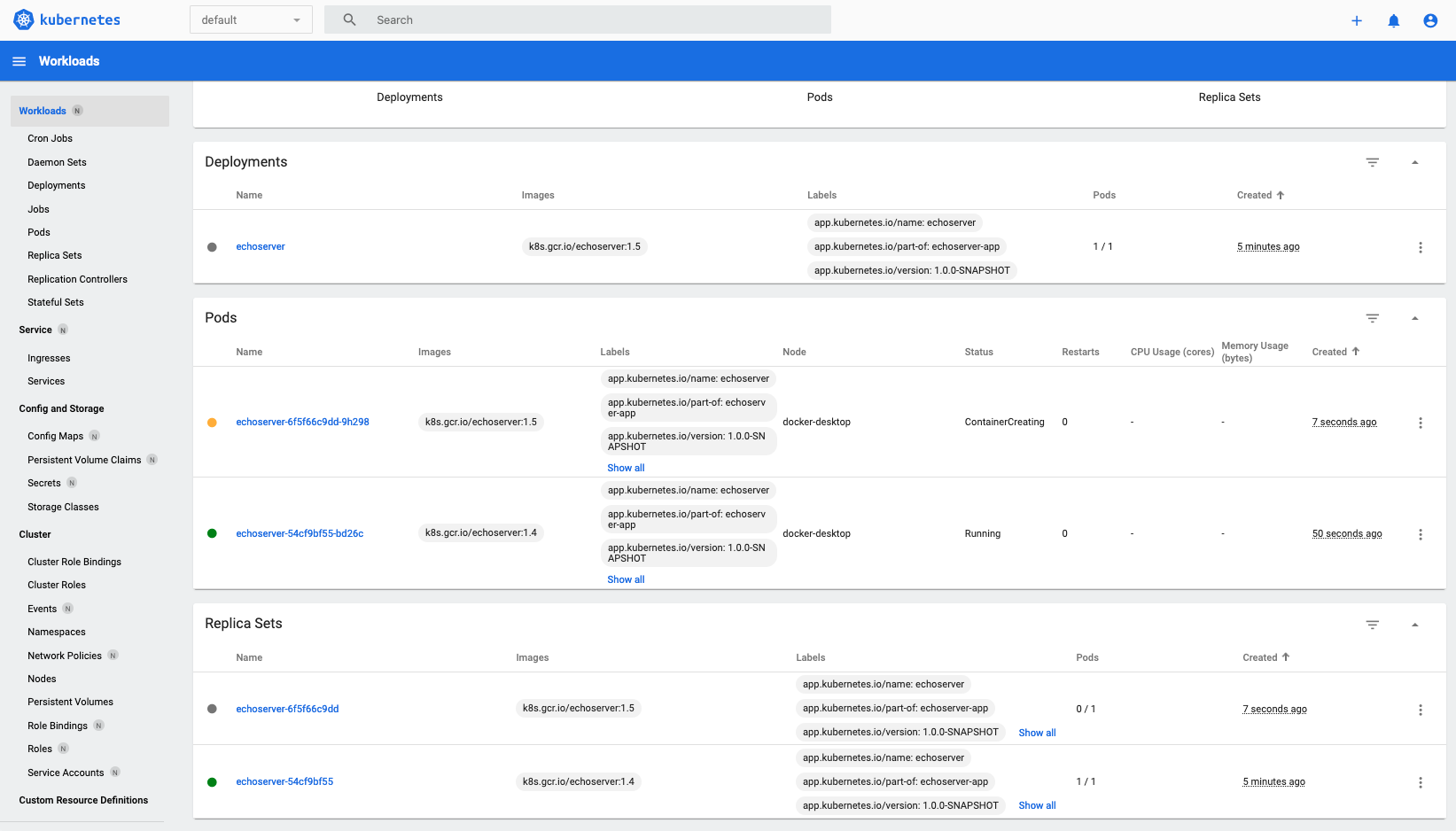
Figure 5. Deployment rollout in the Kubernetes dashboard
If in parallel you were shooting requests on a regular basis with a similar command
watch -n 0.5 curl -s echoserver.localdev.meYou would have seen the output being updated when the traffic was routed to the new version of the application. This is without downtime as the Deployment configuration contains information to help Kubernetes understand if the application is ready and live. Those are called Liveness, Readiness, and Startup Probes and are a must for ensuring traffic is only routed to healthy instances of your application.
Going Further
Today we covered some of the basic concepts of Kubernetes. How to deploy an application, expose it outside the cluster, scale it and perform rollouts. But there’s much more to cover.
Configuration: How ConfigMap and Secrets can help you to configure your applications.
Storage: How to deal with volumes, Persistent or Ephemeral.
CronJob to run recurring scheduled tasks.
StatefulSet for managing stateful applications
Appendix A: Installing a Kubernetes Cluster Locally
The easiest ways to install a local Kubernetes cluster are through one of:
Colima (for macOS users)
For example with Colima:
brew install colima
docker context use colima
colima start --cpu 4 --memory 8 --with-kubernetesStart the Kubernetes Proxy on Port 8001
In a background terminal start kubectl proxy. It will start a proxy that listens on http://localhost:8001/
Installing an Ingress Controller
In our case, we will use nginx as ingress controller, but any other ingress controller is perfectly fine.
You can install it as below:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.1.1/deploy/static/provider/cloud/deploy.yaml
kubectl wait pod --namespace ingress-nginx --for=condition=ready --selector='app.kubernetes.io/component=controller' --timeout=120s
kubectl port-forward --namespace=ingress-nginx service/ingress-nginx-controller 8080:80Additional installation options are available in the ingress-nginx documentation.
Installing Metrics
Installation of metrics allows supporting autoscaling based on pods CPU consumption.
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.1/components.yaml
kubectl patch deployments.app/metrics-server -n kube-system --type=json --patch '[{"op": "add", "path": "/spec/template/spec/containers/0/args/-", "value": "--kubelet-insecure-tls" }]'Install the Kubernetes Dashboard
Install the dashboard and the metrics server with:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.1/aio/deploy/recommended.yamlThe dashboard is accessible at URL http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy
To log in to the dashboard, it is necessary to use a token. You can obtain a token using the following command:
kubectl -n kube-system describe secret (kubectl -n kube-system get secret | awk '/^namespace-controller-token-/{print $1}') | awk '$1=="token:"{print $2}'Published at DZone with permission of Loïc Rouchon. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments