Low Overhead Continuous Contextual Production Profiling
Explore different stack trace visualizations and low overhead continuous contextual production profiling for optimizing performance analysis in production.
Join the DZone community and get the full member experience.
Join For FreeIn the realm of production applications, it is customary to address performance bottlenecks such as CPU and memory issues in order to identify and resolve their underlying causes. In order to gain insight into these problems, we gather a range of metrics and logs to monitor the utilization of system resources such as CPU, memory, and application-specific latencies. It is worth noting that this data collection process does not impact the performance of the application. However, it does not provide visibility into the operations taking place at the code level, such as method, socket, and thread states. Moreover, the process of collecting these profiles introduces overhead during application runtime and necessitates the storage and visualization of significantly large datasets.
This article explores the concept of low overhead high-frequency profilers, which offer a solution to these challenges. It delves into methods for attaching application context to profile samples, enabling the collection of profiles from tens of thousands of application deployments. Additionally, it discusses efficient strategies for storing and visualizing stacks, introduces a novel approach to comparative analysis, and explores aggregation techniques for an extended duration. Furthermore, the article explores the aggregation of profiles across a large number of similar deployments, providing valuable insights for optimizing performance.
Why Is Production Profiling Critical for Root Cause Analysis?
The usage patterns of a production environment vary a lot, making it difficult to simulate some of the production incidents in test environments to triage and find root causes. We will not have access to production environments for several reasons (security and trust, etc.). Then when an incident happens, we need to narrow down problems incredibly rapidly to unblock customers, which demands production profiling and diagnostics data to be available all the time.
Selecting a Profiler
Note: Though profiling concepts are generic to various languages, we use JVM profiling in this blog for the topic of interest.
Profilers can provide many data dimensions, and it is impossible to capture all of them due to performance and data constraints. The first step is to identify what we need to analyze production incidents but a minimum of method profiles to detect CPU regressions, socket I/O to analyze network-related issues, monitor deadlocks, and wait and memory profiles.
Various profiling techniques are available, but they have limitations and must be cautious while solving a given use case. For example, statistical sampling is not entirely accurate but has low application overhead, whereas instrumentation profiling is more accurate but disruptive to application run times. Also, when it comes to Java, some profilers depending on JVM Tool Interface (JVMTI) need to wait for all threads to go to a safe point to be able to collect a stack trace sample, causing application pause time. In contrast, some others that use the HotSpot JVM AsyncGetCallTrace interface do not incur safe point bias. It is also essential to consider licensing costs when an open-source profiler is a great fit. Considering the above points, we opted for Java Flight Recorder (JFR) and Async Profiler as they support the sampling profiling technique and have no safe point bias.
The following are a few observations while evaluating JFR and Async Profiler with an application holding several thousands of threads serving requests, a very large heap, and tens of thousands of classes.
- JFR method profiling at 10ms frequency did not show any noticeable application degradation.
- JFR Socket I/O profiling generated too many events with a default 20ms threshold.
- JFR Java native profiling did not show any noticeable application degradation, however, it added significant size.
- JFR and Async Profiler both showed application performance degradation while collecting memory profiles, and did not seem fit for continuous production profiling.
- JFR Java Monitor wait/park generated too many events causing data overhead.
- Async Profiler method profiling did not show any noticeable application degradation. However, on-demand agent attachment took a few minutes when many class loading and unloading were present.
- Async Profiler native profiling did not show any noticeable application degradation.
The results can be different for another application, but a similar evaluation approach is critical to finalize a profiler and what data can be collected without application disruption. After evaluating the pros and cons, the following optimal configuration is used.
- JFR Continuous method profiling at 10ms frequency to analyze CPU regressions.
- JFR Continuous Socket I/O profiling at 200ms threshold (traces any individual socket operation that is taking more than 200 ms).
- JFR Continuous Java native profiling at 10ms frequency, which includes socket sampling (vs. tracing above).
- JFR on-demand live object samples to analyze memory bottlenecks.
- Thread dumps (incur safe point bias) using Jstack once every 1 min to analyze long-running transactions and deadlocks.
- Async profiler on demand for method and native profiles to analyze issues in calls made to the Operating system.
- Async profiler on-demand memory profiling to analyze memory bottlenecks.
Handling Large Profile Data Volumes
One of the critical challenges while collecting profiling data is volume. Profiles tend to be very large (5 minutes of collection from a single application resulting few hundred Mb), making it difficult to store, retrieve and visualize at a later time. We solved this problem in three ways:
- By storing 10 min window aggregated profiles
- Hashing frame strings
- By applying a threshold on the aggregations
The aggregation reduces duplicates, and the threshold will ignore stack traces that occur less than a number that is not considered to be a significant contributor. After several experiments, we devised the data structure shown below and used object serialization to generate aggregated JSON blobs. The data structure is built with indexes to facilitate faster query abilities, like getting a given stack or navigating the profile. This also helped to reduce profile size by 10 times.
Data structure: (refer to the open-source perfGenie GitHub repo for more implementation, scale, and s3 storage details)
HotspotBlob{
Node trie; // structure to hold paths
Long start;// stacktrace sample start time
Long end;// stacktrace sample end time
Map<Integer, String> nodevalueMap; //node value hash to value
Map<Integer, List<StackidTime>> tidMap; //tid and stacktrace sample timeline
Map<Integer, List<CustoEvent>> custoevents; //map of pid and list of custom events
}
Node{
int hash; //node frame value hash
int sz = 0;//node occurance size
int sf = 0;//did the path end at this node?
List<Node> nodes; // structure to hold paths
Map<Integer, Integer> sm; // index to unique stacktrace, denote start and end of path
}
StackidTime {
Integer hash;
Integer time;
}
TidTime {
Integer tid;
Integer time;
}Attaching Application Context to Profile Samples
In large monolithic applications, the transactions could be from many features, users, or organizations. It is also critical to narrow down profiles for a specific segment, organization, user, etc., to investigate a given problem. Attaching contextual data (feature, organization or user, etc.) to a profile of profilers collecting samples at high frequency will affect application performance if we try to add context to every sample. To solve this problem, we took an alternative approach and attached context to transaction spans as JFR custom events. Using a post-processing task, the context is attached to each sample by mapping time and thread id to transaction span events. Once samples are associated with the application context, it will be easy to filter them the way we want.
The following are some of the screenshots of context filtering features available in the previously linked GitHub repo.
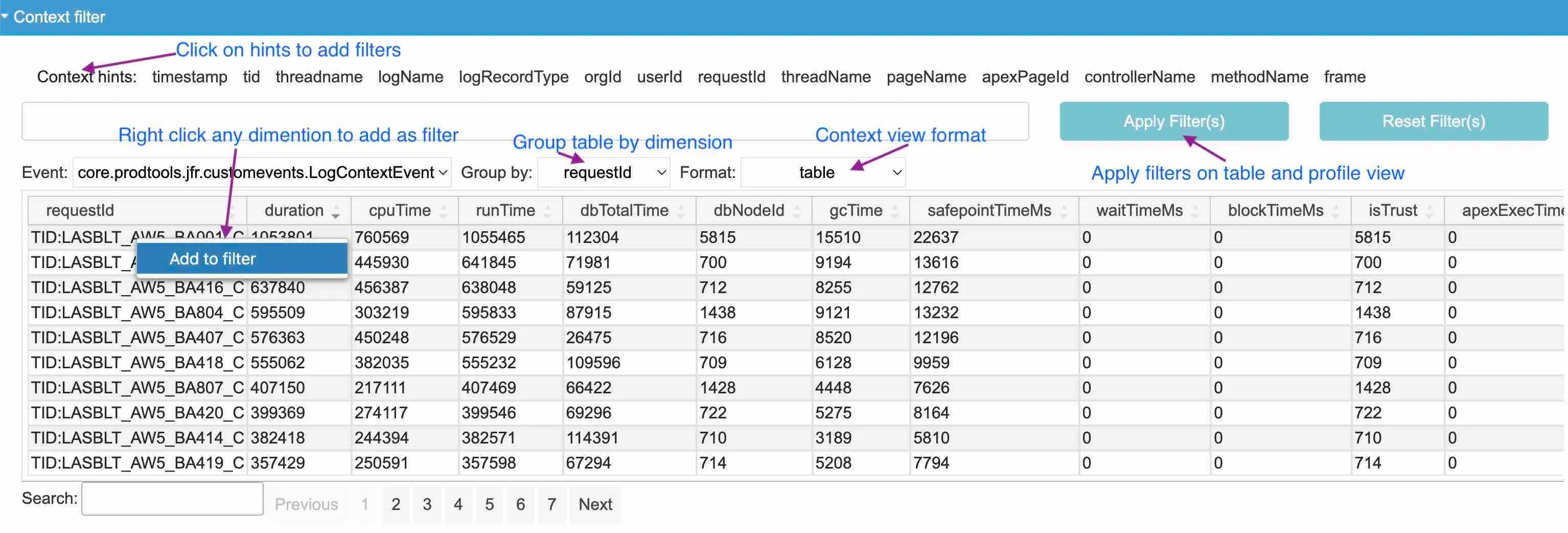
Context filters support using JFR custom event spans

Profile view for a single request transaction
Comparative Analysis
CPU and memory profiles collected are visualized in the form of aggregated call tree/backtrace tree/flame graph for a given time window. However, the visualization does not provide a timeline of stack trace changes to tell what code path is precisely contributing to CPU or memory spike at a given time. The standard techniques used to find regressions are comparing with a baseline profile and visualizing a tree diff or flame graph diff view which are supported in perfGene. However, a new approach showing the time dimension in profile visualization will help identify any regressions. The project has two innovative time-dimension visualizations, river and hotspot surface views, which can help to correlate CPU/Memory trends with profile changes and identify regressions.

Aggregation of profiles for a longer period and aggregation of profiles across a large number of similar deployments
Visualizing profiles for a longer time range and combining a large number of profiles collected from similar deployments is critical to understand the breadth of impact of an application. However, this becomes more challenging when the profile size is too large. The blob structure and the threshold approach helped solve this problem. PerfGene can select multiple hosts and a more extended time range to visualize the profile.
Conclusion
Continuous production profiling is critical to solving a variety of problems in application deployments. The volume of data and visualizations is challenging. However, we have seen an optimal solution using compressed blobs, thresholds, and profile visualization with a time dimension.
What Is Next?
As the profiling solutions evolve, we need zero overhead profiling solutions to understand applications’ CPU and Memory aspects. It will be interesting to see how JFR streaming will help solve some of these challenges. Though the new timeline views permit the identification of regressions, AI correlation models should be explored to automate reducing noise.
Published at DZone with permission of Ravi Pulle. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments