Mainframe Modernization Acceleration Through OpenShift
Mainframe modernization covering supply chain, banking, digital transformation, hybrid cloud, DevOps, target operating model, co-existence, event-driven architecture.
Join the DZone community and get the full member experience.
Join For FreeMainframes have evolved significantly from being a legacy platform to incorporating some of the best cloud capabilities over the recent years. Mainframes have truly been one of the most reliable platforms for business-critical workloads for several years if not decades. The mainframe has been looked at as a growth area in many recent surveys as below:
- 90% of survey respondents see the mainframe as a platform for growth with compliance and security, cost optimization, mainframe modernization, data recovery, staffing and skills, and Implement AI / ML technologies as top focus areas (BMC Mainframe Survey 2020)
- 74% have long-term viability of Mainframe as a strategic platform whereas 66% would never fully replace Mainframes.
The fact that >50% of enterprise application transactions touch the mainframe is a key indicator of its significance and relevance when enterprises are trying to modernize their IT estate. Also, the new generation of Mainframes - IBM Z and LinuxONE Enterprise systems are also being built with capabilities to support modern cloud-native and AI workloads.
Given that the cloud ecosystem is getting into mainframes, multiple surveys indicate that CIOs are either planning to increase or sustain investment on the newer mainframes. A recent survey was done by IBM Institute for Business Value (IBV) also showed results that 71% of executives say mainframe-based applications are central to their business strategy.
Through this article, we will examine the need for mainframe modernization, OpenShift on Z features that help accelerate the modernization journey, followed by two industry scenarios (Supply chain and Banking use cases). We also touch open the aspect of how OpenShift on Z (and new capabilities on Mainframe) enables the extension of the cloud target operating model into the mainframe application portfolios.
There are multiple factors driving the need for mainframe modernization and they are:
- Digital Transformations are driving the need for modernization of the IT ecosystem where the primary need is to drive agility and speed to ensure continuous alignment of IT with business needs.
- Challenges with skilling (retiring staff) and shortage of legacy technology skills (e.g. COBOL / IMS etc.)
- Mainframe estate grew over several years, need for optimization becomes critical – thus optimizing costs
While addressing the above challenges, another key motivation for enterprises is how mainframe technologies have evolved significantly over years. Mainframes have incorporated several elements of cloud (e.g., Containers, Microservices, modern application runtimes and databases, z/OS Connect providing REST APIs to z/OS applications, RedHat OpenShift, IBM Cloud Paks on IBM Z/LinuxONE and Hybrid cluster management using RH Advanced Cluster Management, etc.). Thus, mainframes are an integral part of the hybrid cloud ecosystem today and a key driver for modernization too.
Modernizing Mainframe Workloads – Untangling the Legacy Complexity
There have been many attempts to modernize workloads in mainframes and most of those efforts lead to how successfully someone can untangle the complexity in a gradual and iterative manner. This also leads to the aspect of ensuring operational co-existence of legacy and modernized capabilities for a much longer period due to the complexities and time it takes to modernize mainframe applications. Successful mainframe modernization engagements have addressed the following key challenges:
- Significantly batch-based implementation of processes – as programs and data evolved over a period what resulted was considerable copies of data
- Legacy data structures - mostly hierarchical data not amenable to cloud-native development models
- Tighter integration between program (including UI) and data makes it impossible to modernize everything at once or even sequential – unless specific workloads are gradually identified and modernized.
- Established an iterative less-riskier modernization strategy with a strong co-existence approach that considers long-term operational considerations – not just applications, but also DevOps level co-existence, etc.
Hence understanding the mainframe estate on how programs and data are intertwined is key to establish the right strategy for mainframe modernization. This is done through an assessment that focuses on deeper analysis of business processes and associated mapping of programs and data – and establishes an iterative roadmap that calls out workloads that will be optimized and enhanced within the mainframe and workloads that will be modernized to run on hybrid cloud ecosystems (within and outside mainframe on-premises or on the public cloud).
OpenShift on IBM Z drives a newer set of use cases and possibilities in this modernization story. Last but not the least, a top-down domain-driven design-led identification of services, operations, and data is critical to arriving at an overall execution plan supported by design strategies established through the above-mentioned assessment approach. This blog focuses on how OpenShift on Z enables several newer possibilities in accelerating mainframe modernization. Let us examine some of the features of what OpenShift on Z enables before we examine real-life scenarios.
OpenShift on Z: Overview
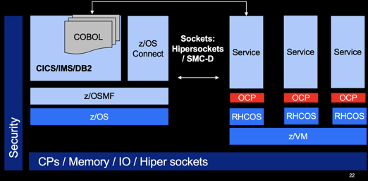
Red Hat OpenShift Container Platform (RH OCP) on IBM Z and LinuxONE help establish a target architecture which is a foundation for microservices to support a hybrid cloud architecture – that’s moveable across IBM Z, distributed, and on-premises cloud platforms. What is also provided is integrated tooling including secure and resilient foundations for cloud-native development on Red Hat Enterprise Linux on IBM Z and LinuxONE.
Following are key highlights of OpenShift on Z:
- In-built cluster logging, monitoring, and metering capabilities supporting both z/VM and KVM virtualization environments.
- Red Hat® CodeReady Workspaces and OpenShift Do for rapid cloud-native application development and deployment.
- OpenShift add-ons like Service Mesh, Serverless, and support for Tekton/pipelines.
- IBM Wazi Developer for Red Hat® CodeReady Workspaces helps developers by providing a consistent and familiar development experience for IBM z/OS.
![OpenShift on Z]() This helps seamless integration with non-mainframe DevOps pipelines to drive end-to-end agility and speed.
This helps seamless integration with non-mainframe DevOps pipelines to drive end-to-end agility and speed. - GitLab Ultimate for IBM® z/OS® is a solution for enterprise-wide DevOps automation, including apps that run on IBM z/OS.
- Portability of applications - Helps develop container-based portable solutions using Red Hat. A recent demonstration of an application re-engineered to Java-based workload on Azure was deployed into OpenShift on Z with minimal integration changes to demonstrate the same.
- Helps implement a private cloud-in-a-box with a significant reduction in data center footprint (4:1 space versus 2:1).
- Helps co-locate workloads alongside traditional Z-based workloads to achieve lower latency.
 This helps seamless integration with non-mainframe DevOps pipelines to drive end-to-end agility and speed.
This helps seamless integration with non-mainframe DevOps pipelines to drive end-to-end agility and speed.Use Cases Supported by OpenShift on Z
OpenShift on Z helps overcome some of the challenges we called out earlier through enabling a set of use cases that enables consolidation and co-location of workloads in the Z ecosystem vis-à-vis helping modernize workloads iteratively and subsequently help decouple them significantly.
Following are some of the use cases along with the challenges they help overcome:
- Ability to build modern user interface apps – helps move away from “green screen” interfaces and help integrated user experience (e.g., ability to integrate user interfaces into front end channels seamlessly, leverage rich application programming interfaces and runtimes).
- Workloads that are meant to be “elastic” in nature but depend heavily on mainframe data (IMS, DB2, etc.).
- Ability to modernize batch programs / integrate with business process automation tools.
- Workloads with higher performance requirements in a single thread.
- Workloads require the advantage of specialty processors.
- Complex workloads (or high transaction workloads) with deep data dependencies including high data volumes.
- Workloads with a high degree of security concern.
- Distributed Java workload for better agility, scalability, and lower cost
Given the above use cases that OpenShift on Z enables, two sections below describe how it helps accelerate mainframe modernization for two industry situations:
How could OpenShift on Z accelerate the modernization of the mainframe-based supply chain ecosystem?
Let’s examine an industry scenario where Mainframe hosts an entire supply chain process that had over 30 groups of programs running into ~12 million lines of code. Most of the processes are realized through a set of batch programs that moves process data across. One could imagine the entire system as a series of process steps executed by a combination of front-end interactions that results in moving core data from one step to another – mostly the group of programs that move data to the next set of programs. There are also a few custom-developed applications (3-tier web) that is part of the supply chain ecosystem. This system covers planning to procuring, shipping/transportation to inventory management, and distribution to various dealers.
While many processes are periodic, the real issues start when changes are triggered in the system – either due to order changes, or manufacturing changes, or shipping delays, and other obvious interventions. The ability to process “differential” updates is one of the biggest challenges as this event is also processed through the normal program/data flows. Getting a new package-based solution OR re-writing the entire system to cloud are probably theoretically viable, the real challenges in realizing the vision are the “data” and how “process” is implemented through integrations/data movements.
Modernizing such a system would have to be done through a top-down Domain-Driven Design (DDD) led approach supplemented by bottom-up discovery and insights-driven analysis. Iterative implementation of the services with a co-existence model will be key to executing such a modernization program. There will be multiple patterns needed to modernize such a system and key ones are UI Rewrite from green-screen, Batch to real-time, IMS to DB2, COBOL to Java (or other modern languages), De-couple programs/data, Event-driven pattern, Master data integration, Re-write to the hybrid cloud, etc. The focus of this blog is to look at how OpenShift on Z helps implement some of the above patterns to accelerate the modernization journey.
Let’s examine some of the use cases:
Enable Integrated User Experience – Users will have to switch between web front ends to green-screen front ends and most of the processes are implemented as batch-based programs orchestrating various activities. OpenShift on Z enables the development of modern front ends using Angular / React etc. hosted on modern application runtimes like Quarkus, SpringBoot, etc. deployed leveraging cloud-native deployment technologies like Serverless, that integrates with Mainframe data.
technologies like Serverless, that integrates with Mainframe data.
This helps achieve quick wins in the journey to build an integrated front-end layer for a seamless user experience. These front ends would evolve as the core services and data are modernized. This also enables developing specific APIs that are needed to provide process flow details, status, data elements, etc. – thus improving visibility into batch-based process flows.
Ability to process “changes” through event-based architecture – One of t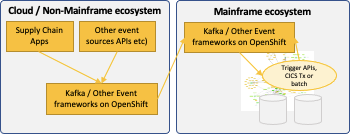 he critical pain points of the existing system was its inability to process changes to various inputs (e.g., change in orders from dealers). Specific processes and activities could be triggered through an API built on OpenShift on Z which in turn can integrate with the Mainframe program and data. These APIs could be wired into either user-triggered events or operational events triggered by other cloud services / event-hubs or Kafka topics.
he critical pain points of the existing system was its inability to process changes to various inputs (e.g., change in orders from dealers). Specific processes and activities could be triggered through an API built on OpenShift on Z which in turn can integrate with the Mainframe program and data. These APIs could be wired into either user-triggered events or operational events triggered by other cloud services / event-hubs or Kafka topics.
Ability to build a strong co-existence layer – Key learning from successful Mainframe modernization engagements is to iteratively modernize workloads in a strangler way where old and new co-exists to the extent of completely modernizing the workload. It is almost impossible to completely modernize applications and services in isolation without building co-existence / integration points with current programs and data in Mainframe.
Establishing co-existence is a complex topic with a clear understanding of functionality and dependent data and what part of functionality and data needs to co-exist. Necessary integration and event models are needed to ensure the same. Co-existence should also be established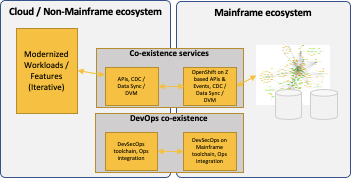 around the development process and tooling on both non-mainframe and mainframe ecosystems. Co-existence setup needs the ability to expose APIs (both ways – from and to Mainframe and Non-Mainframe apps and data-sources), change data capture and sync across, data replication mechanisms, etc.
around the development process and tooling on both non-mainframe and mainframe ecosystems. Co-existence setup needs the ability to expose APIs (both ways – from and to Mainframe and Non-Mainframe apps and data-sources), change data capture and sync across, data replication mechanisms, etc.
OpenShift on Z supports use cases such as exposing APIs, event models for data sync as well as ability to invoke mainframe objects (CICS transactions / other programs). While there are other ways of integrating (including ZOS Connect, z/OS Cloud Broker, MQ, etc.), this approach helps future-proof modernized codebase – which includes DevOps tooling including Ops automation and practices.
Ability to build supply chain master data framework – As mentioned above, as mainframes workloads evolved over a period of time, one would see in most situations data flows from one program sets to another Or one module to another. This results in copies of master data with variations across various program sets/modules. Ability to identify master data and integrate the same with current programs sets/data will be critical for successfully and iteratively building a master data framework while modernizing the applications.
Modernizing the system while establishing the master data for various supply chain processes needs an event-based framework to propagate changes to and from mainframe programs and data. This helps sent master data change events to mainframe programs and data and vice-versa. This enables establishing the master data framework in co-existence with the mainframe ecosystem. Above use cases like event-based framework and co-existence models are critical to accelerating this aspect of modernization.
Enable new ways of working to accelerate (Speed and agility) – Key aspect in modernization initiatives is to be able to scale the development teams and embrace new ways of working that can leverage all the tooling and frameworks mentioned in the OpenShift on Z overview section above.
How could OpenShift on Z accelerate the modernization of mainframe-based banking workloads?
The mainframe has been an integral part of the banking industry. The open system core banking revolution started in the mid-nineties till then the core was developed and maintained in mainframe systems. It is not the popularity that dominated the banking industry rather than need. Banking is a regulated industry with privacy compliance, non-fugitive transaction management, scalability, etc.
These were an integral part of mainframes such as confidential computing, RACF one of the most advanced security system of those days, SYSPLEX for high scalability and availability. Mainframe even supports multi-geography clustering called HAGEO which is a concept adopted by hyper scalars today.
Today, the banking industry is transforming significantly due to cross-over competition from FinTech’s, telco, and retail. Also, the customer expectations and regulatory needs force banks to operate in an agile manner. This in turn forces the bank’s IT to move to agile development with modern technologies which would help deliver products much faster.
Core banking modernization is a mammoth task modernising the entire core banking is not a prudent activity due to the following reason:
- The agile needs of different modules are different. For example, the front office process needs to be more agile compared to the mid and back office.
- The business value of the module also differs. There is a significant business value difference between modernizing a customer platform vs a ledger system. Ledger system being purely internal to the bank and will be used only by few members of the finance team.
- Return on investment differs for each business domain and the components which fetch faster ROI are suitable candidates for modernization.
The following diagram provides a schematic view of hot components which are potential candidates for modernization and aligns with the above-mentioned hypothesis:
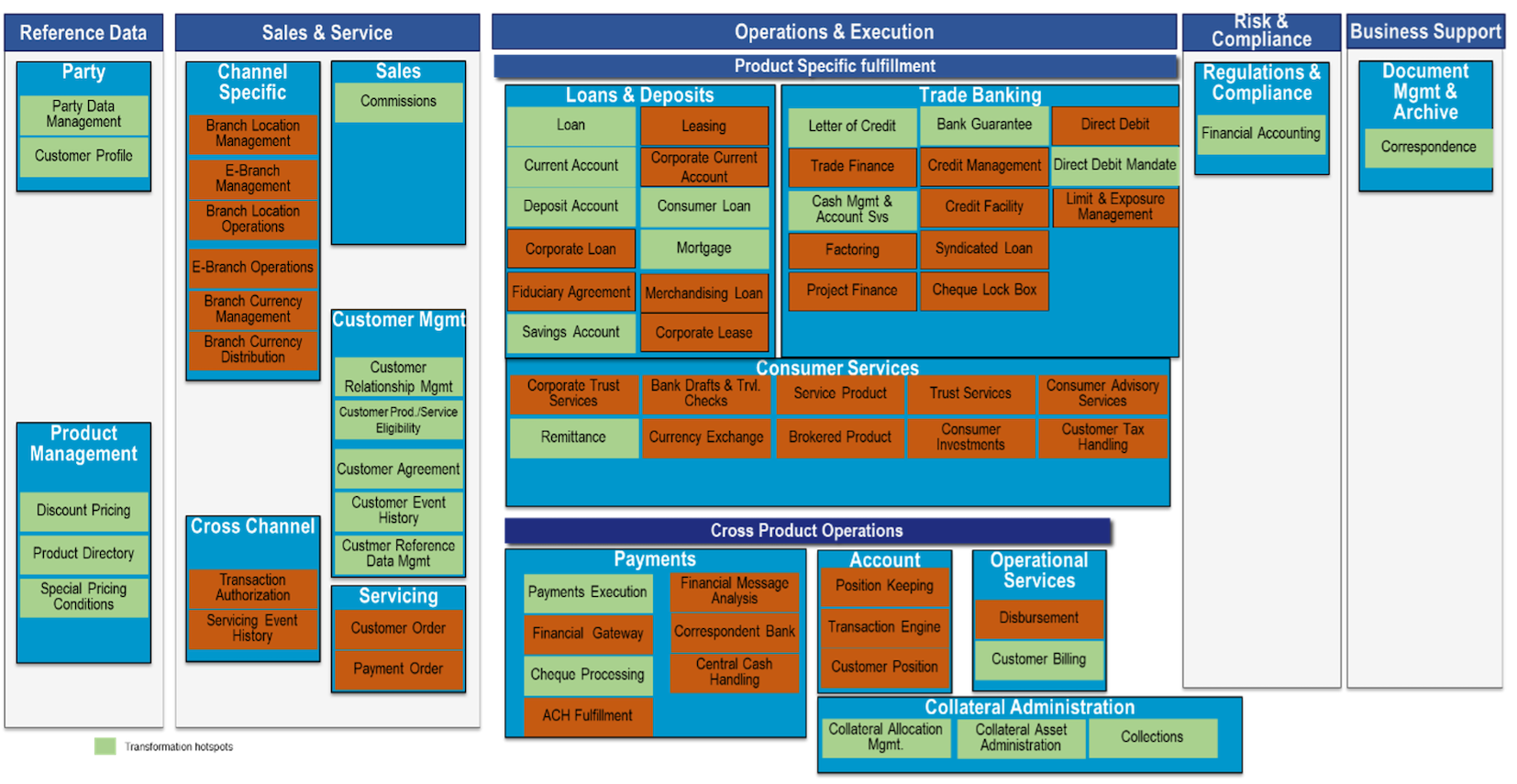
To illustrate the modernizations aspect in detail let us take a use case and elaborate the same:
Use case: Credit scoring
Usage: Used for retail and corporate customers when they apply for any credit products such as loans, credit cards, letters of credit, bank guarantees, etc. Traditionally the credit scoring works on a prescriptive model using attributes such as the following:
- Ticket value
- Past credential of customer
- Credit scoring from a credit bureau
- Demographic information
- Customer segmentation etc.
An aggregated scoring is applied to the above parameters and based on score thresholds green, amber, or red is being decided. Green is a clean candidate for the credit facility. Amber being mid-path where a manual intervention would be required, or additional collateral might be requested in few cases. In the case of red, the credit facility would be rejected.
In a mainframe-based monolith architecture the prescriptive credit score co uld be achieved as shown below:
uld be achieved as shown below:
In the new generation banking system, the credit scoring capabilities are demanding and need AI capabilities to provide better credit scoring capabilities. Especially most of the gen-X customers might not have credit scores in the bureau so alternate credit scoring mechanisms are required. There is multiple alternate credit scoring mechanism such as:
- Alternate credit score derived from social media.
- Alternate credit score derived from past statements
This needs modernization of the entire credit scoring module with additional capabilities as mentioned above:
There are additional use cases that could be considered in the Banking industry such as the following:
- Speed layer for read optimized transactions: This is one of the methods for optimizing MIPS usage. In typical banking, transactions inquiries account for approximately 30% of total MIPS usage. This can be offloaded to an in-memory data grid using technologies such as Redis and Kafka can be used as micro-broker to ensure data consistency between the physical and in-memory data stores.
![Banking industry use cases]()
- Real-time pricing and product suggestions: Traditionally real-time pricing and product suggestion used to be on prescriptive algorithms. The recent innovation in banking has taken these two use cases to newer heights. AI/ML models are used in real-time pricing based on customer lifetime value and product suggestions based on customer real-time analytics.
- Real-time mobile banking experience with edge (push) notifications, transaction alerts, and support/integration to various channel transactions and banking products.

Externalizing customer and product master: Another standard trend in the market is to externalize customer master and product master onto a cloud-native architecture to have better flexibility and agility. The mainframe component of the same remains and operates in slave mode.
How could OpenShift on Z help extend Cloud Operating Model to OpenShift on Z and Mainframe ecosystems?
As discussed above, Mainframes have evolved significantly to include and support several cloud-native capabilities. OpenShift on Z virtually brings DevSecOps concepts, tooling, Microservices / 12-factor application development, automation into the development ecosystem.
Following are key aspects of extending cloud operating model implementation to Mainframe based ecosystems:
- Transition into “product” development model with full-stack squads – also ability to re-align products into value streams driving larger operating model strategy.
- Ability to embrace and implement SRE capabilities in development and operations.
- DevSecOps tooling and practices to be leveraged that are native to OpenShift on Z as well as Z DevOps integrations.
- Driving FinOps models based on products/group of products.
- Help re-skill (or source talent) teams with modern programming languages and practices – and ability to scale teams.
Conclusion
The intent of this article is to bring out some of the challenges in mainframe modernization and how OpenShift on Z helps implement certain use cases that address the challenges. We also highlighted two industry scenarios (Supply chain and Banking) and articulated how OpenShift on Z enables and accelerates modernization.
We also looked at how it helps adopt new ways of working as well as enables scaling of resources / eases re-skilling to build and operate applications and services on the mainframe. In a subsequent article, we will look at a sample application on the mainframe and how some of the above-said use cases can be implemented with code snippets.
Opinions expressed by DZone contributors are their own.
Comments