Metadata Driven Data Engineering: Declarative Pipeline Orchestration in Lakeflow
Define what you want with decorators, Lakeflow figures out how to run it, eliminating boilerplate and reducing operational overhead at scale.
Join the DZone community and get the full member experience.
Join For FreeModern data engineering increasingly relies on streaming data, and Databricks Lakeflow provides a metadata-driven way to orchestrate streaming pipelines. Instead of writing imperative Spark jobs and custom orchestration, Lakeflow lets engineers declare tables and flows with Python decorators. For example, you can define a streaming table with:
from pyspark import pipelines as dp
@dp.table
def customers_bronze():
return spark.readStream.format("cloudFiles") \
.option("cloudFiles.format", "json") \
.option("cloudFiles.inferColumnTypes", "true") \
.load("/Volumes/path/to/files")This function instructs Lakeflow to create a Delta streaming table customers_bronze using Autoloader. Lakeflow automatically infers this is a streaming table and wires up a flow to ingest the data. There is no separate orchestration script running the pipeline causes Databricks to create jobs that continually read new files and append them to customers_bronze.
Declarative vs. Imperative Pipelines
In a traditional imperative pipeline, engineers explicitly code each Spark job and schedule it. Lakeflow flips this model. You declare what tables and transformations you want, and Lakeflow figures out how to execute them. The platform provides automatic orchestration, ensuring the correct execution order, parallelism, and retry logic. Declarative APIs dramatically cut boilerplate. Databricks notes Lakeflow SDP can reduce hundreds or even thousands of lines of Spark code to only a few lines. You still use spark.readStream as usual, and Lakeflow handles watermarks and checkpointing behind the scenes. Lakeflow even offers specialized flows.
Because the runtime knows the table graph, it automatically retries failed tasks and efficiently processes only new data. Engineers focus on what the data pipeline should do, while Lakeflow handles when and how to run the streaming jobs.
Wiring Tables and Dependencies
One big advantage is that Lakeflow infers dependencies between tables automatically. If one table’s definition reads from another table (streaming or static), Lakeflow includes that relationship in the execution DAG. Suppose you have a raw events stream and want an aggregated count per event type:
@dp.table
def raw_events():
return spark.readStream.format("cloudFiles").load("/data/raw_events")
@dp.table
def event_counts():
return spark.readStream.table("raw_events") \
.groupBy("event_type").count()Here event_counts reads from the streaming table raw_events. Lakeflow implicitly orders execution so that raw_events is updated first, then event_counts runs on the new data. In the Lakeflow UI, this appears as a directed acyclic graph of tables. Display a streaming sales_report table that joins a streaming v_transactions table with a static v_customers lookup (defined via @dp.temporary_view), and it will graph that dependency. (Note: streaming tables do a “snapshot” join, so updates to the static v_customers table after the stream starts will not be applied to already processed rows.)
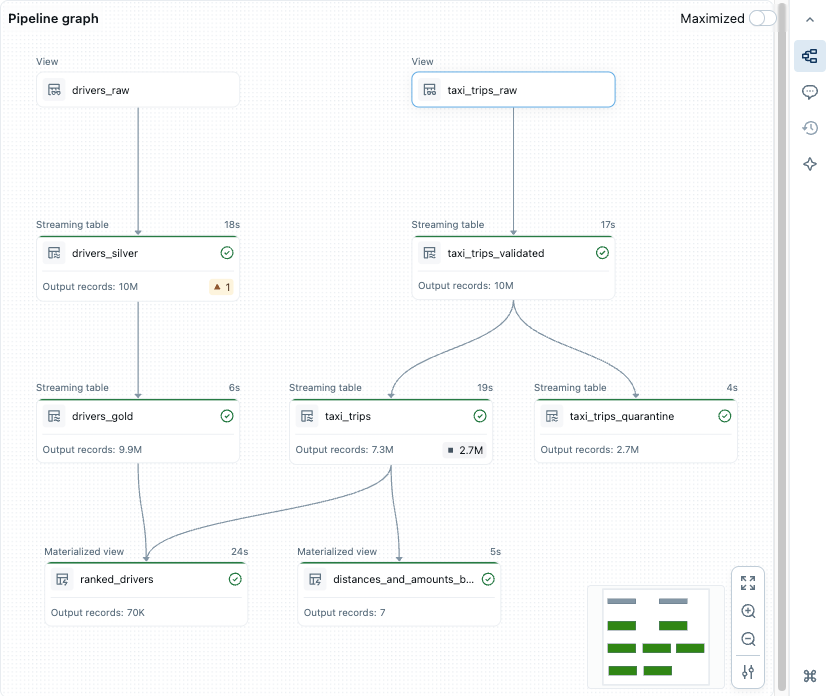
Lakeflow’s pipeline graph editor shows tables as nodes and flows as arrows. In this example, separate streaming tables feed into downstream tables, and each node displays execution metrics. The DAG is generated from the code definitions, making it easy to see how streaming logic is modularized.
Because tables are first-class units, you can organize code across multiple source files. One notebook might define Bronze ingestion tables, another might define Silver transforms. Lakeflow will collect all table definitions in the pipeline folder and stitch them together. This modularity means large streaming workflows with dozens or hundreds of tables emerge automatically, and different teams can work on separate parts without conflict.
Metadata, Schemas, and Quality Rules
Lakeflow pipelines are fundamentally metadata-driven. Tables defined with @dp.table become Unity Catalog managed tables with their schemas and comments. Lakeflow integrates deeply with Unity Catalog, giving every pipeline built-in lineage and governance. Pipelines automatically inherit security policies, access controls, and audit tracking from the catalog. Publish the pipeline’s event log to a Unity Catalog table for auditing.
Data quality rules and schema checks are also declared in metadata. You annotate tables with expectations using decorators like @dp.expect, @dp.expect_or_drop, or @dp.expect_or_fail. For example:
@dp.expect("non_negative_price", "price >= 0")
@dp.expect("valid_date", "date <= current_date()")
@dp.table
def sales_bronze():
return spark.readStream.format("cloudFiles").load("/data/sales")This defines a streaming table sales_bronze with two constraints. Lakeflow checks each incoming record against them and can log or drop violations. Using @dp.expect_or_drop or @dp.expect_or_fail will automatically drop or abort on bad data. These expectation definitions become part of the pipeline’s metadata, enforcing quality on the fly. Lakeflow’s UI then reports how many records passed or failed each check.
Benefits for Large-Scale Streaming
Because logic lives in metadata rather than scripts, Lakeflow pipelines are easier to maintain and discover. Teams often use external metadata tables so that generic Lakeflow code can loop over them. Onboarding a new stream can be as simple as inserting a row into a control table instead of writing new code. The declarative approach also standardizes transformations and policies across all streams, ensuring consistency. Unity Catalog’s search and governance features mean that every table and pipeline is cataloged and governed, improving data discoverability and compliance.
Lakeflow also provides built-in observability and auditability. Every pipeline run is logged with metrics, and Unity Catalog tracks lineage between tables. As one source notes, you can automatically track pipeline changes and data lineage for compliance and auditing. In practice, the Lakeflow UI and event logs let you see historical runs, row counts, schema versions, and errors without custom code. This metadata-driven logging makes it easy to monitor and troubleshoot complex streaming flows. Lakeflow is also designed to reduce human error by capturing dependencies and rules as declarative metadata. Because all logic is centralized, it is easier to audit who changed what and when, freeing engineers to focus on business logic rather than boilerplate.
Adding a new streaming source or changing a validation rule only requires updating a metadata table or decorator, rather than rewriting pipeline code. Over time, this greatly simplifies development and operational overhead.
Conclusion
In summary, Databricks Lakeflow’s declarative API turns each streaming workflow into a graph of metadata defined tables and flows. Engineers define each step with decorators (@dp.table, @dp.expect, etc.) and Lakeflow automatically resolves dependencies, orchestrates the streaming jobs, and enforces schemas and quality rules. This declarative approach contrasts with imperative pipelines, where every step and schedule is coded by hand. For large-scale streaming data engineering, Lakeflow’s metadata-driven approach yields pipelines that are easier to scale, manage, and audit.
Opinions expressed by DZone contributors are their own.
Comments