Migrating MySQL Data to ElasticSearch Using Logstash
We take a look at how to use some of the most popular tools in the world of data to effectively perform the migration of big data sets.
Join the DZone community and get the full member experience.
Join For FreeElasticSearch has created a boom in the market with its ability to store, scale, and perform full-text search and analytics on a humongous amount of data in near real-time. ElasticSearch is an open source search and analytics engine generally used in applications which have complex search features.
In this tutorial, we are going to consider a scenario where we wish to add ElasticSearch to our legacy application as a Secondary Data Source. Say we have a legacy application which uses a MySQL database and now we have a requirement where we need to have a heavy search and we have decided to move to ElasticSearch. My idea here would still stick to Relational Databases as a Primary Data Store and use ElasticSearch as a Secondary Data Store for the requirements where we need to have the heavy search.
So our Relational Databases would be a single source of truth and we could always flatten the Tables and Index that data to ElasticSearch. And to perform heavy search, we will query ElasticSearch and use Relational Databases as is usual for application-db transactions.
So now the questions that might have arisen in our mind are:
How will I migrate all my data from a structured data source (MySQL) to a non-structured data source (Elastic Search)?
Can this migration be done without any downtime?
How will I keep both data sources in sync?
One of the solutions to this is using Logstash input plugin.

Logstash is a plugin-based data collection and processing engine. It comes with a wide range of plugins that makes it possible to easily configure it to collect, process, and forward data in many different architectures.
Processing is organized into one or more pipelines. In each pipeline, one or more input plugins receive or collect data that is then placed on an internal queue. This is by default small and held in memory, but can be configured to be larger and persisted on disk in order to improve reliability and resiliency. Processing threads read data from the queue in micro-batches and process these through any configured filter plugins in sequence. Logstash out-of-the-box comes with a large number of plugins targeting specific types of processing, and this is how data is parsed, processed, and enriched.
Once the data has been processed, the processing threads send the data to the appropriate output plugins, which are responsible for formatting and sending data onwards, e.g. to Elasticsearch.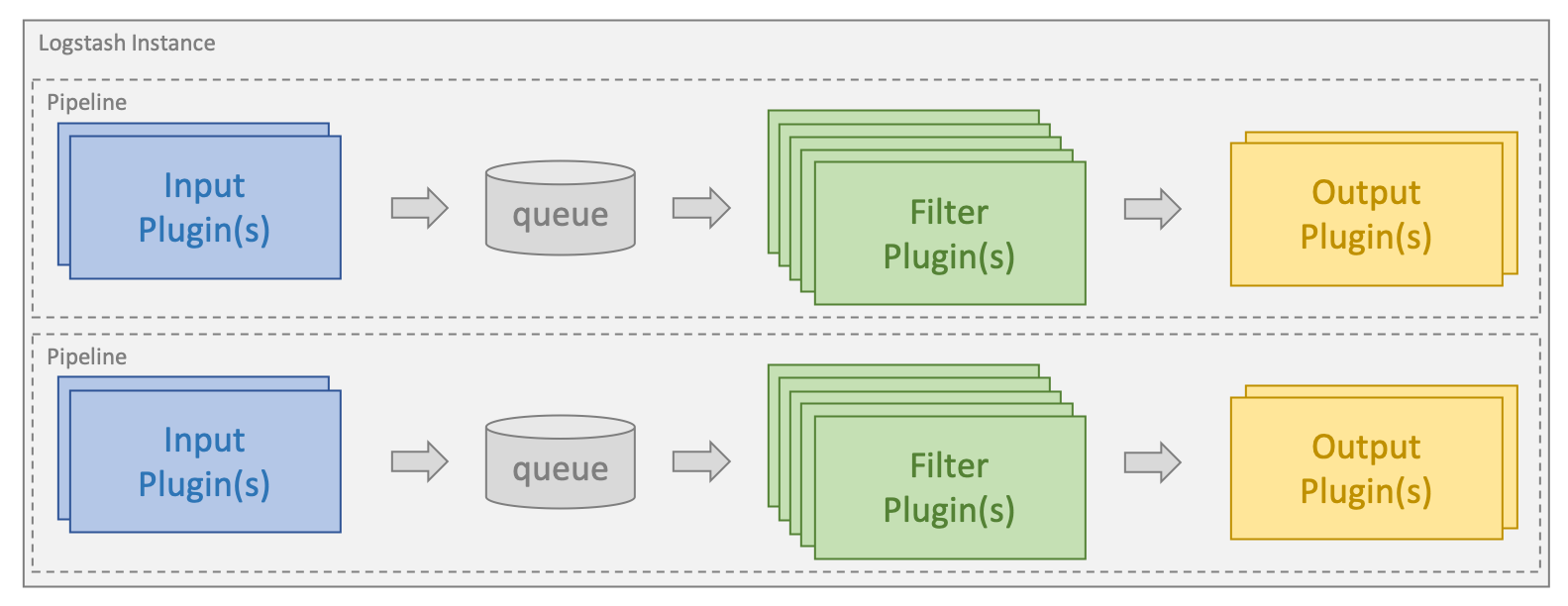
Sample Logstash Pipeline
Lets us consider a simple e-commerce website wherein we maintain data related to the customers and their orders. Now we wish to index our customer-related data to ElasticSearch for performing extensive search operations.
1. MySQL Database Creation
Create a sample database with the name ecomdb and ensure we are using the same database.
CREATE DATABASE ecomdb;
USE ecomdb;2. Now Create a Customer Table With the Below Query and Insert Sample Data
CREATE TABLE customer (
id INT(6) AUTO_INCREMENT PRIMARY KEY,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
email VARCHAR(50),
regdate TIMESTAMP
);
INSERT INTO `ecomdb`.`customer` (`id`, `firstname`, `lastname`, `email`, `regdate`) VALUES (1, 'Roger', 'Federer', '[email protected]', '2019-01-21 20:21:49');
INSERT INTO `ecomdb`.`customer` (`id`, `firstname`, `lastname`, `email`, `regdate`) VALUES (2, 'Rafael', 'Nadal', '[email protected]', '2019-01-22 20:21:49');
INSERT INTO `ecomdb`.`customer` (`id`, `firstname`, `lastname`, `email`, `regdate`) VALUES (3, 'John', 'Mcenroe', '[email protected]', '2019-01-23 20:21:49');
INSERT INTO `ecomdb`.`customer` (`id`, `firstname`, `lastname`, `email`, `regdate`) VALUES (4, 'Ivan', 'Lendl', '[email protected]', '2019-01-23 23:21:49');
INSERT INTO `ecomdb`.`customer` (`id`, `firstname`, `lastname`, `email`, `regdate`) VALUES (5, 'Jimmy', 'Connors', '[email protected]', '2019-01-23 22:21:49');3. Create Our Logstash Configuration.
input {
jdbc {
jdbc_driver_library => "<pathToYourDataBaseDriver>\mysql-connector-java-5.1.39.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/ecomdb"
jdbc_user => <db username>
jdbc_password => <db password>
tracking_column¹ => "regdate"
use_column_value²=>true
statement => "SELECT * FROM ecomdb.customer where regdate >:sql_last_value;"
schedule³ => " * * * * * *"
}
}
output {
elasticsearch {
document_id⁴=> "%{id}"
document_type => "doc"
index => "test"
hosts => ["http://localhost:9200"]
}
stdout{
codec => rubydebug
}
}
¹tracking_column: The column whose value is to be tracked for any changes. Here we will track the regdate column as it will be updated whenever we have a new entry to our database.
² use_column_value: When set to true, it uses the defined tracking_columnvalue as the :sql_last_value. When set to false, :sql_last_valuereflects the last time the query was executed.
The jdbc plugin will persist the sql_last_value parameter in the form of a metadata file — the default location of that file is c:/users/<yourUser>. Upon query execution, this file will be updated with the current value of sql_last_value. Next time the pipeline starts up, this value will be updated by reading from the file. sql_last_value will be set to Jan 1, 1970, or 0 if use_column_value is true.
³schedule: This will periodically run the statement and define values in the Cron format, for example: “* * * * *” (execute query every minute, on the minute). Here we will execute the statement every second so even if any updates or insert are done on our data we will be able to migrate it in our next query execution and our data will be in sync.
⁴ document_id: The document ID for the index is useful for overwriting existing entries in Elasticsearch with the same ID. This will solve the duplication issue if ever the Logstash instance fails.
The above configuration file can be divided into two major sections.
Input plugin (JDBC plugin): Here we define which database URI to connect, user credentials, and the query which will give us the required data.
Output plugin (ElasticSearch plugin): Here we define the Elasticsearch host URL and the index name to which the data is to be indexed.
Save the above code in a file named logstash-sample.conf and the location of this file should be in the bin folder of your Logstash installation.
4. Run Logstash With the Below Command From the Bin Folder of the Logstash Installation
logstash -f logstash-sample.confLogstash will fetch your data from your database and post it to ElasticSearch.
5. Verifying Our Data on ElasticSearch by Executing Below Command
curl -X GET "localhost:9200/test/_search"The output of the above command will be:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "test",
"_type": "doc",
"_id": "4",
"_score": 1,
"_source": {
"firstname": "Ivan",
"id": 4,
"email": "[email protected]",
"lastname": "Lendl",
"@version": "1",
"regdate": "2019-01-23T17:51:49.000Z",
"@timestamp": "2019-02-02T06:20:12.413Z"
}
},
{
"_index": "test",
"_type": "doc",
"_id": "2",
"_score": 1,
"_source": {
"firstname": "Rafael",
"id": 2,
"email": "[email protected]",
"lastname": "Nadal",
"@version": "1",
"regdate": "2019-01-22T14:51:49.000Z",
"@timestamp": "2019-02-02T06:20:12.411Z"
}
},
{
"_index": "test",
"_type": "doc",
"_id": "1",
"_score": 1,
"_source": {
"firstname": "Roger",
"id": 1,
"email": "[email protected]",
"lastname": "Federer",
"@version": "1",
"regdate": "2019-01-21T14:51:49.000Z",
"@timestamp": "2019-02-02T06:20:12.389Z"
}
}
]
}
}Let’s add some twist to the above use case. Say suppose we wish to index order details of each user along with user details in the same document.
1. Create an Order Table in MySQL DB.
CREATE TABLE orders (
orderid INT(6) AUTO_INCREMENT PRIMARY KEY,
product VARCHAR(300) NOT NULL,
description VARCHAR(300) NOT NULL,
price int(6),
customerid int(6),
ordertime TIMESTAMP,
FOREIGN KEY fk_userid(customerid)
REFERENCES customer(id)
);
INSERT INTO `ecomdb`.`orders` (`orderid`, `product`, `description`, `price`, `customerid`,`ordertime`)
VALUES (1, 'Tennis Ball', 'Wilson Australian Open', '330', '5','2019-01-22 20:21:49');
INSERT INTO `ecomdb`.`orders` (`orderid`, `product`, `description`, `price`, `customerid`,`ordertime`)
VALUES (2, 'Head Xtra Damp Vibration Dampner', 'Dampens string vibration to reduce the risk of pain', '500', '4','2019-01-23 02:21:49');
INSERT INTO `ecomdb`.`orders` (`orderid`, `product`, `description`, `price`, `customerid`,`ordertime`)
VALUES (3, 'HEAD Wristband Tennis 2.5" (White)', '80 % Cotton, 15% Nylon, 5 % Rubber (Elasthan)', '530', '3','2019-01-21 21:21:49');
INSERT INTO `ecomdb`.`orders` (`orderid`, `product`, `description`, `price`, `customerid`,`ordertime`)
VALUES (4, 'YONEX VCORE Duel G 97 Alfa (290 g)', 'Head Size 97', '4780', '2','2019-01-22 14:21:49');
INSERT INTO `ecomdb`.`orders` (`orderid`, `product`, `description`, `price`, `customerid`,`ordertime`)
VALUES (5, 'Wilson Kaos Stroke - White & Black', 'Wilson Australian Open', '9000', '1','2019-01-25 03:53:49');Now once we are ready with database and, as we wish to index order details in the same document as a nested JSON object along with user details, we will make use of Filter plugin provided by Logstash. There are various plugins supported by Logstash and we can choose one according to our need. We are going to use Ruby Filter. With the Ruby Filter, we can execute any random Ruby code.
The question that might have popped up in our mind is:
How will we get data from two different tables using JDBC input plugin? We will be using join query.
select c.id as customerid,c.firstname ,c.lastname ,c.email, c.regdate ,
od.orderid ,od.product ,od.description , od.price ,od.ordertime
from customer as c left join orders as od on c.id = od.customerid;2. Write Ruby Code as per our Requirements
Ruby code for manipulating our document looks like what I've got below:
# the filter method receives an event and must return a list of events.
# Dropping an event means not including it in the return array,
# while creating new ones only requires you to add a new instance of
# LogStash::Event to the returned array
def filter(event)
orderid =event.get("orderid")
product = event.get("product")
description = event.get("description")
price = event.get("price")
ordertime = event.get("ordertime")
orderDetails ={
"orderid" => orderid,
"product" => product,
"description" => description,
"price" => price,
"ordertime" => ordertime
}
event.set('orderDetails',orderDetails)
event.remove('orderid')
event.remove('product')
event.remove('description')
event.remove('price')
event.remove('ordertime')
return [event]
endName the Ruby file sampleRuby.rb. The Ruby filter has a mandatory filter method which accepts a Logstash event and must return an array of events. In the above code, we have manipulated the event by creating a hash of order details and set that hash as a new field in the event. We have also removed the fields which are not required after the order details hash being added.
3. Adding the Ruby Filter to the Logstash Configuration File
The new version of the logstash-sample.conf file will look as follows:
input {
jdbc {
jdbc_driver_library => "<pathToYourDataBaseDriver>\mysql-connector-java-5.1.39.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/ecomdb"
jdbc_user => <db user name>
jdbc_password => <db password>
tracking_column => "regdate"
use_column_value=>true
statement => "select c.id as customerid,c.firstname ,c.lastname ,c.email, c.regdate ,od.orderid ,od.product ,od.description , od.price ,od.ordertime from customer as c left join orders as od on c.id = od.customerid where c.regdate>:sql_last_value;"
schedule => " * * * * * *"
}
}
filter{
ruby{
path¹ => 'sampleRuby.rb'
}
}
output {
elasticsearch {
document_id=> "%{customerid}"
document_type => "doc"
index => "test"
hosts => ["http://localhost:9200"]
}
stdout{
codec => rubydebug
}
}¹ The path of the ruby script file that implements the filter method. The location of the Ruby file should be the same as that of logstash-sample.conf.
4. Run the Above Config File Using the Below Command
logstash -f logstash-sample.confThe output of the above script will be as follows:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 5,
"max_score": 1,
"hits": [
{
"_index": "test",
"_type": "doc",
"_id": "5",
"_score": 1,
"_source": {
"orderDetails": {
"orderid": 1,
"description": "Wilson Australian Open",
"product": "Tennis Ball",
"ordertime": "2019-01-22T14:51:49.000Z",
"price": 330
},
"@version": "1",
"email": "[email protected]",
"@timestamp": "2019-02-02T14:13:46.754Z",
"regdate": "2019-01-23T16:51:49.000Z",
"firstname": "Jimmy",
"customerid": 5,
"lastname": "Connors"
}
}
]
}
}As highlighted above, we have added a nested JSON to our existing document.
The Logstash plugin can serve the purpose of migrating our legacy systems to ElasticSearch. In this way, we have migrated the search part of our application to a search engine instead of using search features provided by our datastore. We are keeping our source of truth in the SQL database but you could also imagine migrating from the legacy datastore to a NoSQL.
Note: The JDBC input plugin is not able to track the delete events (hard delete) on your database. You may consider modifying your database table with an isdeleted flag and use that column as a tracking column.
Published at DZone with permission of Shriram Untawale. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments