Migration from Amazon SQS and Kinesis to Apache Kafka and Flink
DoorDash replaced cloud-native Amazon Kinesis and SQS with Apache Kafka and Flink to provide a simple end-to-end integration pipeline.
Join the DZone community and get the full member experience.
Join For FreeEven digital natives — that started their business in the cloud without legacy applications in their own data centers — need to modernize their cloud-native enterprise architecture to improve business processes, reduce costs, and provide real-time information to their downstream applications. This blog post explores the benefits of an open and flexible data streaming platform compared to a proprietary message queue and data ingestion cloud services. A concrete example shows how DoorDash replaced cloud-native AWS SQS and Kinesis with Apache Kafka and Flink.
Message Queue and ETL vs. Data Streaming With Apache Kafka
A message queue like IBM MQ, RabbitMQ, or Amazon SQS enables sending and receiving of messages. This works great for point-to-point communication. However, additional tools like Apache NiFi, Amazon Kinesis Data Firehose, or other ETL tools are required for data integration and data processing.
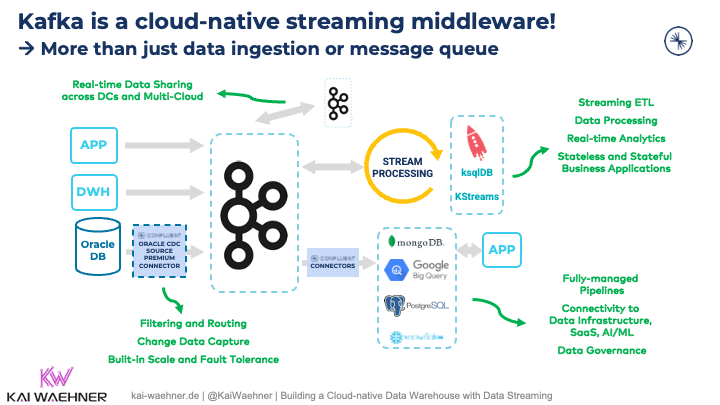
A data streaming platform like Apache Kafka provides many capabilities:
- Producing and consuming messages for real-time messaging at any scale
- Data integration to avoid spaghetti architectures with plenty of middleware components in the end-to-end pipeline
- Stream processing to continuously process and correlate data from different systems
- Distributed storage for true decoupling, backpressure handling, and replayability of events, all in a single platform
Data streaming with Kafka provides a data hub to easily access events from different downstream applications (no matter what technology, API, or communication paradigm they use).
If you need to mix a messaging infrastructure with ETL platforms, a spaghetti architecture is the consequence. Whether you are on-premise and use ETL or ESB tools, or if you are in the cloud and can leverage iPaaS platforms. The more platforms you (have to) combine in a single data pipeline, the higher the costs, operations complexity, and SLA guarantees. That's one of the top arguments for why Apache Kafka became the de facto standard for data integration.
Cloud-Native Is the New Black for Infrastructure and Applications
Most modern enterprise architectures leverage cloud-native infrastructure, applications, and SaaS, no matter if the deployment happens in the public or private cloud. A cloud-native infrastructure provides:
- Automation via DevOps and continuous delivery
- Elastic scale with containers and orchestration tools like Kubernetes
- Agile development with domain-driven design and decoupled microservices
In the public cloud, fully-managed SaaS offerings are the preferred way to deploy infrastructure and applications. This includes services like Amazon SQS, Amazon Kinesis, and Confluent Cloud for fully-managed Apache Kafka. The scarce team of experts can focus on solving business problems and innovative new applications instead of operating the infrastructure.
However, not everything can run as a SaaS. Cost, security, and latency are the key arguments why applications are deployed in their own cloud VPC, an on-premise data center, or at the edge. Operators and CRDs for Kubernetes or Ansible scripts are common solutions to deploy and operate your own cloud-native infrastructure if using a serverless cloud product is not possible or feasible.
DoorDash: From Multiple Pipelines to Data Streaming for Snowflake Integration
DoorDash is an American company that operates an online food ordering and food delivery platform. With a 50+% market share, it is the largest food delivery company in the United States.
Obviously, such a service requires scalable real-time pipelines to be successful. Otherwise, the business model does not work. For similar reasons, all the other mobility services like Uber and Lyft in the US, Free Now in Europe, or Grab in Asia leverage data streaming as the foundation of their data pipelines.
Challenges With Multiple Integration Pipelines Using SQS and Kinesis Instead of Apache Kafka
Events are generated from many DoorDash services and user devices. They need to be processed and transported to different destinations, including:
- OLAP data warehouse for business analysis
- Machine Learning (ML) platform to generate real-time features like recent average wait times for restaurants
- Time series metric backend for monitoring and alerting so that teams can quickly identify issues in the latest mobile application releases
The integration pipelines and downstream consumers leverage different technologies, APIs, and communication paradigms (real-time, near real-time, batch).
Each pipeline is built differently and can only process one kind of event. It involves multiple hops before the data finally gets into the data warehouse.
It is cost-inefficient to build multiple pipelines that are trying to achieve similar purposes. DoorDash used cloud-native AWS messaging and streaming systems like Amazon SQS and Amazon Kinesis for data ingestion into the Snowflake data warehouse: Mixing different kinds of data transport and going through multiple messaging/queueing systems without carefully designed observability around it leads to difficulties in operations.
Mixing different kinds of data transport and going through multiple messaging/queueing systems without carefully designed observability around it leads to difficulties in operations.
From Amazon SQS and Kinesis to Apache Kafka and Flink
These issues resulted in high data latency, significant cost, and operational overhead at DoorDash. Therefore, DoorDash moved to a cloud-native streaming platform powered by Apache Kafka and Apache Flink for continuous stream processing before ingesting data into Snowflake:
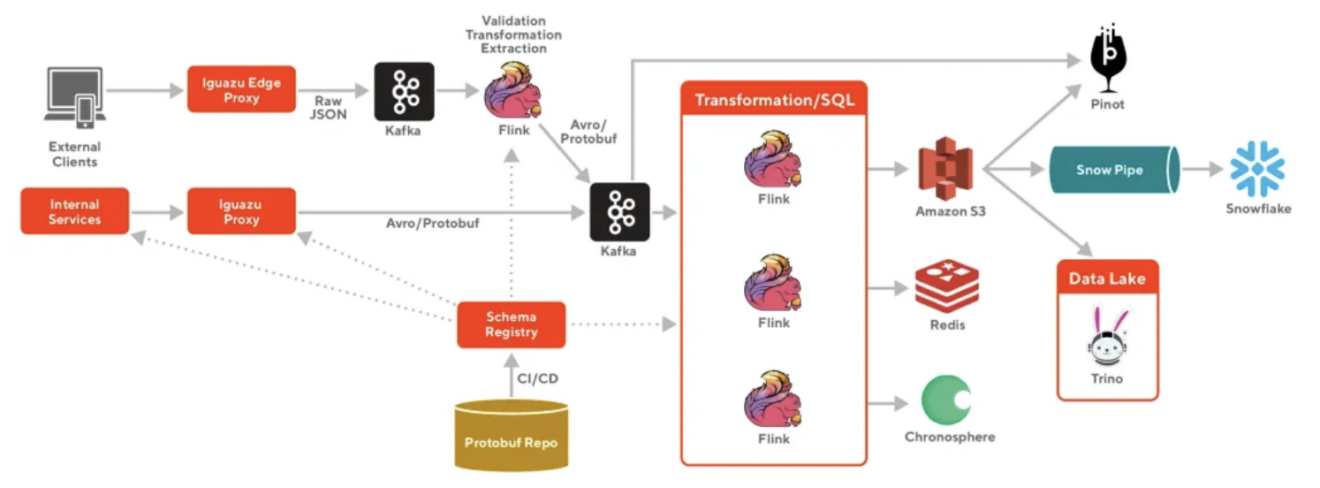
The move to a data streaming platform provides many benefits to DoorDash:
- Heterogeneous data sources and destinations, including REST APIs using the Confluent rest proxy
- Easily accessible from any downstream application (no matter which technology, API, or communication paradigm)
- End-to-end data governance with schema enforcement and schema evolution with Confluent Schema Registry
- Scalable, fault-tolerant, and easy to operate for a small team
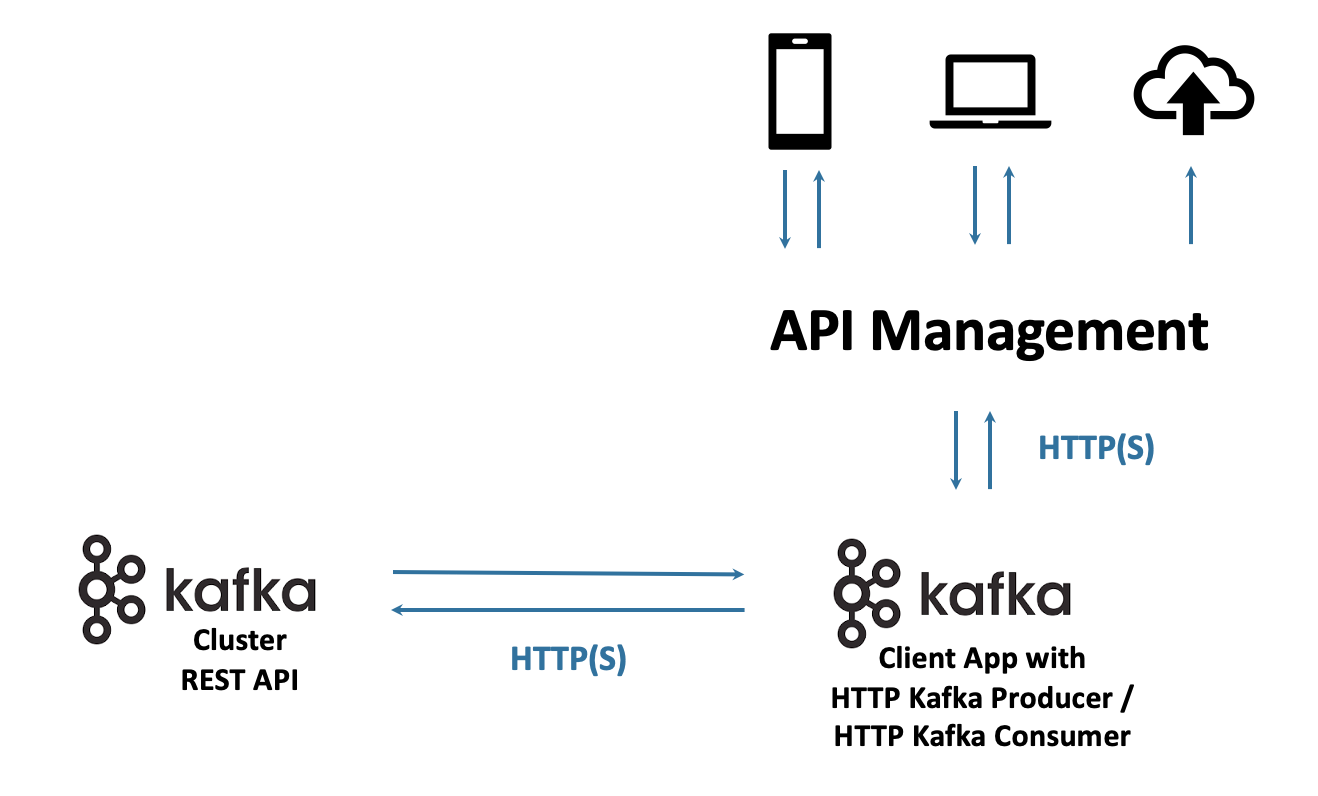
REST/HTTP Is Complementary to Data Streaming With Kafka
Not all communication is real-time and streaming. HTTP/REST APIs are crucial for many integrations. DoorDash leverages the Confluent REST Proxy to produce and consume via HTTP to/from Kafka.
All the details about this cloud-native infrastructure optimization are in DoorDash's engineering blog post: "Building Scalable Real-Time Event Processing with Kafka and Flink."
Don't Underestimate Vendor Lock-In and Cost of Proprietary SaaS Offerings
One of the key reasons I see customers migrating away from proprietary serverless cloud services like Kinesis is cost. While it looks fine initially, it can get crazy when the data workloads scale. Very limited retention time and missing data integration capabilities are other reasons.
The DoorDash example shows how even cloud-native greenfield projects require modernization of the enterprise architecture to simplify the pipelines and reduce costs.
A side benefit is the independence of a specific cloud provider. With open-source powered engines like Kafka or Flink, the whole integration pipeline can be deployed everywhere. Possible deployments include:
- Cluster linking across countries or even continents (including filtering, anonymization, and other data privacy relevant processing before data sharing and replication)
- Multiple cloud providers (e.g., if GCP is cheaper than AWS or because Mainland China only provides Alibaba)
- Low latency workloads or zero trust security environments at the edge (e.g., in a factory, stadium, or train.
How do you see the trade-offs between open source frameworks like Kafka and Flink versus proprietary cloud services like AWS SQS or Kinesis? What are your decision criteria to make the right choice for your project? Did you already migrate services from one to the other?
Published at DZone with permission of Kai Wähner, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments