Mission-Critical Cloud Modernization: Managing Coexistence With One-Way Data Sync
Implementing a one-way data sync with AWS Data Migration Service: Challenges and coexistence strategy during complex cloud modernization with the phased rollout.
Join the DZone community and get the full member experience.
Join For FreeThe modernization process aims to enhance the efficiency, agility, and resiliency of an organization's existing IT infrastructure, architecture, and products by implementing the latest technologies, methodologies, and models, such as cloud computing, agile development, automation, and containerization.
To ensure smooth operations when dealing with mission-vital workloads, it is crucial to implement a coexistence strategy that suits the specific use case and technological circumstances. This article focuses on a data synchronization approach for coexistence, which requires phased rollout, and explains how the AWS Data Migration Service was utilized to continuously synchronize data from an on-premise relational database to Amazon DynamoDB on the AWS cloud. The article also covers the challenges faced and lessons learned during the implementation process.
As part of a major digital transformation initiative, the development team was responsible for the complete modernization (rewrite) of an existing legacy system consisting of multiple mission-vital, mission-critical, business-critical, and business-vital workloads.
The term "Mission Vital" is assigned to a workload that, in most cases, maintains an availability of 99.999% while also having a near-zero recovery point objective (RPO) and recovery time objective (RTO). On the other hand, "Mission Critical" is used to describe a workload that usually requires 99.95% availability, with a near-zero RPO and an RTO of up to four hours.
The legacy solution utilized a relational database and supported multiple web applications, adapters, and mobile applications.
In order to mitigate disruptions to the existing applications, we did a canary deployment introducing the new application in a few pilot locations prior to its full-scale release across all locations.
However, this approach presented an additional challenge in terms of coexistence, as the older version of the application continued to update the on-premise system while the new version interacted with the cloud during the transitional period.
Moreover, various downstream and upstream processes from other business domains were reliant on the on-premise database and services.
As a result, the primary challenge was to construct a robust coexistence system that did not compromise the latency, performance, security, or reliability of the solution and its dependent systems throughout the coexistence period.
After several architectural considerations, it was concluded to establish one-way data synchronization to offload the read calls from the source RDBMS database to the cloud DynamoDB instance.
In one-way data synchronization, data is transferred from a source system to a target system, with no modifications or updates made in the target system. As a result, the data in the target system is identical to the data in the source system, and any changes made in the target system do not get reflected back to the source system. There are multiple methods to implement one-way synchronization, including file transfers, messaging systems, or database replication. In this specific solution, database replication was utilized through the use of change data capture technique.
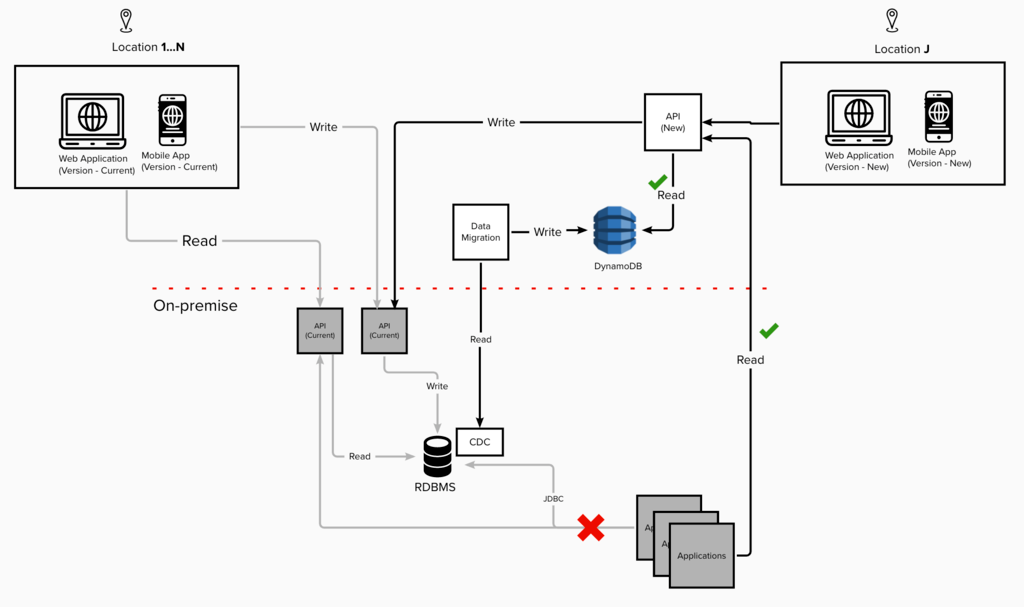
Figure 1: Coexistence Layer
As explained in Figure 1, during the coexistence period legacy version of the mobile application will continue to leverage existing solutions while the new version of the mobile application will leverage the new APIs serving the data from the DynamoDB database for read and on-premise API for the write operation as a passthrough.
The article mainly focuses on the one-way sync and does not delve into the challenges faced for updating the data on-premise.
The dependent application will read data from the cloud database and continue to write to the on-premise database using wrapper API on the cloud.
Challenges
The key challenges that were encountered while migrating the data from on-premise RDBMS to cloud DynamoDB (NoSQL) are:
- Resource Constraints on the on-premise RDBMS: The on-premise RDBMS was strained on resources and could not be scaled.
- Data merging and denormalization challenges: DynamoDB is denormalized and does not support table joins. Although materialized views can help join tables, it does put additional strain on the resources.
- Data Transformation Challenges: Challenges related to data type conversion and data transformation needed for single table design (Dynamo DB single table design as explained by Alex DeBrie "The What, Why, and When of Single-Table Design with DynamoDB." Alex DeBrie, 22 October 2019).
- Latency and performance issues imposed by the network: The location of the data center and the selected AWS region imposed different regional latency issues.
- Data Security in Transit and at Rest: The data classification was confidential and hence needs to be secure during transit and rest and should not leave the customer network.
- DMS Task Failure and Recovery: DMS tasks can fail for various reasons, including connectivity, and because of the mission vital and critical nature of the workload, the solution needs to ensure minimum manual intervention.
- Data Validation: DMS does not support out-of-the-box data validation for data migrated from RDBMS to NOSQL databases.
- Cost Implications: Since the coexistence system may last for several months, the solution needs to be cost-effective as we need to maintain data in multiple databases.
Solution
The AWS Data Migration Service (AWS DMS) was utilized to implement the solution. During the initial load, the DMS task retrieves data from the on-premise RDBMS and modifies the cloud-based DynamoDB instance accordingly. Once the full load is complete, any subsequent modifications to the data are captured through the RDBMS CDC mechanism.
Resource Constraints, Data Transformation, Merging, and Denormalization
-
Materialized View for Aggregation: In situations where a simple conversion from a table to a DynamoDB entity is necessary, we can make use of the materialized view feature, coupled with the DMS task's object mapper, to facilitate column mapping to the intended structure. However, it is essential to note that although materialized views can be useful for combining information from normalized tables to create a denormalized view, this approach can have an impact on the CPU, storage, and memory resources of the source database.
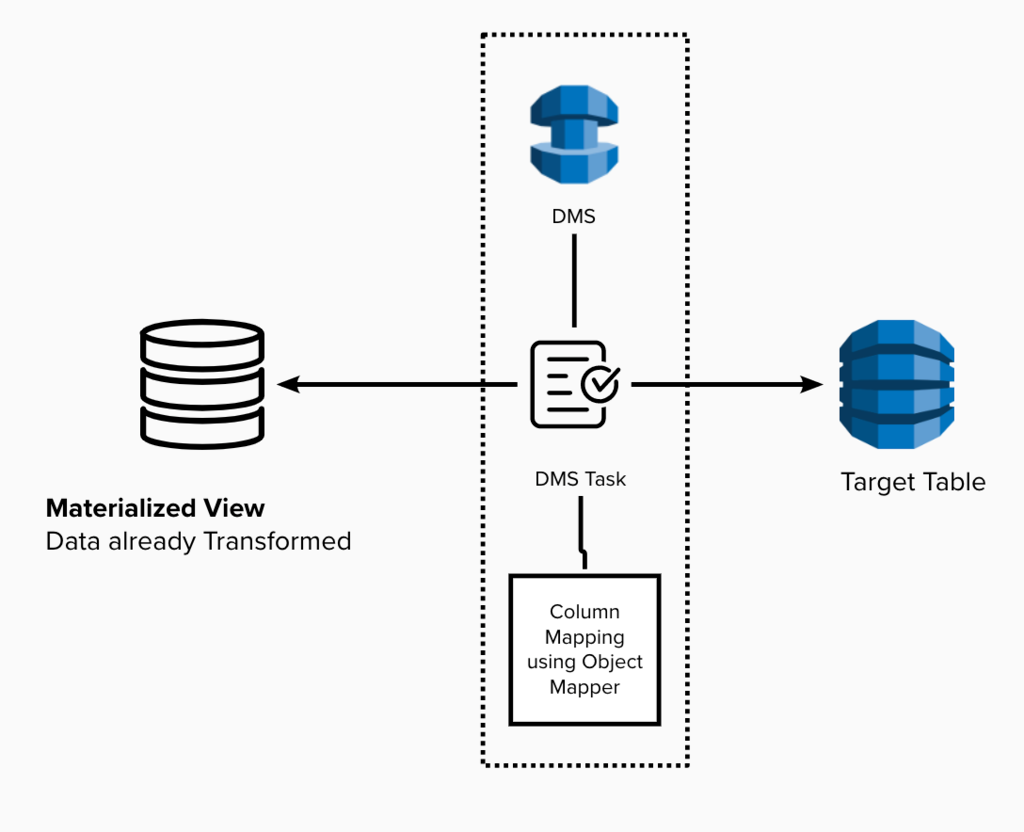
Figure 2: One-way sync using materialized view for aggregation.
As one of the challenges we encountered involved resource constraints on the on-premise RDBMS, hence the materialized view approach could not be utilized.
-
Data Transformation using Transformation Rule type: In scenarios that involve a straightforward conversion from a table to a DynamoDB entity, which may include tasks like converting date formats, changing data types, and mapping columns, the solution utilized DMS tasks that were configured with transformation rules.
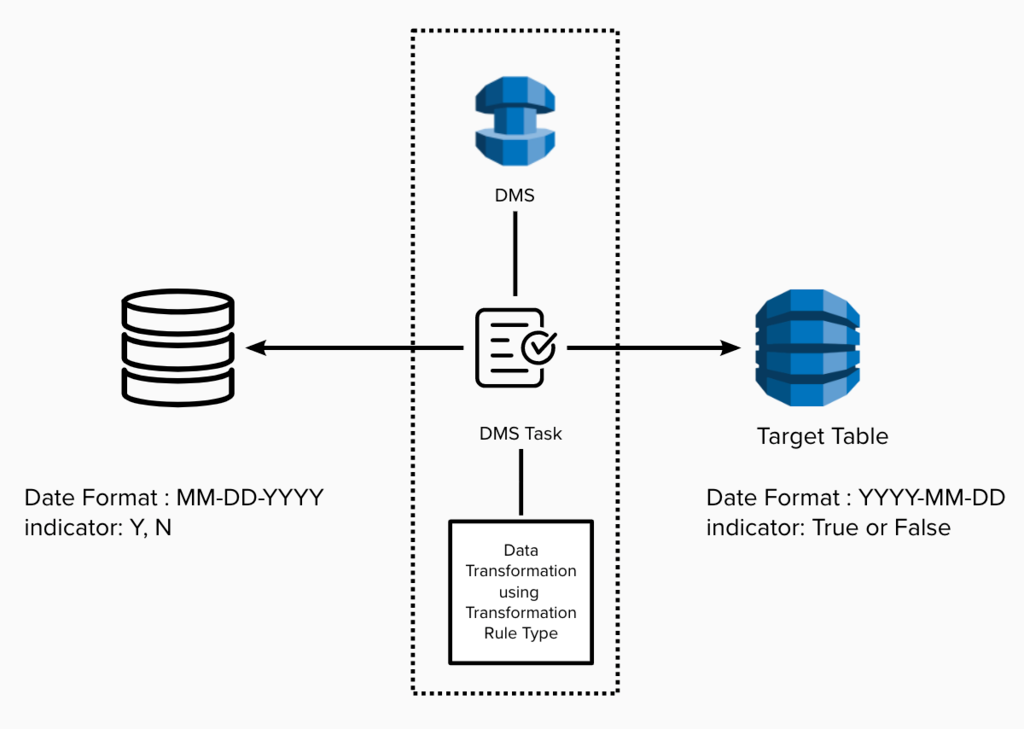 Figure 3: One-way sync using DMS Task Transformation rule type.
Figure 3: One-way sync using DMS Task Transformation rule type.
Suppose data transformation is more intricate and involves merging, denormalizing, and transforming data from multiple tables before storing it in a DynamoDB table. In that case, the solution utilizes an intermediate DynamoDB table, along with a DynamoDB Stream and Lambda, as illustrated in the diagram below.
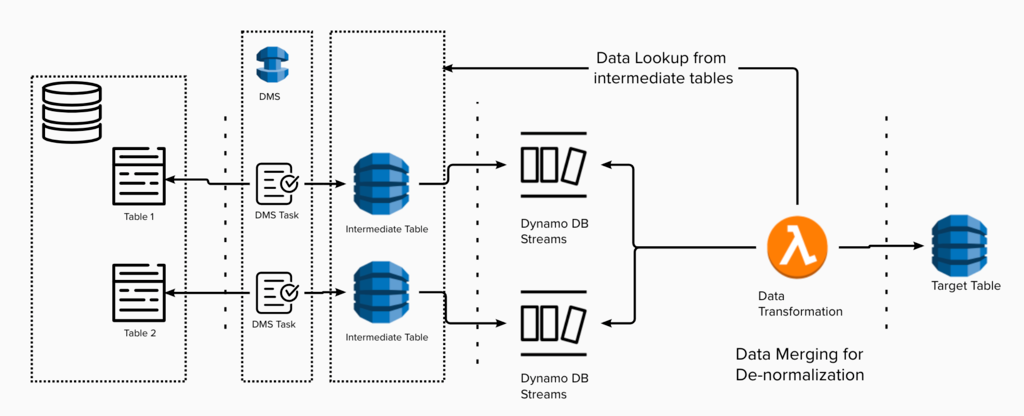 Figure 3: One-way sync using intermediate tables.
Figure 3: One-way sync using intermediate tables.
While DynamoDB offers an option to utilize Kinesis Data Stream for this purpose, it comes with additional costs, and data ordering is not guaranteed.
Latency and Performance Issues Imposed By Network
The current solution leveraged two clusters of Active/Passive deployment strategy with near zero RPO within a data center.
The proposed solution was to leverage a similar Active/Passive DR strategy but with two different AWS regions, with the primary as the region closer to the data canter on-premise.
To avoid load on the primary on-premise database instance, the solution leveraged the passive database cluster.
The solution leveraged AWS Direct Connect, Transit Gateway, and Customer Gateway to establish a secure connection between the on-premises data center and AWS Account. It also uses DynamoDB global tables to support a 2-region Active/Passive DR strategy with near zero RPO.
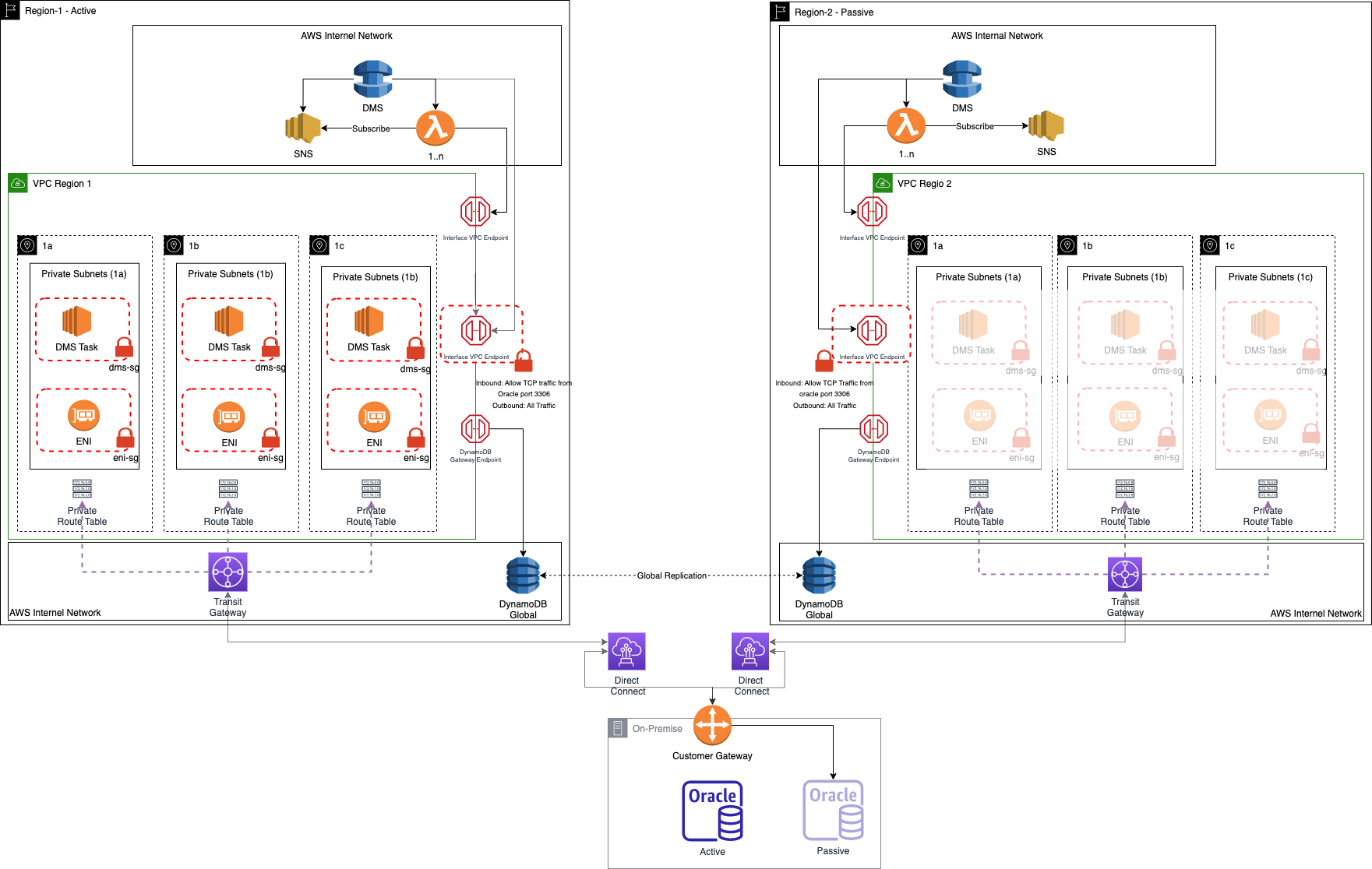
Figure 4: 2 Region Active Passive DR strategy.
Data Security in Transit and at Rest
The data stored in DynamoDB was encrypted at rest using an AWS Customer managed key, while data in transit from AWS DMS was encrypted using TLS v1.2 encryption. Moreover, to encrypt data in transit from an on-premises source RDBMS instance, a server-side certificate was employed.
AWS DMS uses AWS Key Management Service (AWS KMS) encryption keys to encrypt the storage used by the replication instance (compute) and its endpoint connection information.
Furthermore, since AWS DMS is a managed service that needs compute instances, the solution associated the DMS task with the subnets within VPC. This allowed the solution to utilize the AWS Private Link architecture for securely connecting to the DMS service's private endpoint to create replication instances within the VPC subnets.
Failover With Recovery From Checkpoint
There are several factors that can lead to the failure of AWS DMS tasks, including incorrect configuration, connectivity problems, permission issues, data format inconsistencies, replication errors, limited resources, and software glitches. To prevent such issues, it is crucial to ensure proper configuration of all necessary parameters, establish dependable network connectivity, provide sufficient resources for the replication instance, and keep the DMS software up-to-date. In addition, ongoing monitoring and timely troubleshooting are essential to ensure a smooth migration process.
The solution leveraged DMS Multi Region Active – Passive DR strategy with Hot Standby with DynamoDB global tables.
Since the solution used Dynamo DB global tables, the API traffic supported will be active/active.
As explained in the diagram below:
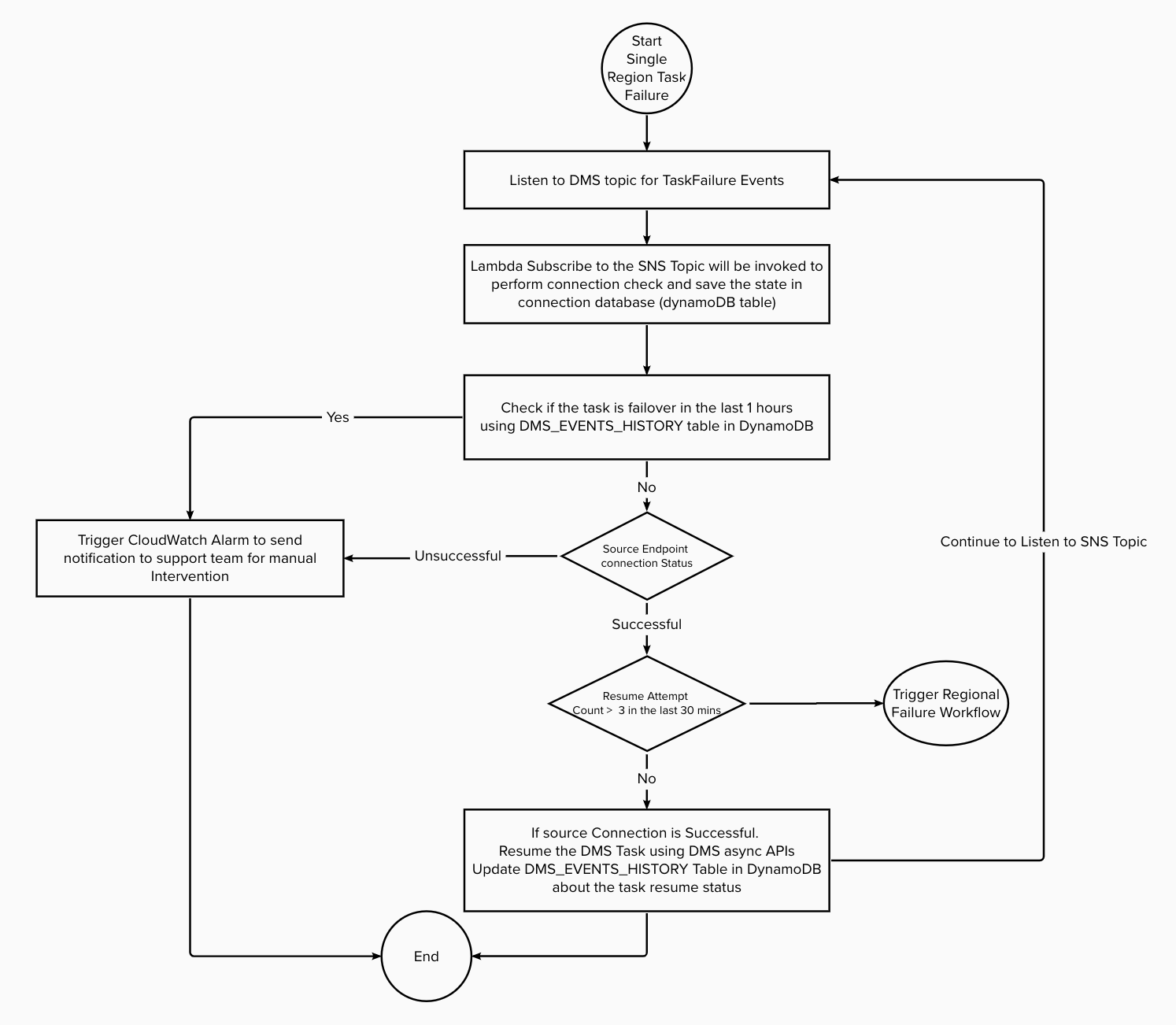
Figure 5: DMS Task Failure within the region.
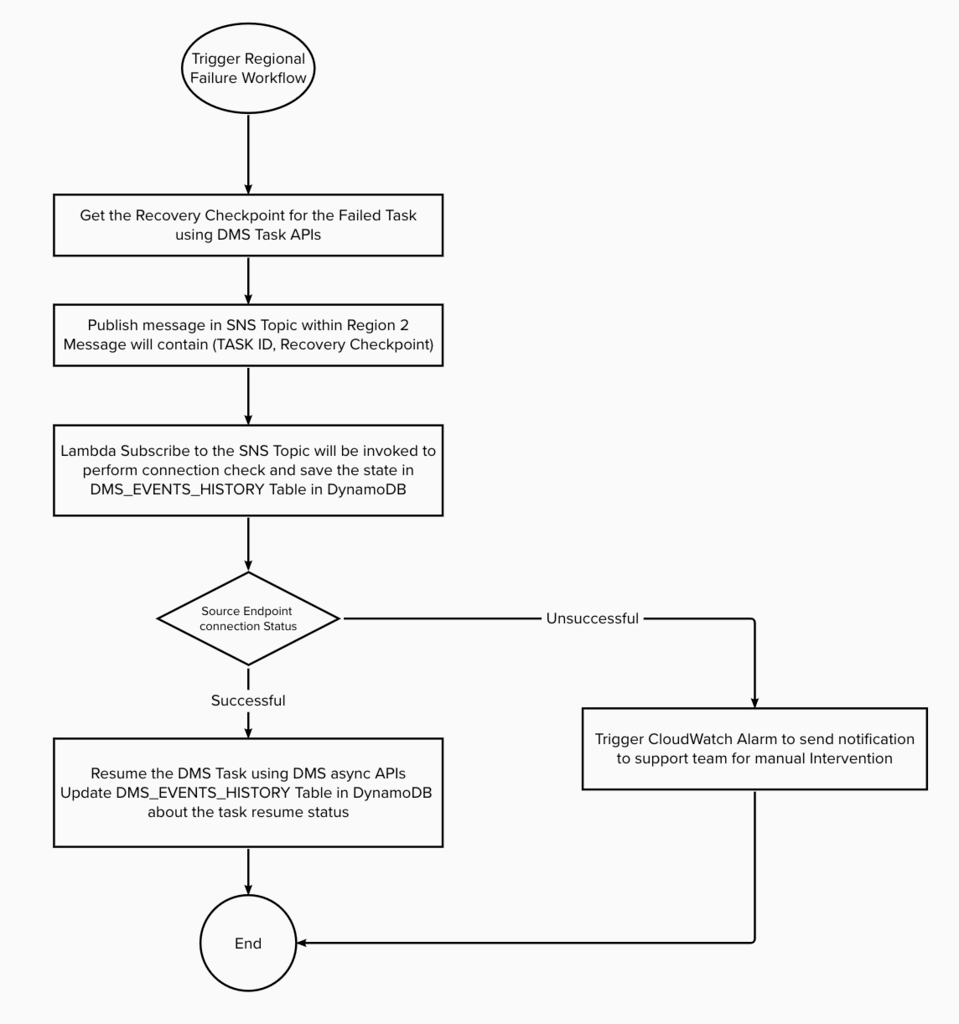 Figure 6: DMS Task Failover to the second region.
Figure 6: DMS Task Failover to the second region.
-
Connectivity failures: The failure of the DMS task may result from connectivity problems between the replication instance and the endpoints, such as when the source is an on-premise RDBMS, and the target is DynamoDB, or between the source and target endpoints themselves. To avoid such issues, it is crucial to maintain stable network connectivity and ensure that all necessary ports are open. The solution used a lambda function that subscribes to an SNS topic set up with AWS DMS to listen for Task failure events. If the task fails, the solution will use the AWS DMS APIs to verify the connection status of both endpoints and store the information in the DMS_Event_History table in DynamoDB. Since a failed source connection cannot be restored automatically, the solution will generate a CloudWatch alert to inform the support team.
-
DMS Task failure due to replication errors, resource limitations, and software issues: Errors in replication may occur due to problems with the replicated data or schema. Furthermore, AWS DMS tasks may fail when there is insufficient memory, CPU, or disk space available to the replication instance to handle the workload. Additionally, tasks can fail due to issues with the DMS software itself. In such cases, the solution will use a lambda function that subscribes to an SNS topic configured with AWS DMS to listen for task failure events. The solution will then attempt to resume the DMS task using DMS APIs at least three times using the recovery checkpoint identifier before failing over to the second region. To track each retry attempt, the solution will record it in the DMS_Event_History table in DynamoDB.
-
Lambda errors during data insert in target DynamoDB instance: The solution utilized the "Split Batch on Error" feature of DynamoDB streams to manage Lambda errors. This feature is designed to handle errors that may arise while processing stream records in bulk. When enabled, it splits batches of records into smaller batches if an error occurs during processing. Each smaller batch is then individually retried to avoid the failure of the entire batch due to a single error. This results in more effective error handling and better retrying of failed records.
Data Validation
As DynamoDB was used as the target database in the solution, there was no ready-made solution available. Therefore, custom logic was employed to verify the data across different tables in both the source and target. This will be detailed in a future article.
Performance and Availability
Here are some suggestions for enhancing the performance of AWS DMS tasks:
- First, optimize source and target databases: Any changes to optimizing queries, indexes, and other database settings on the source database were not options for our use case.
- Use larger replication instances with sufficient memory and CPU resources: The solution used DMS R5 2X Large with 8 Virtual CPUs and 64 GB RAM for an initial load of 200 million records which migrated the 450K records per min per task. The CPU utilization was 90% for the initial load. For CDC, the solution leveraged less memory. Based on the number of transactions, the replication instance needs to be optimized.
- Implement multi-AZ replication: The solution leverages a Multi-AZ replication instance to improve availability.
- Implement parallel task execution: AWS DMS supports parallel task execution, which can improve performance by dividing the workload into smaller chunks that can be executed in parallel. "ParallelLoadThread" and "ParallelLoadBufferSize" can be tweaked to improve performance. In our case, the source RDBMS database was partitioned by date; hence by using parallel load threads, the DMS task performance improved.
- Adopt bulk data loading: The solution employed lambda, which used bulk write and bulk update using PartiQL to update the final target DynamoDB instance.
- Optimize network settings: The solution was limited by the physical location of the on-premise instance and AWS regions selected, and the network bandwidth purchased by the company for the AWS Direct Connect.
Cost
Since the solution was used to build a temporary coexistence layer during cloud modernization, the operation cost was important but not a major concern for the business in our case. But in general, the modernization team has to plan for additional expenses based on the duration of this coexistence period.
Conclusion
The article details a working solution to offload read calls to the cloud to support phased rollout with some additional cost and minimal network latency to replicate the data between the on-premise and cloud databases. The current solution does not cater to a near real-time update that needs replication within milliseconds.
Opinions expressed by DZone contributors are their own.
Comments