My Sentiments, Erm… Not Exactly
In this article, we look at how Hugging Face and GPT-3 perform classifying a potentially ambiguous sentence, along with little help from AllenNLP’s semantic role labeling.
Join the DZone community and get the full member experience.
Join For FreeThis article is an excerpt from the book Transformers for Natural Language Processing, Second Edition. This edition includes working with GPT-3 engines, more use cases, such as casual language analysis and computer vision tasks, and an introduction to OpenAI's Codex.
Have a look at the following sentence:
Though the customer seemed unhappy, she was, in fact, satisfied but thinking of something else at the time, which gave a false impression.
Applying sentiment analysis with the Hugging Face transformers, Microsoft/MiniLM-L12-H384-uncased and RoBERTa-large-mnli labeled the sentence “neutral.”
But is that true?
Labeling this sentence “neutral” bothered me. I was curious to see if OpenAI GPT-3 could do better. After all, GPT-3 is a foundation model that can theoretically do many things it wasn’t trained for.
When I read the sentence closely, I could see that the customer is she. When I looked deeper, I understood that she is in fact satisfied. I decided not to try models blindly until I reached one that works. Trying one model after the other is not productive.
I needed to get to the root of the problem using logic and experimentation. I didn’t want to rely on an algorithm that would find the reason automatically. Sometimes we need to use our neurons!
Could the problem be that it is difficult to identify she as the customer for a machine? Let’s ask AllenNLP’s SRL BERT.
Investigating With SRL
I first ran She was satisfied using the Semantic Role Labeling interface on https://demo.allennlp.org/.
The result was correct:

The analysis is clear in the frame of this predicate: was is the verb, She is ARG1, and satisfied is ARG2.
We should find the same analysis in a complex sentence, and we do:
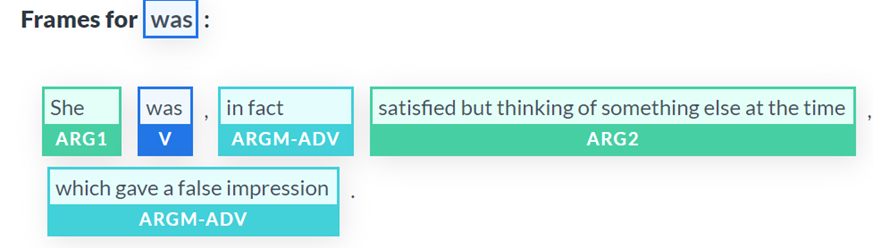
Satisfied is still ARG2, so the problem might not be there.
Now, the focus is on ARGM-ADV, which modifies was as well. The word false is quite misleading because ARGM-ADV is relative to ARG2, which contains thinking.
The thinking predicate gave a false impression, but thinking is not identified as a predicate in this complex sentence. Could it be that she was is an unidentified ellipsis?
We can quickly verify that by entering the full sentence without an ellipsis:
Though the customer seemed unhappy, she was, in fact, satisfied but she was thinking of something else at the time, which gave a false impression.
The problem with SRL was the ellipsis again. We now have five correct predicates with five accurate frames.
Frame 1 shows that unhappy is correctly related to seemed:

Frame 2 shows that satisfied is now separated from the sentence and individually identified as an argument of was in a complex sentence:

Now, let’s go straight to the predicate containing thinking, which is the verb we wanted BERT SRL to analyze correctly. Now that we suppressed the ellipsis and repeated she was in the sentence, the output is correct:
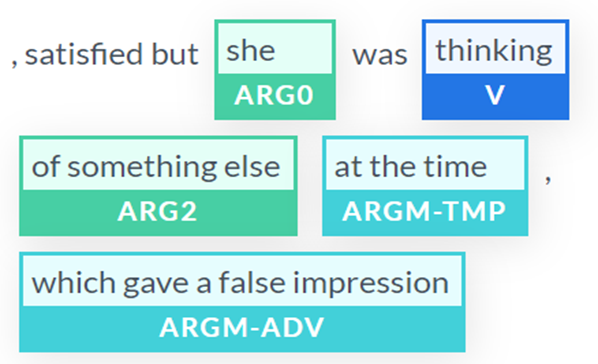
- The word
falseis a confusing argument for an algorithm to relate to other words in a complex sentence - The ellipsis of the repetition of
she was
Before we go to GPT-3, let’s go back to Hugging Face with our clues.
Investigating With Hugging Face
Let’s try the DistilBERT-base-uncased-finetuned-sst-2-english model.
We will investigate our two clues (the ellipsis of she was and the presence of false in a positive sentence.
The Ellipsis of She Was
We will first submit a full sentence with no ellipsis:
Though the customer seemed unhappy, she was, in fact, satisfied but she was thinking of something else at the time, which gave a false impression
The output remains negative:
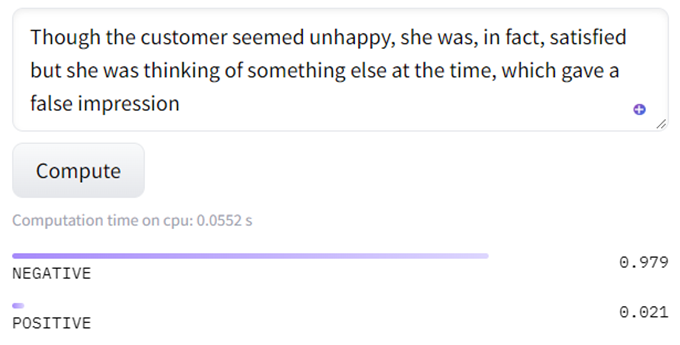
The Presence of False in an Otherwise Positive Sentence
We will now take false out of the sentence but leave the ellipsis:
Though the customer seemed unhappy, she was, in fact, satisfied but thinking of something else at the time, which gave an impression
Bingo! The output is positive:
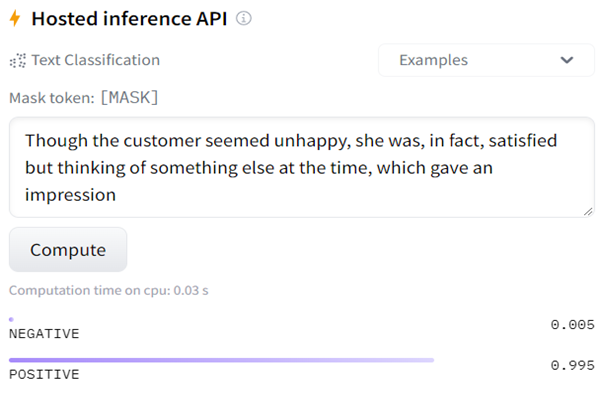
We know that the word false creates confusion for SRL if there is an ellipsis of was thinking. We also know that false creates confusion for the sentiment analysis Hugging Face transformer model we used.
Can GPT-3 do better? Let’s see.
Investigating With the GPT-3 Playground
Let’s use OpenAI’s example of an Advanced tweet classifier and modify it to satisfy our investigation in three steps:
Step 1: Showing GPT-3 What we Expect
Sentence: “The customer was satisfied”
Sentiment: Positive
Sentence: “The customer was not satisfied”
Sentiment: Negative
Sentence: “The service was good”
Sentiment: Positive
Sentence: “This is the link to the review”
Sentiment: Neutral
Step 2: Showing it a Few Examples of the Output Format We Expect
1. “I loved the new Batman movie!”2. “I hate it when my phone battery dies”3. “My day has been good”4. “This is the link to the article”5. “This new music video blew my mind”
Sentence sentiment ratings:
1: Positive2: Negative3: Positive4: Neutral5: Positive
Step 3: Entering Our Sentence Among Others (Number 3):
1. “I can’t stand this product”
2. “The service was bad!”
3. “Though the customer seemed unhappy, she was, in fact, satisfied but thinking of something else at the time, which gave a false impression”
4. “The support team was lovely”
5. “Here is the link to the product.”
Sentence sentiment ratings:
1: Negative
2: Positive
3: Positive
4: Positive
5: Neutral
The output seems satisfactory since our sentence is positive (number 3). Is this result reliable? We could run the example here several times. But let’s go down to the code level to find out.
GPT-3 Code
We just click on View code in the playground, copy it, and paste it into a notebook. We add a line to only print what we want to see:
response = openai.Completion.create(
engine=“davinci”,
prompt=“This is a Sentence sentiment classifier\nSentence: \”The customer was satisfied\”\nSentiment: Positive\n###\nSentence: \”The customer was not satisfied\”\nSentiment: Negative\n###\nSentence: \”The service was good\”\nSentiment: Positive\n###\nSentence: \”This is the link to the review\”\nSentiment: Neutral\n###\nSentence text\n\n\n1. \”I loved the new Batman movie!\”\n2. \”I hate it when my phone battery dies\”\n3. \”My day has been good\”\n4. \”This is the link to the article\”\n5. \”This new music video blew my mind\”\n\n\nSentence sentiment ratings:\n1: Positive\n2: Negative\n3: Positive\n4: Neutral\n5: Positive\n\n\n###\nSentence text\n\n\n1. \”I can’t stand this product\”\n2. \”The service was bad!\”\n3. \”Though the customer seemed unhappy she was in fact satisfied but thinking of something else at the time, which gave a false impression\”\n4. \”The support team was lovely\”\n5. \”Here is the link to the product.\”\n\n\nSentence sentiment ratings:\n”,
temperature=0.3,
max_tokens=60,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=[“###”]
)
r = (response[“choices”][0])
print(r[“text”])
The output is not stable, as we can see in the following responses.
Run 1: Our Sentence (Number 3) Is Neutral:
1: Negative
2: Negative
3: Neutral
4: Positive
5: Positive
Run 2: Our Sentence (Number 3) Is Positive:
1: Negative
2: Negative
3: Positive
4: Positive
5: Neutral
In run 3, our sentence is positive, and in run 4, our sentence is negative.
Conclusions
This leads us to the conclusions of our investigation:
- SRL shows that if a sentence is simple and complete (no ellipsis, no missing words), we will get a reliable sentiment analysis output.
- SRL shows that if the sentence is moderately difficult, the output might, or might not, be reliable.
- SRL shows that if the sentence is complex (ellipsis, several propositions, many ambiguous phrases to solve, and so on), the result is not stable and therefore not reliable.
The conclusions of the job positions of developers in the present and future are:
- Less AI development will be required with Cloud AI and ready-to-use modules.
- More design skills will be required.
- Classical development of pipelines to feed AI algorithms, control them, and analyze their outputs will require thinking and targeted development.
Published at DZone with permission of Denis Rothman. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments