NLP Features That Are Criminally Overlooked: The Case for SAO
NLP solutions are based on Machine Learning algorithms, and ML rarely delivers great accuracy. Try a not-so-popular NLP tool: SAO (Subject-Action-Object).
Join the DZone community and get the full member experience.
Join For FreeIn the reading of Natural Language Processing (NLP) applications, we inevitably encounter two main features in action, Categorization and Extraction, and learn how those can be manipulated in so many different ways to effectively address use cases that involve free-form text and the retrieval of information from it. We also hear a lot about Sentiment (which technically is not a separate feature but rather a specialization of the previous two). Finally, we have POS-tagging, which is only occasionally mentioned outside of deeply technical articles for linguists and NLP professionals.
We don’t hear much about other NLP capabilities, and this is mainly because often, depending on how an NLP engine is designed, features beyond Categorization and Extraction are not present at all. Specifically, many NLP solutions today are based on Machine Learning algorithms, and ML rarely delivers great accuracy in problems that require both elevated precision and super-fine identification. Then again, some of these capabilities are incredibly useful, in fact sometimes even the only way to address a particular challenge. In the following, I make the case for one of these not-so-popular NLP tools: SAO (Subject-Action-Object).
(all screenshots below taken on https://try.expert.ai)
I’ll go through a list of some of the benefits exclusive to a SAO functionality, showing related examples as a backdrop.
Benefit #1, AKA I’m only interested in one of the actors: I’m indexing documents to keep track of facts and events, but in my typical search I’m only interested in one of the entities involved in a specific event, everything else would just be noise to me.
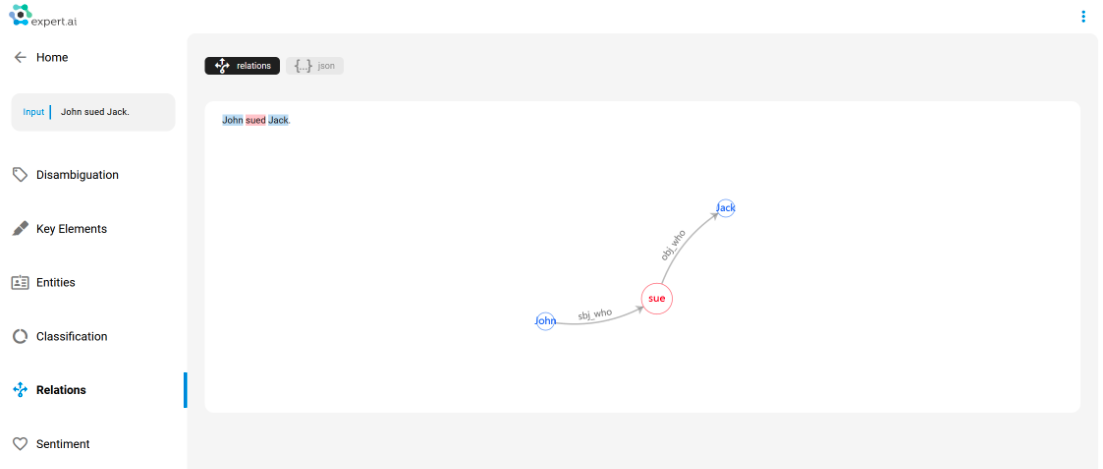
In the example shown above, “John sued Jack”, a Categorization effort might classify this document as belonging to the “Legal” domain, and even more specifically tell us it is about “Lawsuits”; just as informatively, an Extraction algorithm will likely retrieve entities such as “John” and “Jack”. This is enough to deduce that John and Jack are involved in a lawsuit, what we are still missing is the information about who sued whom. This might sound like small potatoes in an example like this one, but if I’m indexing millions of documents with the sole purpose of searching through them, it’s not really useful to only be capable of searching for “John” or “Jack” or “Lawsuits” (or even a combination of all of them) and find ourselves with maybe thousands of results. Let’s say we only want to review documents whose arguments detail Jack being sued, we should be able to look up exactly that, and SAO is the key to this problem.
Benefit #2, AKA I’m only interested in one of the actions: in looking for actionable data, I’m not interested in specific entities, but rather a subset of those that are connected to one specific event
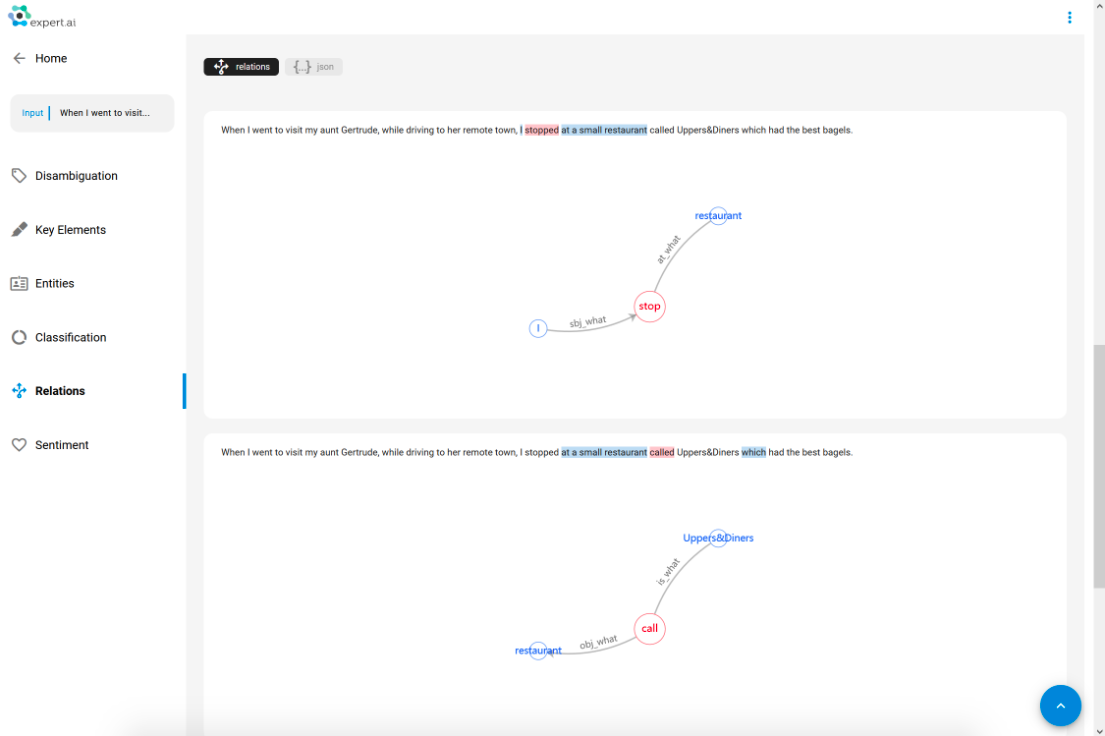
In the sentence above (“When I went to visit my aunt Gertrude, while driving to her remote town, I stopped at a small restaurant called Uppers&Diners which had the best bagels.”) there are several actions happening, visiting an aunt and eating at a restaurant, and multiple entities, a person, a town, an establishment, food. Now, let’s imagine that we want to structure the information we have in this piece of content (for search purposes, recommendation, analytics, etc.) by means of Categorization or Extraction or even Sentiment; well, it is no use to me to know, for example, that the statement involving delicious bagels is associated to a name like Gertrude (the aunt); if I’m tracking, for instance, millions of social media posts to recommend a good restaurant to people looking for specific food then what I need is to pinpoint the name of the restaurant and only that. SAO can make that connection explicit and structured.
Benefit #3, AKA I want to know who did what: I’m looking for specific events, and I do want to keep track of all the parties involved, but it is relevant to know who exactly executed a certain action and who, instead, suffered it.
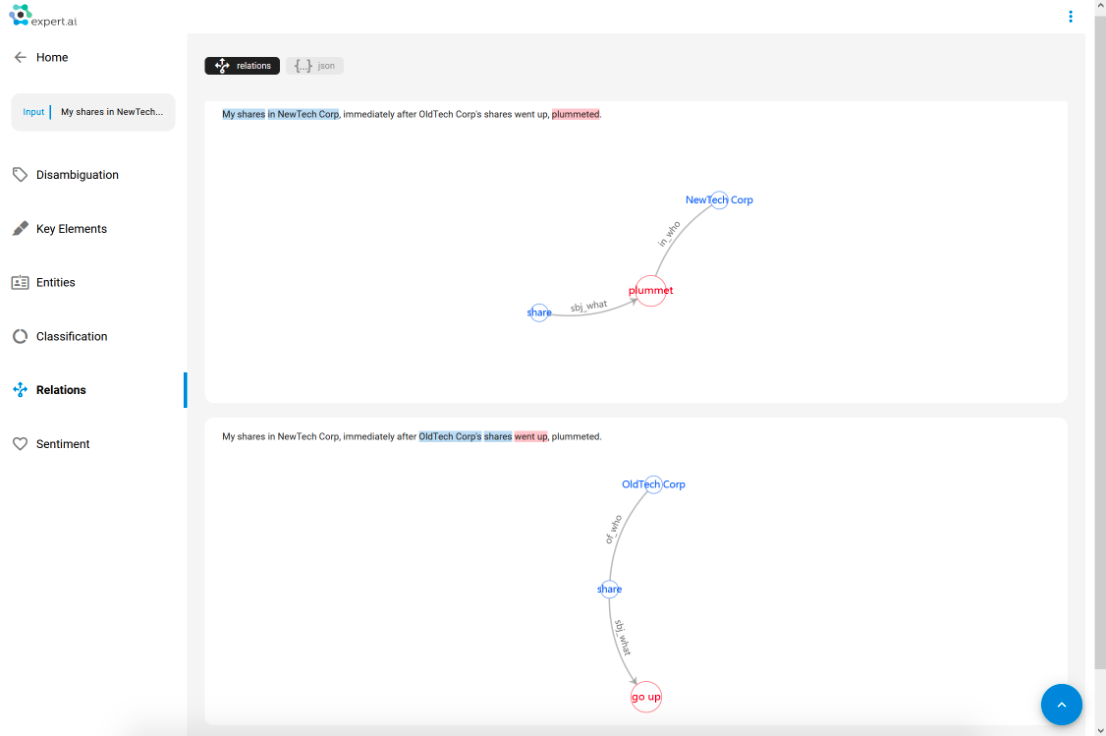
This last one might sound like Benefit #2 (or, in a way, a combination of that and Benefit #1), which should come to no surprise since we are ultimately talking about the same SAO functionality, that is the ability to recognize who’s involved in an event and what role they had (and, as a teaser, I can add that SAO can be combined with other NLP features to further detail your data intelligence by, for instance, also identifying why somebody did something); but, as they say, the devil’s in the details, and each one of these benefits often translates to a completely different and separate need or business case.
In this last text (“My shares in NewTech Corp, immediately after OldTech Corp’s shares went up, plummeted.”), which also comes with a less-than-straightforward sentence structure (though not uncommon in finance-related articles and research), two different corporations and two different actions are mentioned; the key problem here is likely apparent to everyone: those two actions are opposite, and it matters a great deal to know which company’s shares went up and which went down. Again, we are not talking about contexts where we have a couple of statements here and there (which requires no automation or Natural Language Understanding technology), but rather one in which we’re tracking unstructured information by indexing hundreds of lengthy documents, maybe analyzing tens of thousands of articles per day (or millions of tweets).
In such a scenario, I really can’t build any productive service around the identification of the nature of a document (Categorization) or the names of the parties involved (Extraction). Perhaps my interest is knowing how many times NewTech’s share price went up last year, and I can’t just look for “NewTech” and have to browse through thousands of documents that may often talk about something entirely different. If you have a SAO functionality at your disposal, you have access to the level of information granularity you require in such a use case.
What Else
At this point, for anyone reading this who didn’t know much about SAO before, it should be quite apparent that the benefits listed above are really just scratching the surface: SAO is about understanding what’s truly happening in a document, which is at the center of language and how we express our thoughts and opinions, therefore I’m sure nobody would be surprised to know that there’s so much more you can do if you have this impressive little tool in your arsenal.
I’ll just offer one example, shifting our context to a scenario where we’re dealing with aggregated data and sophisticated needs around analytics: building a knowledge graph. This can be defined as the new(-ish) trend in Smart Data practices. From the origins (Big Data) to recent times (Intelligent Discovery), the objective of technologies such as NLP has been to retrieve hidden, extremely valuable, information but also find better ways to navigate this sizable amount of additional input we now have.
A Knowledge Graph is the smoothest way. Clean, sorted, and shaped in the image of a company’s most pressing questions, a KG offers a way to connect the dots and quickly extract relations that are not apparent or even possible to deduce thru classic means (that is, via large quantities of manual search). SAO returns its findings in the form of triples (data points in groups of 3, like Subject-Action-Object), which can be easily organized in a triple store (most companies already have one as part of their NOSQL database). Triples are the bread and butter of a knowledge graph.
I’ve personally seen up close this type of project, like a renowned Data Management organization planning an effective view of people and businesses from all around the world, but also a Life Sciences company analyzing clinical trials to build a graph around drugs, side effects, and mechanisms of action. This is one of those NLP projects that really feels magical, once you get to see all that information, once scattered across millions of documents, neatly sorted, easy to find, and, most importantly, all inter-connected (which is the huge plus of knowledge graph).
Summing It Up
NLP professionals are problem solvers, and they know their subject matter very well, so it is often the case that they will use whatever tool they have at their disposal to address any challenge; and they will very likely deliver the best result possible with that tool, but inevitably this solution won’t reach the accuracy that it could have if it had adopted proper tools for the given problem.
I’ve worked with many clients that, in the process of a complete overhaul of their data intelligence and knowledge management practices, had hired expert consultants to pick a fitting technology partner and deal with these issues, therefore compensating for their lack of understanding of nuances like the ones described here. An expert will know the best way to address a problem, and will also know what’s available out there, including the strengths and weaknesses of every technology.
Join the conversation at https://community.expert.ai
Published at DZone with permission of Filiberto Emanuele. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments