Optimizing Software Performance for High-Impact Asset Management Systems
Performance isn’t optional in government tech. Event-driven caching with Rust cut latency by 65%, proving that architecture can drive impact.
Join the DZone community and get the full member experience.
Join For FreeMy extensive experience building complex software systems has shown that performance optimization is often the deciding factor between operational success and failure, especially in large-scale environments managing millions of interconnected components. Unlike consumer-facing apps, enterprise asset management platforms must meet rigorous demands: high concurrency, guaranteed data integrity, and real-time access to mission-critical information.
The Problem With Traditional Systems
Conventional enterprise systems typically rely on synchronous APIs and relational databases. While this setup can support simple queries under moderate load, it struggles with the complexity and scale of modern asset management needs. When tens of thousands of users query complex bill of materials (BOMs), multi-level part hierarchies, or conditional attributes at once, latency becomes inevitable.
In one such system I encountered, performance bottlenecks directly impacted critical workflows, procurement delays, engineering change order (ECO) lag, and inaccurate inventory snapshots. The problem wasn’t in the logic but in the architecture.
Introducing a Hybrid Architecture: Event-Driven + In-Memory
To overcome these limitations, I implemented a hybrid architecture that merges event-driven design with in-memory data pipelines. This shift was not just about improving query speed; it involved fundamentally rethinking how data is delivered to users during high-demand scenarios, especially in asset-intensive enterprise environments where milliseconds matter.
Rather than querying the backend with each user request, we identified the most frequently accessed data, such as part specifications, inventory levels, and multi-level BOM relationships, and proactively loaded it into an in-memory cache. Asset updates, including changes to availability, revisions, or specification details, triggered lightweight events through a centralized message bus. These events asynchronously refreshed the cache across services, ensuring data consistency while eliminating redundant backend calls.
This transformation enabled the system to scale efficiently and remain stable during periods of peak usage. Engineering teams could validate designs by reviewing part dependencies without delay. Procurement officers were able to monitor supply chain timelines in real time, and operations managers gained the ability to conduct audits with immediate data access. Additionally, minimizing reliance on transactional databases reduced deadlocks, improved concurrency throughput, and made system performance more predictable and reliable across departments.
Why Rust?
We chose Rust to implement the caching infrastructure due to its unique combination of memory safety and high concurrency support. Unlike C++ or Java, Rust’s ownership model eliminates entire classes of memory errors at compile time, an essential feature when handling mission-critical data in government and industrial environments.
Here’s a simplified version of how the caching mechanism worked:
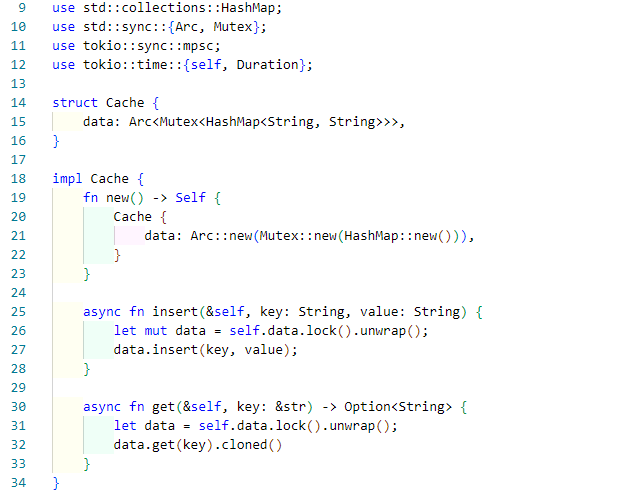

This Rust snippet illustrates a thread-safe cache using read-write locks. Updates happen in response to system events, while reads are nearly instantaneous. This pattern allows thousands of threads to access data concurrently with minimal blocking.
Real-World Results
Let’s revisit the manufacturing ERP platform I mentioned earlier. Its original configuration pulled BOMs and part configurations via nested API calls. These queries were dynamically constructed, often traversing multiple systems and databases. During ECOs or audit cycles, performance predictably tanked. Even simple queries could take several seconds to complete, and some user sessions would time out altogether.
After migrating to the event-driven, in-memory cache, the difference was stark. Query response times dropped by 65%, database usage decreased by 30%, and backend timeouts during peak hours disappeared entirely. Departments that previously worked with stale or partial data due to lag could now operate with real-time precision.
The impact was not just technical, it translated into faster decision-making cycles, improved supplier coordination, and shorter time-to-approval for engineering changes. Operations teams no longer had to wait minutes to retrieve part specs or dependency chains, which accelerated every downstream workflow from procurement to compliance.
Moreover, these improvements didn’t require more hardware or bloated cloud infrastructure. They came from smarter design decisions that made better use of existing resources. In fact, by reducing compute strain and network latency, we were able to lower cloud spend by over 20%, reinforcing the value of architectural optimization as both a performance and cost-efficiency strategy.
Performance as Architecture
These optimizations weren’t one-off wins, they stemmed from a broader mindset shift. In enterprise software, performance is not a feature you bolt on after launch. It’s something that needs to be baked into the architecture from day one.
The traditional mindset, wait for the user to ask, then go get the data, is reactive and brittle. Modern platforms must anticipate needs and provide the answers before the questions are asked. That’s where event-driven systems shine.
They don’t just react to user input, they listen to changes, process updates in real time, and keep downstream systems in sync. Combined with caching layers that are intelligent, adaptive, and resilient, the entire ecosystem becomes far more performant and scalable.
Conclusion
Optimizing enterprise platforms, especially in asset-intensive industries, requires looking beyond code-level tweaks. It means adopting architectural patterns that prioritize responsiveness, resilience, and efficiency. By combining event-driven caching with a memory-safe language like Rust, I’ve helped systems transform from sluggish and reactive to fast and predictive.
In an era where real-time decisions govern everything from supply chains to public infrastructure, the cost of delay is too high to accept. The future of enterprise performance lies not in bigger servers or faster queries, but in architectural foresight, and that begins with caching what matters, when it matters, in the safest and smartest way possible.
Opinions expressed by DZone contributors are their own.
Comments