Performance-Centric Platform Engineering: Shared Responsibility, Guardrails, and Tenant Isolation
Performance becomes predictable when platforms embed guardrails, autoscaling, isolation, observability, and continuous testing.
Join the DZone community and get the full member experience.
Join For FreePlatform engineering today isn't just about making deployments faster; it's also about making sure that performance is always predictable, reliable, and scalable. As companies start using internal developer platforms (IDPs) on Kubernetes, performance engineering must shift from being an application-level concern to a platform-embedded discipline.
This is where Performance by Design emerges: a model where responsibility is shared, guardrails are enforced, and tenant isolation ensures fairness and reliability across workloads.
Why Performance Must Be a Platform Concern
Traditionally, performance optimization happens late in the lifecycle — developers write applications, Ops teams tune infrastructure, and SREs react to incidents.
This reactive model leads to:
- Unpredictable scaling behavior
- Noisy neighbor problems in multi-tenant clusters
- Over-provisioning to avoid failures
- Poor feedback loops for developers
Platform engineering flips this approach by embedding performance controls into the platform itself — so every workload benefits automatically.
The Shared Responsibility Model for Performance
Performance by design starts with clearly defined ownership between platform teams and application teams.
Platform team owns:
- Resource orchestration (HPA, VPA, cluster autoscaling)
- Performance-aware deployment templates
- Baseline SLOs and scaling policies
- Guardrails for CPU, memory, and custom metrics
- Observability infrastructure
Application teams own:
- Application-level performance characteristics
- Load patterns and business SLAs
- Efficient code and resource usage
- Performance testing inputs
The outcome of this approach is that, instead of ad hoc tuning, the platform provides safe defaults and enforced standards. Developers focus on business logic within known performance boundaries. This creates predictable performance behavior across the organization.
Performance by Design Extends into Day-2 Operations
Golden paths, guardrails, and templates establish strong performance defaults at launch, but the real test begins months later. As traffic patterns evolve, teams make exceptions, and platforms are upgraded, performance behavior inevitably drifts. Resource requests stop matching reality, autoscaling becomes less efficient, and policies that once worked no longer reflect actual workload characteristics. Without active Day‑2 controls, platforms slowly revert to reactive tuning and firefighting.
Mature platforms treat performance as a continuously governed capability. Policies are versioned and evolved safely; autoscaling behavior is periodically retuned based on real traffic; and performance regressions are detected by comparing current behavior against historical baselines. Platform upgrades are handled as performance‑critical events, not routine maintenance, and exceptions are made explicit, observable, and time‑bound. In this model, Performance by Design is not a static architecture decision; it is an ongoing operational discipline that keeps multi‑tenant systems predictable, fair, and resilient as both the platform and its workloads change.
Templates With Pre-Baked Performance Patterns
Golden paths in IDPs should not just scaffold deployments; they should encode proven performance strategies. Examples of performance-aware templates:
- Microservice with:
- HPA enabled by default
- Resource requests/limits aligned with workload class
- Readiness and liveness probes tuned for latency
- AI/ML inference service with:
- Custom metrics (latency, tokens/sec, queue depth)
- Preconfigured scaling thresholds
- Circuit breakers for overload
- Batch workloads with:
- Priority classes
- Resource quotas
- Controlled concurrency
Guardrails That Enforce Predictable Scaling
Guardrails are the policies that ensure teams cannot accidentally break platform stability. Key Performance Guardrails are
- Resource boundaries
- Mandatory CPU and memory requests
- Enforced limits to prevent runaway workloads
- Scaling policies
- Standardized HPA behaviors (scale-up/down rates)
- Stabilization windows to avoid thrashing
- Approved custom metrics
- Quotas and limits
- Namespace-level resource quotas
- LimitRanges for pods
- Policy as code
- Block deployments without performance settings
- Enforce baseline autoscaling
- Validate metric configurations
Tenant Isolation: The Foundation of Fair Performance
Multi-tenancy is where performance problems multiply. Without isolation:
- One workload can starve others
- Burst traffic causes cascading failures
- Debugging becomes impossible
Isolation in Platform Engineering
- Logical isolation (Kubernetes Namespaces)
- Separate environments or teams
- Individual quotas
- Network policies
- Resource isolation
- CPU and memory guarantees
- Dedicated node pools for critical workloads
- Priority and preemption policies
- Performance isolation
- Per-tenant autoscaling policies
- Custom metrics per workload class
- Fair queuing for ingress traffic
Why Namespace Isolation Matters
Namespaces become performance domains, where:
- Each tenant has predictable capacity
- Scaling happens independently
- Failures are contained
This is crucial for IDPs serving multiple teams, products, or AI workloads. Below is a performance-focused comparison of the multi-tenancy models used in modern platforms. IDPs can follow a mix of these models.
|
Model
|
Isolation Level
|
Performance Predictability
|
Cost Efficiency
|
Operational Complexity
|
Usage
|
|---|---|---|---|---|---|
|
Shared Cluster + Shared Namespace |
Low |
Poor |
Very High |
Low |
Dev, test, prototypes |
|
Shared Cluster + Per-Tenant Namespace |
Medium |
Moderate |
High |
Medium |
Most enterprise IDPs |
|
Shared Cluster + Strong Resource Boundaries |
High |
High |
Medium |
Medium–High |
Performance-sensitive SaaS |
|
Dedicated Node Pools per Tenant |
Very High |
Very High |
Lower |
High |
AI/critical workloads |
|
Dedicated Cluster per Tenant |
Maximum |
Maximum |
Lowest |
Very High |
Regulated/high isolation |
The following is a performance comparison of multi-tenancy models in platform engineering:
|
Model
|
Latency Stability
|
Scaling Accuracy
|
Noisy Neighbor Risk
|
Resource Utilization Efficiency
|
Fault Isolation
|
|---|---|---|---|---|---|
|
Shared Cluster + Shared Namespace |
Highly unstable due to direct contention and uncontrolled bursts |
Poor: HPA signals affected by unrelated workloads |
Extremely high: any tenant can starve others |
High but unsafe, frequent overcommit |
None |
|
Shared Cluster + Per-Tenant Namespace |
More stable but affected by node-level pressure |
Moderate: per-tenant scaling with some interference |
Medium: contained logically but not physically |
High with basic quotas |
Partial |
|
Shared Cluster + Strong Resource Boundaries |
Predictable with guaranteed resources |
High tenant-specific metrics drive scaling |
Low: guardrails prevent resource abuse |
Moderate due to reservations |
Strong |
|
Shared Cluster + Dedicated Node Pools |
Near-constant and low latency |
Very high: scaling isolated to pool |
None: physical separation |
Lower due to idle pool capacity |
Very strong |
|
Dedicated Cluster per Tenant |
Fully deterministic |
Perfect: fully independent scaling |
None |
Lowest: duplicate infrastructure |
Complete |
Performance Observability Built into the Platform
You cannot design for performance without visibility. Platform-level observability should provide the following metrics:
- Core metrics
- Request latency (p50, p95, p99)
- Throughput (RPS, tokens/sec, jobs/sec)
- Resource utilization
- Autoscaling behavior
- Platform insights
- Scaling efficiency (replicas vs load)
- Over/under-provisioning trends
- Noisy neighbor detection
- Guardrail violations
- Feedback to developers
- Performance dashboards per service
- Alerts tied to SLOs
- Cost vs performance views
Kubernetes Performance-by-Design Architecture
The following architecture illustrates how performance-by-design principles are operationalized within a Kubernetes-based Internal Developer Platform. It highlights the interaction between governance guardrails, autoscaling control planes, tenant isolation mechanisms, and observability systems that collectively deliver predictable and resilient performance in shared clusters.
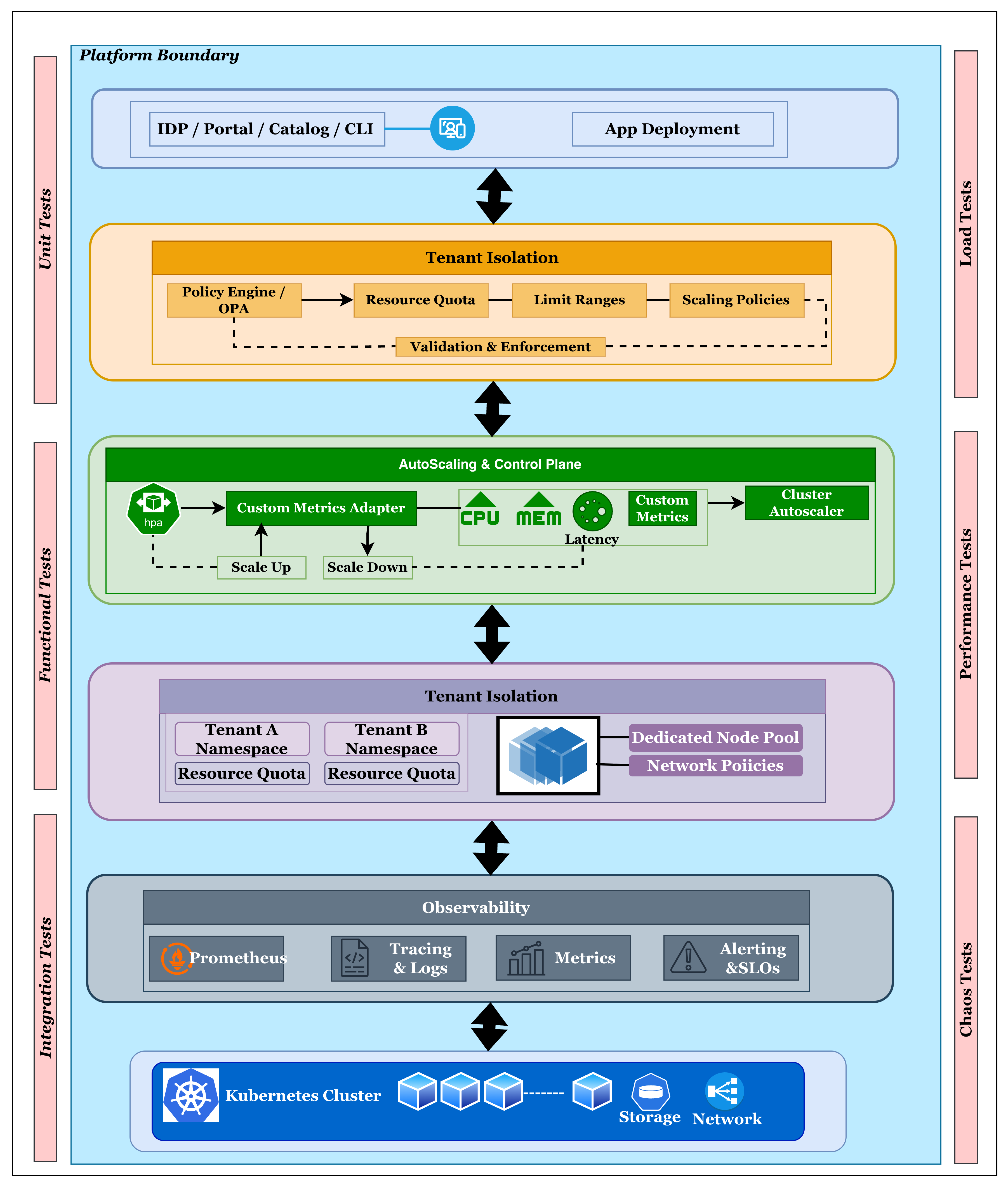
Embedding Performance and Chaos Testing into the Platform Lifecycle
Modern platforms see performance and resilience testing as built-in features instead of separate steps for validation. Load testing is built into IDP templates and workflows so that autoscaling behavior, resource guardrails, and capacity assumptions can be checked all the time under real traffic conditions. In parallel, chaos engineering injects controlled failures, such as pod crashes, node outages, and metric disruptions, to validate isolation boundaries and recovery mechanisms in shared clusters. The insights gained from these experiments about how well the platform works go back into the platform's policies and templates, making a closed-loop system of constant improvement. Performance testing and chaos testing work together to make sure that the platform guarantees stay reliable, predictable, and useful at scale.
Performance by Design in Action
A typical platform flow looks like this:
- Developer deploys using IDP template
- Performance defaults applied automatically
- Guardrails validate configurations
- Autoscaling runs with standardized policies
- Tenant isolation ensures fairness
- Observability feeds continuous improvement
The platform guarantees:
- Predictable scaling
- Safe multi-tenancy
- Performance resilience
The developer experiences:
- Zero performance configuration guesswork
- Faster time to production
- Fewer incidents
Conclusion
Platform engineering represents a fundamental shift: from “optimize when things break” to “design so things scale correctly by default.”
Performance must be engineered into the platform itself — not optimized after failures occur. By combining shared responsibility, performance-aware templates, enforceable guardrails, strong tenant isolation, and built-in observability, Kubernetes-based platforms can deliver predictable scaling and fair resource usage by design. This approach shifts performance from reactive tuning to a continuously governed platform capability, enabling resilient multi-tenant systems that scale reliably under real-world demand.
Opinions expressed by DZone contributors are their own.
Comments