Scaling PostgreSQL Reads: Implementing Read-Your-Write Consistency Using WAL-Based Replica Routing
Read-your-write consistency via WAL LSN tracking. Route reads to replicas only when they've caught up to the user's last write. 62% less CPU, 50% cheaper.
Join the DZone community and get the full member experience.
Join For FreeAt a previous company, we hit a point where our PostgreSQL database was clearly becoming a bottleneck. The primary instance was responsible for every user-facing search request, including some heavy queries from long-time users with years of historical data. CPU usage kept climbing, and before long, we were already running on the largest instance size available. Vertical scaling had officially hit its limit.
Naturally, the next step was to introduce read replicas. On paper, it sounded straightforward. In reality, it wasn’t.
Our application had a strict requirement: read-your-write consistency. If a user created or updated data and immediately searched for it, they expected to see it — no delays, no inconsistencies. Even a few seconds of replication lag led to confusion, support tickets, and a noticeable drop in trust.
That constraint ruled out naive load balancing across replicas.
In this article, I’ll walk through how we solved this by leveraging PostgreSQL’s write-ahead log (WAL) to make smarter routing decisions between the primary and replicas. The result? We reduced CPU load on the primary by 62%, kept latency predictable, and — most importantly — preserved the consistency guarantees our users relied on.
The Problem: When Read Replicas Aren't Enough
Our Initial State
Our architecture was straightforward: a single PostgreSQL 14 primary database handling all reads and writes for a user-facing application.
The numbers told a concerning story:
| Metric | Value |
|---|---|
| Peak QPS (Queries Per Second) | ~15,000 |
| Average Query Latency (p50) | 45ms |
| 99th Percentile Latency | 890ms |
| CPU Utilization (Peak) | 94% |
| Read/Write Ratio | 85:15 |
With 85% of traffic being reads, replicas seemed like the obvious answer. But our domain had a critical constraint.
The Consistency Problem
Consider this user flow:
- User creates a new order at
T=0 - User immediately navigates to "My Orders" page at
T=2s - Application queries for user's orders
- User expects to see their new order
With asynchronous replication, the replica might be 50–500ms behind the primary in the worst case; it could even be in seconds, which might lead to bad CX. If we routed the read to a lagging replica, the user wouldn't see their just-created order. In e-commerce, this creates panic: "Did my order go through? Should I order again?"
We needed a solution that would route reads to replicas only when those replicas had caught up to the user's most recent write.
Understanding PostgreSQL WAL and LSN
Before diving into the implementation, let's understand the PostgreSQL internals that make this possible.
Write-Ahead Logging (WAL)
PostgreSQL uses write-ahead logging to ensure durability. Every change to the database is first written to the WAL before being applied to the actual data files. This WAL is then streamed to replicas for replication.
Log Sequence Number (LSN)
The LSN is a pointer to a position in the WAL. It's a 64-bit integer representing the byte offset in the WAL stream. Every transaction that modifies data generates a new LSN.
-- Get the current WAL position on primary
SELECT pg_current_wal_lsn();
-- Result: 16/3D42A8B0
-- Get the last replayed position on a replica
SELECT pg_last_wal_replay_lsn();
-- Result: 16/3D42A7F0The key insight: if a replica's replay LSN is greater than or equal to the LSN of a user's last write, that replica has all the user's data.
The Solution: LSN-Based Replica Routing
High-Level Architecture
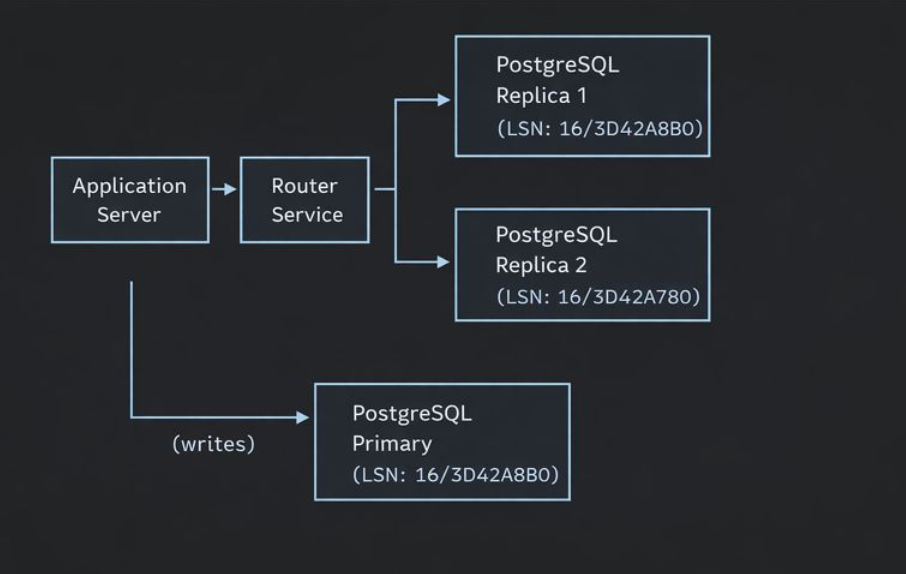
The Algorithm
- On write: Capture the LSN after committing a user's transaction
- Store LSN: Associate the LSN with the user (in Redis with TTL)
- On read: Retrieve the user's last-write LSN
- Route: Query replica LSNs and route to one that has caught up
- Fallback: If no replica has caught up, route to primary
Implementation Details
Step 1: Capturing Write LSN
After any write operation, we capture the current WAL LSN:
@Service
public class WriteTrackingService {
private final JdbcTemplate jdbcTemplate;
private final RedisTemplate<String, String> redisTemplate;
private static final String LSN_KEY_PREFIX = "user:lsn:";
private static final Duration LSN_TTL = Duration.ofMinutes(5);
@Transactional
public void executeWriteAndTrackLsn(String userId, Runnable writeOperation) {
// Execute the actual write
writeOperation.run();
// Capture the LSN after commit
String currentLsn = jdbcTemplate.queryForObject(
"SELECT pg_current_wal_lsn()::text",
String.class
);
// Store in Redis with TTL
String key = LSN_KEY_PREFIX + userId;
redisTemplate.opsForValue().set(key, currentLsn, LSN_TTL);
log.debug("Tracked write LSN {} for user {}", currentLsn, userId);
}
}Step 2: The Replica Health Monitor
We continuously monitor replica LSN positions:
@Component
public class ReplicaLsnMonitor {
private final Map<String, DataSource> replicaDataSources;
private final ConcurrentHashMap<String, LsnPosition> replicaPositions =
new ConcurrentHashMap<>();
@Scheduled(fixedRate = 100) // Poll every 100ms
public void updateReplicaPositions() {
replicaDataSources.forEach((replicaId, dataSource) -> {
try (Connection conn = dataSource.getConnection();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(
"SELECT pg_last_wal_replay_lsn()::text, " +
"EXTRACT(EPOCH FROM (now() - pg_last_xact_replay_timestamp()))::int " +
"AS lag_seconds")) {
if (rs.next()) {
String lsn = rs.getString(1);
int lagSeconds = rs.getInt(2);
replicaPositions.put(replicaId, new LsnPosition(
lsn,
lagSeconds,
Instant.now()
));
}
} catch (SQLException e) {
log.warn("Failed to get LSN for replica {}: {}", replicaId, e.getMessage());
replicaPositions.remove(replicaId);
}
});
}
public Map<String, LsnPosition> getCurrentPositions() {
return new HashMap<>(replicaPositions);
}
}
@Value
class LsnPosition {
String lsn;
int lagSeconds;
Instant capturedAt;
}Step 3: LSN Comparison Utility
PostgreSQL LSNs are in the format X/YYYYYYYY where X is the timeline and Y is the offset. We need to compare them properly:
public class LsnComparator {
/**
* Compares two PostgreSQL LSN values.
* Returns: negative if lsn1 < lsn2, zero if equal, positive if lsn1 > lsn2
*/
public static int compare(String lsn1, String lsn2) {
if (lsn1 == null || lsn2 == null) {
throw new IllegalArgumentException("LSN cannot be null");
}
long[] parsed1 = parseLsn(lsn1);
long[] parsed2 = parseLsn(lsn2);
// Compare timeline first
int timelineCompare = Long.compare(parsed1[0], parsed2[0]);
if (timelineCompare != 0) {
return timelineCompare;
}
// Then compare offset
return Long.compare(parsed1[1], parsed2[1]);
}
/**
* Returns true if replicaLsn >= requiredLsn
*/
public static boolean hasCaughtUp(String replicaLsn, String requiredLsn) {
return compare(replicaLsn, requiredLsn) >= 0;
}
private static long[] parseLsn(String lsn) {
String[] parts = lsn.split("/");
if (parts.length != 2) {
throw new IllegalArgumentException("Invalid LSN format: " + lsn);
}
return new long[] {
Long.parseLong(parts[0], 16),
Long.parseLong(parts[1], 16)
};
}
}Step 4: The Query Router
The core routing logic that brings everything together:
@Service
public class ConsistentReadRouter {
private final RedisTemplate<String, String> redisTemplate;
private final ReplicaLsnMonitor replicaMonitor;
private final DataSource primaryDataSource;
private final Map<String, DataSource> replicaDataSources;
private final MeterRegistry meterRegistry;
private static final String LSN_KEY_PREFIX = "user:lsn:";
// Metrics
private final Counter routedToPrimary;
private final Counter routedToReplica;
private final Counter noLsnFound;
public ConsistentReadRouter(/* dependencies */) {
// Initialize dependencies...
this.routedToPrimary = meterRegistry.counter("db.routing.primary");
this.routedToReplica = meterRegistry.counter("db.routing.replica");
this.noLsnFound = meterRegistry.counter("db.routing.no_lsn");
}
public DataSource getDataSourceForRead(String userId) {
// Step 1: Get user's last write LSN
String userLsn = redisTemplate.opsForValue()
.get(LSN_KEY_PREFIX + userId);
if (userLsn == null) {
// No recent writes - any replica is fine
noLsnFound.increment();
return selectHealthiestReplica();
}
// Step 2: Find a replica that has caught up
Map<String, LsnPosition> positions = replicaMonitor.getCurrentPositions();
List<String> eligibleReplicas = positions.entrySet().stream()
.filter(e -> LsnComparator.hasCaughtUp(e.getValue().getLsn(), userLsn))
.filter(e -> e.getValue().getLagSeconds() < 30) // Healthy threshold
.map(Map.Entry::getKey)
.collect(Collectors.toList());
if (eligibleReplicas.isEmpty()) {
// No replica has caught up - use primary
routedToPrimary.increment();
log.debug("No replica caught up for user {} (LSN: {}), routing to primary",
userId, userLsn);
return primaryDataSource;
}
// Step 3: Select replica with lowest lag
String selectedReplica = eligibleReplicas.stream()
.min(Comparator.comparing(id -> positions.get(id).getLagSeconds()))
.orElseThrow();
routedToReplica.increment();
log.debug("Routing user {} to replica {} (user LSN: {}, replica LSN: {})",
userId, selectedReplica, userLsn, positions.get(selectedReplica).getLsn());
return replicaDataSources.get(selectedReplica);
}
private DataSource selectHealthiestReplica() {
Map<String, LsnPosition> positions = replicaMonitor.getCurrentPositions();
return positions.entrySet().stream()
.filter(e -> e.getValue().getLagSeconds() < 30)
.min(Comparator.comparing(e -> e.getValue().getLagSeconds()))
.map(e -> replicaDataSources.get(e.getKey()))
.orElse(primaryDataSource);
}
}
Step 5: Integration with Repository Layer
We created a custom annotation and aspect to make this transparent to developers:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface ConsistentRead {
String userIdParam() default "userId";
}
@Aspect
@Component
public class ConsistentReadAspect {
private final ConsistentReadRouter router;
@Around("@annotation(consistentRead)")
public Object routeToAppropriateDataSource(
ProceedingJoinPoint joinPoint,
ConsistentRead consistentRead) throws Throwable {
String userId = extractUserId(joinPoint, consistentRead.userIdParam());
DataSource dataSource = router.getDataSourceForRead(userId);
// Set the DataSource in thread-local context
DataSourceContextHolder.setDataSource(dataSource);
try {
return joinPoint.proceed();
} finally {
DataSourceContextHolder.clear();
}
}
private String extractUserId(ProceedingJoinPoint joinPoint, String paramName) {
// Extract userId from method parameters
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
String[] paramNames = signature.getParameterNames();
Object[] args = joinPoint.getArgs();
for (int i = 0; i < paramNames.length; i++) {
if (paramNames[i].equals(paramName)) {
return args[i].toString();
}
}
throw new IllegalStateException("Could not find userId parameter: " + paramName);
}
}
// Usage in repository
@Repository
public class OrderRepository {
@ConsistentRead(userIdParam = "userId")
public List<Order> findOrdersByUserId(String userId) {
// This query will be routed to an appropriate replica
return jdbcTemplate.query(
"SELECT * FROM orders WHERE user_id = ? ORDER BY created_at DESC",
orderRowMapper,
userId
);
}
}The Dynamic DataSource Routing
To make the routing work with Spring's transaction management:
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.getCurrentDataSource();
}
}
public class DataSourceContextHolder {
private static final ThreadLocal<DataSource> contextHolder = new ThreadLocal<>();
public static void setDataSource(DataSource dataSource) {
contextHolder.set(dataSource);
}
public static DataSource getCurrentDataSource() {
return contextHolder.get();
}
public static void clear() {
contextHolder.remove();
}
}
@Configuration
public class DataSourceConfig {
@Bean
public DataSource routingDataSource(
DataSource primaryDataSource,
Map<String, DataSource> replicaDataSources) {
RoutingDataSource routingDataSource = new RoutingDataSource();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put("primary", primaryDataSource);
replicaDataSources.forEach(targetDataSources::put);
routingDataSource.setTargetDataSources(targetDataSources);
routingDataSource.setDefaultTargetDataSource(primaryDataSource);
return routingDataSource;
}
}Handling Edge Cases
Edge Case 1: Replica Lag Spikes
During deployments or heavy write loads, replicas can fall behind significantly. We handle this with a lag threshold:
private static final int MAX_ACCEPTABLE_LAG_SECONDS = 30;
public boolean isReplicaHealthy(LsnPosition position) {
// Check if position data is fresh
if (position.getCapturedAt().isBefore(Instant.now().minusSeconds(5))) {
return false; // Stale monitoring data
}
return position.getLagSeconds() < MAX_ACCEPTABLE_LAG_SECONDS;
}Edge Case 2: Redis Failures
If Redis is unavailable, we fail over to the primary:
public DataSource getDataSourceForRead(String userId) {
String userLsn;
try {
userLsn = redisTemplate.opsForValue().get(LSN_KEY_PREFIX + userId);
} catch (RedisConnectionException e) {
log.warn("Redis unavailable, failing safe to primary");
return primaryDataSource;
}
// ... rest of routing logic
}
Edge Case 3: User's First Read (No Prior Writes)
For users without recent writes, we don't have an LSN requirement and can use any healthy replica:
if (userLsn == null) {
noLsnFound.increment();
return selectHealthiestReplica();
}
Edge Case 4: Cross-Session Consistency
The TTL on Redis keys (5 minutes) handles the case where users return after a period of inactivity. After 5 minutes, we assume any replica has caught up.
Monitoring and Observability
Comprehensive monitoring was crucial for understanding system behavior.
Key Metrics
@Component
public class RoutingMetrics {
private final MeterRegistry registry;
// Routing decisions
private final Counter routedToPrimary;
private final Counter routedToReplica;
private final Counter routedNoLsn;
// Latency
private final Timer routingDecisionTime;
// Replica health
private final Gauge replicaLagGauge;
public RoutingMetrics(MeterRegistry registry, ReplicaLsnMonitor monitor) {
this.registry = registry;
this.routedToPrimary = registry.counter("db.routing.destination", "target", "primary");
this.routedToReplica = registry.counter("db.routing.destination", "target", "replica");
this.routedNoLsn = registry.counter("db.routing.no_user_lsn");
this.routingDecisionTime = registry.timer("db.routing.decision.time");
// Per-replica lag gauges
monitor.getCurrentPositions().keySet().forEach(replicaId -> {
registry.gauge("db.replica.lag.seconds",
Tags.of("replica", replicaId),
monitor,
m -> m.getCurrentPositions()
.getOrDefault(replicaId, new LsnPosition("0/0", 999, Instant.now()))
.getLagSeconds()
);
});
}
}Grafana Dashboard Queries
-- Routing distribution over time
SELECT
time_bucket('1 minute', time) AS bucket,
sum(case when target = 'primary' then 1 else 0 end) as primary_routes,
sum(case when target = 'replica' then 1 else 0 end) as replica_routes
FROM db_routing_destination
GROUP BY bucket
ORDER BY bucket;
-- Replica lag over time
SELECT
time_bucket('1 minute', time) AS bucket,
replica,
avg(lag_seconds) as avg_lag
FROM db_replica_lag_seconds
GROUP BY bucket, replica
ORDER BY bucket;Alerting Rules
groups:
- name: read-replica-routing
rules:
- alert: HighPrimaryRoutingRate
expr: |
sum(rate(db_routing_destination{target="primary"}[5m])) /
sum(rate(db_routing_destination[5m])) > 0.3
for: 10m
labels:
severity: warning
annotations:
summary: "High primary routing rate ({{ $value | humanizePercentage }})"
- alert: ReplicaLagHigh
expr: db_replica_lag_seconds > 30
for: 5m
labels:
severity: warning
annotations:
summary: "Replica {{ $labels.replica }} lag is {{ $value }}s"Results and Improvements
After implementing this solution and rolling it out gradually over two weeks, we observed significant improvements.
Performance Metrics
| Metric | Before | After | Improvement |
|---|---|---|---|
| Primary CPU (Peak) | 94% | 36% | 62% reduction |
| Primary CPU (Average) | 71% | 28% | 61% reduction |
| Query Latency (p50) | 45ms | 32ms | 29% faster |
| Query Latency (p99) | 890ms | 245ms | 72% faster |
| Read QPS on Primary | ~12,750 | ~1,900 | 85% offloaded |
Routing Distribution
After stabilization, our routing distribution looked like:
- Routed to Replica: 82%
- Routed to Primary (caught-up check failed): 11%
- Routed to Primary (no LSN in Redis): 7%
The 11% that went to primary due to consistency requirements represented users actively creating/modifying data — exactly the cases where we needed strong consistency.
Cost Savings
With reduced primary load, we were able to downsize our primary instance:
- Before: db.r6g.16xlarge ($6.912/hour)
- After: db.r6g.4xlarge ($1.728/hour) + 2x db.r6g.2xlarge replicas ($0.864/hour each)
- Net savings: ~$3,456/hour → ~50% cost reduction
Lessons Learned
1. LSN Polling Frequency Matters
Initially, we polled replica LSNs every second, which was too slow. Users making quick successive writes would get routed to the primary unnecessarily. Reducing to 100ms polling solved this while adding minimal overhead.
2. Redis TTL Tuning
Our initial 30-second TTL was too aggressive. Users navigating slowly through forms would lose their LSN tracking mid-flow. We increased to 5 minutes, which covered 99% of user sessions while still allowing eventual full replica usage.
3. Graceful Degradation is Essential
When we had a Redis cluster maintenance window, our initial implementation caused errors. Adding fallback-to-primary logic ensured zero user impact during infrastructure issues.
4. Monitor Routing Decisions, Not Just Performance
Understanding why queries went to primary vs. replica was crucial for optimization. The "no LSN found" metric helped us identify user flows where we weren't tracking writes properly.
Conclusion
In the end, this approach gave us the best of both worlds: strong consistency where it mattered and real cost savings where it didn’t.
It’s not the simplest solution, and it’s definitely not something I’d recommend unless you’re already pushing PostgreSQL hard — but if you are, WAL-based routing is surprisingly effective.
References
Opinions expressed by DZone contributors are their own.
Comments