Processing Large Files With Repeating Elements and Header/Trailer Fields
How to use IBM App Connect Enterprise File Nodes and DFDL Parser to process very large files with repeating elements and header/trailer fields.
Join the DZone community and get the full member experience.
Join For FreeWhen processing extremely large messages, there are a number of factors that need to be considered when designing a flow. There are a variety of in-built limits that need to be tuned or configured in order to successfully process files of this type and there are a number of actions that should be considered when designing a message flow in order to ensure that processing is efficient. This article will explain the main challenges that need to be overcome and then present a pattern for enabling very large processing that can be adapted to fit with other business requirements.
The Project Interchange files which accompany this article are available here.
Note that all performance measurements quoted in this article were taken using IBM App Connect Enterprise v12.0.8.0 running on a developer workstation on the Linux x64 platform.
The Challenges
The File Record Size Limit
The FileInput Node can be configured to either treat the entire file as a single message or to read individual records from the file. By default, the maximum size of record that can be read is100Mb so this means that in Whole File processing mode only a 100Mb file can be read before the message flow throws an exception. Using individual records an arbitrary size file may be processed but each individual record must be less than 100Mb. The file record size limit can be increased using the environment variable MQSI_FILENODES_MAXIMUM_RECORD_LENGTH which can be set to the required maximum limit in bytes.
For the majority of use cases where a file is made up of repeating records of the same type all that is necessary to process an arbitrary sized file is to use the Records and Elements panel of the File Input node set to either "Fixed Length", "Delimited", or "Parsed Record Sequence"; however, this is not sufficient for use cases such as the one we discuss below where we need some way to skip past the start of the file before reaching the section containing repeating elements.
The 2Gb Limit
The internal parser interface uses a C signed int data type to represent the position within a bitstream. This type has a maximum value, on most platforms, of 2Gb and by extension the parser interface is unable to access any position in a bitstream beyond the 2Gb mark. Attempts to access the bitstream beyond this point may result in undefined behavior and in some versions of App Connect an explicit exception will be thrown to prevent undefined behavior such as a crash.
The 4Gb Limit
The second limit imposed by the internal data structures used in App Connect Enterprise is the 4Gb limit. A C unsigned int type is used to specify the size of the buffer used to hold data in the logical tree, this data type on most platforms has a maximum size of 4Gb. At first it would seem that it is impossible to access the additional 2Gb due to the first restriction imposed by the 2Gb limit on the position used by the parser when examining the input bitstream, however it should be noted that data is stored in the logical tree in UCS-2 format which uses 2 bytes per character. Therefore, a raw bitstream that is parsed as a character data type would result in a data buffer that is double the size of the data in the raw input buffers.
It is also possible to manually create elements with large buffers in the logical tree without referring to an input bitstream, thereby bypassing the 2Gb position limit, although it should be noted that it is extremely difficult to do so without exhausting memory.
Memory Usage
Perhaps the most compelling challenge when dealing with a large amount of data is doing it in a way which is memory efficient. When working with message data that is large enough to be approaching the limits described above, the total memory footprint of the message flow can become very large. Even on a large system with plenty of memory, the overhead of allocating huge amounts of memory can slow down processing and also limits the other workloads which could be run on the same hardware simultaneously.
Observing These Challenges in Practice
To demonstrate, let us consider the following use case and compare the footprint of a naive implementation versus a memory efficient one.
Our example use case is a batch reconciliation process which operates on XML data with the following structure:
<?xml version="1.0" encoding="UTF-8"?>
<RECONCILIATIONFILE>
<HEADER>
<FILEID>AB000001</FILEID>
<TYPE>FULL</TYPE>
<RUNNO>1</RUNNO>
<BEGINDATE>2010-12-31T14:30:59</BEGINDATE>
<ENDDATE>2010-12-31T14:30:59</ENDDATE>
</HEADER>
<DEBIT>
<ACCOUNT>5250515051505552</ACCOUNT>
<CURRENCY>USD</CURRENCY>
<AMOUNT>73683.84</AMOUNT>
<TID>3d816ff2-9425-4404-8409-d104ff69190d</TID>
</DEBIT>
<CREDIT>
<ACCOUNT>4849565353495548</ACCOUNT>
<CURRENCY>USD</CURRENCY>
<AMOUNT>37669.29</AMOUNT>
<TID>bbbe473a-238a-40a9-9ffa-10915261d231</TID>
</CREDIT>
<TRAILER>
<RECORDCOUNT>2</RECORDCOUNT>
</TRAILER>
</RECONCILIATIONFILE>Here we have a document that has a header section which contains some meta data about the batch such as the file ID and the begin and end date. After this header is an arbitrary number of repeating elements which can either be a debit of the form:
<DEBIT>
<ACCOUNT>5250515051505552</ACCOUNT>
<CURRENCY>USD</CURRENCY>
<AMOUNT>73683.84</AMOUNT>
<TID>3d816ff2-9425-4404-8409-d104ff69190d</TID>
</DEBIT>or a credit of the form:
<CREDIT>
<ACCOUNT>4849565353495548</ACCOUNT>
<CURRENCY>USD</CURRENCY>
<AMOUNT>37669.29</AMOUNT>
<TID>bbbe473a-238a-40a9-9ffa-10915261d231</TID>
</CREDIT>Finally, there is a trailer which contains the number of total records expected in the file. In our example the task is to process this entire file and output either SUCCESS if the total number of records matches the value in the trailer section or FAILED if the count does not match. The flow should also output the total value of credits and debits and the balance (credits - debits) along with the number of records processed and the expected number of records.
First of all, let us consider a naive implementation. We could consider reading the entire flow in a single message and then simply iterating through the repeated sections in memory. In this scenario, the flow topology itself would be very simple:

This flow contains a File Input Node to pick up the file and propagate the whole thing to Compute Node which does the bulk of the work. Finally, the results are output to the file system by a File Output Node. The ESQL Node contains the following code:
CREATE COMPUTE MODULE Reconcile_Large_Message_Naive_Compute
CREATE FUNCTION Main() RETURNS BOOLEAN
BEGIN
-- Skip over the header information
DECLARE cursor REFERENCE TO InputRoot.XMLNSC.RECONCILIATIONFILE.HEADER;
DECLARE totalCredits, totalDebits, balance, recordCount, expectedRecords INTEGER 0;
MOVE cursor NEXTSIBLING;
X: WHILE LASTMOVE(cursor) DO
--Determine if this is a credit or a debit
IF FIELDNAME(cursor) = 'CREDIT' THEN
SET totalCredits = totalCredits + CAST(cursor.AMOUNT AS DECIMAL);
SET balance = balance + CAST(cursor.AMOUNT AS DECIMAL);
SET recordCount = recordCount +1 ;
ELSEIF FIELDNAME(cursor) = 'DEBIT' THEN
SET totalDebits = totalDebits + CAST(cursor.AMOUNT AS DECIMAL);
SET balance = balance - CAST(cursor.AMOUNT AS DECIMAL);
SET recordCount = recordCount +1 ;
ELSE
-- this shouldnow be the trailer record
LEAVE X;
END IF;
MOVE cursor NEXTSIBLING;
END WHILE;
SET expectedRecords = CAST(InputRoot.XMLNSC.RECONCILIATIONFILE.TRAILER.RECORDCOUNT
AS INTEGER);
CREATE LASTCHILD OF OutputRoot DOMAIN('XMLNSC');
IF expectedRecords <> recordCount THEN
SET OutputRoot.XMLNSC.ReconciliationResult.Result = 'FAILED';
SET OutputRoot.XMLNSC.ReconciliationResult.Reason = 'The number of records
processed did not match the count provided in the RECORD COUNT element of this
message';
ELSE
SET OutputRoot.XMLNSC.ReconciliationResult.Result = 'SUCCESS';
END IF;
SET OutputRoot.XMLNSC.ReconciliationResult.TotalCredits = totalCredits;
SET OutputRoot.XMLNSC.ReconciliationResult.TotalDebits = totalDebits;
SET OutputRoot.XMLNSC.ReconciliationResult.Balance = balance;
SET OutputRoot.XMLNSC.ReconciliationResult.TotalRecordsProcessed = recordCount;
SET OutputRoot.XMLNSC.ReconciliationResult.ExpectedRecordCount = expectedRecords;
SET OutputLocalEnvironment.Destination.File= 'Result.txt';
RETURN TRUE;
END;Since the entire tree is stored in memory in the naive example all we need to do is iterate through the siblings of the <HEADER> element updating our state variables as we go. Note that once we reach a sibling which is not either a CREDIT or DEBIT, we use the LEAVE statement to break out of the loop and then build the output message.
Executing this flow against a small input message produces results like the following:
<ReconciliationResult><Result>SUCCESS</Result><TotalCredits>389889</TotalCredits>
<TotalDebits>0</TotalDebits><Balance>389889</Balance><TotalRecordsProcessed>5</TotalRecordsProcessed>
<ExpectedRecordCount>5</ExpectedRecordCount></ReconciliationResult>However, if we use a 100Mb sample message we run into the first of the challenges mentioned above. With a 100Mb file, instead of an output message being created, instead the flow throws the following exception:
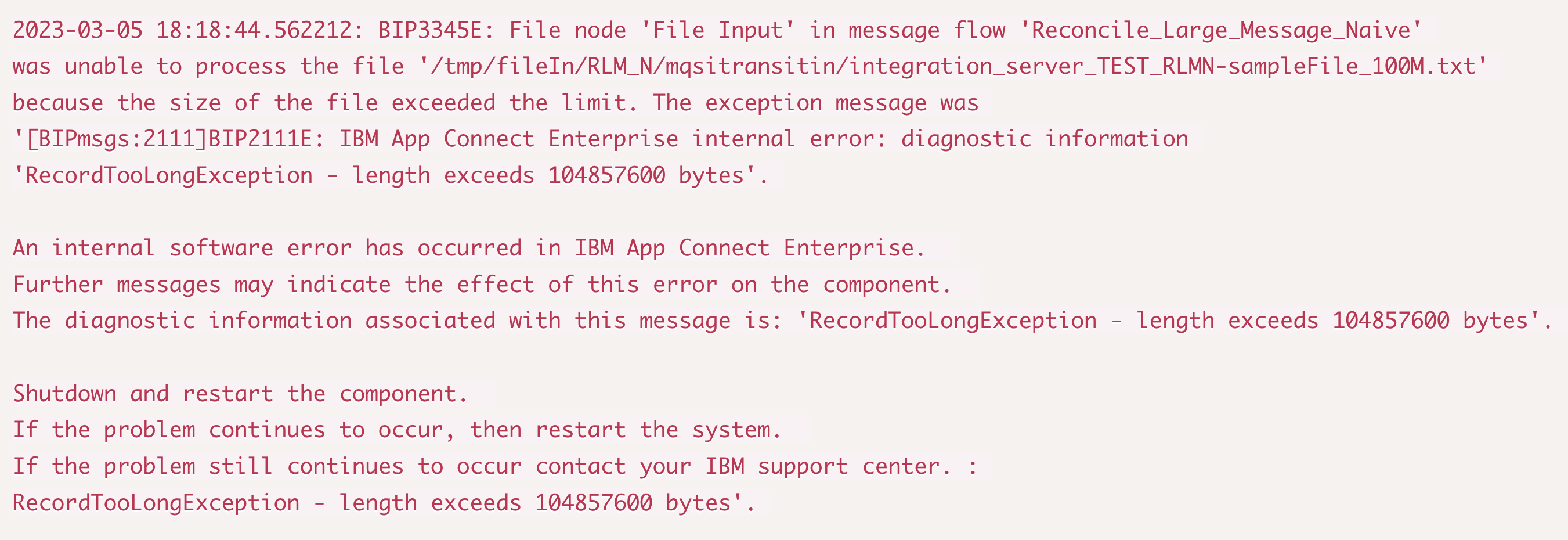
This error can be worked around by using the environment variable MQSI_FILENODES_MAXIMUM_RECORD_LENGTH to allow the File Node to read larger records. For example the following entry in the profile environment would set the maximum record size to 500Mb:

Re-running with this setting the flow does indeed process the 100Mb file successfully:
<ReconciliationResult><Result>SUCCESS</Result><TotalCredits>22779295379</TotalCredits>
<TotalDebits>10179530288</TotalDebits><Balance>12599765091</Balance>
<TotalRecordsProcessed>658774</TotalRecordsProcessed><ExpectedRecordCount>658774</ExpectedRecordCount></ReconciliationResult>However, if we try to use an even bigger file we can soon hit the limits of this flow design. Even with MQSI_FILENODES_MAXIMUM_RECORD_LENGTH set to 2,147,483,647, if we try to process a file larger than 2Gb then following failure occurs:

On earlier fixpacks, this would even cause a crash or a hang. This is because we have hit the second challenge, the 2Gb limit on the input bitstream length.
In fact, if we process a file just under the 2Gb threshold and then examine the process size of the Integration Server we can see that we have also hit the 4th challenge as well, which is very inefficient use of memory:

The ps command measures memory in Kb on Linux, so this shows that the Integration Server used a whopping 14Gb of resident memory and 21Gb of Virtual Memory to complete our relatively simple processing of the file. It is easy to see how this approach could become untenable in a real flow, where portions of the tree might need to be propagated out of the compute node, or where flow processing travels through more nodes, perhaps making tree copies along the way.
It is clear that this workload would also be hugely disruptive to other flows running on the same system potentially causing other flows to fail due to memory contention.
Redesigning the Flow With Memory Efficiency in Mind
The problems that we encountered with the first version of the flow were all related to the same underlying design flaw. The flow was designed to load the entire message into memory at once and then operate on the flow in memory. This approach is outlined in the diagram below:
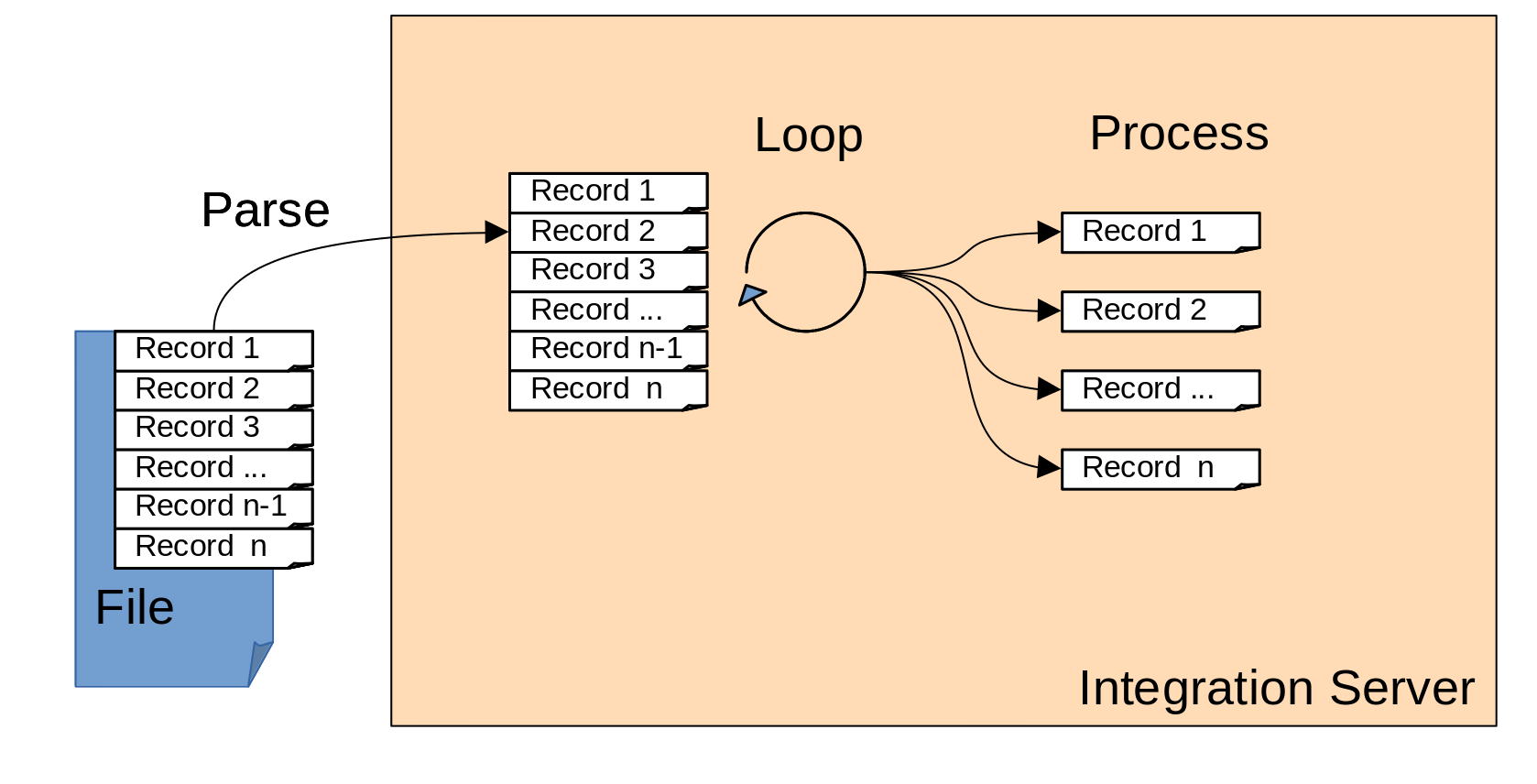
As illustrated in the diagram, the entire content of the file needs to be held in memory at once to iterate over the records. This leads to an unnecessary demand on system resources as the message size increases. Instead the flow should be designed only to operate on sections of the message at a time.
Instead, it would be more efficient to read a single record into memory at a time and process them individually as illustrated below:
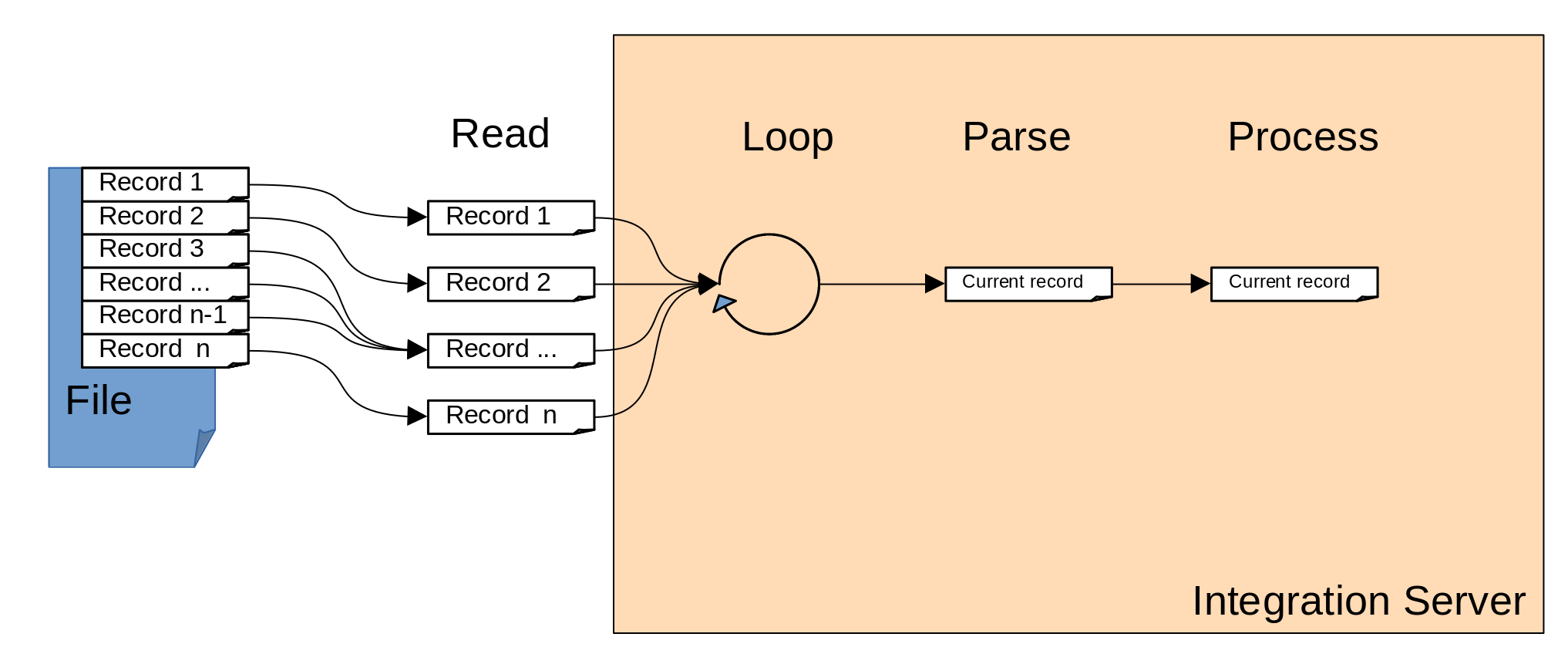
In this example, only a single record is read at a time from the file, meaning that the entire contents of the file never need to be held in memory, significantly reducing the memory requirements for running the flow. Further, the memory usage of this second design does not increase with the size of the input file and because there is never a bitstream larger than the 2Gb or 4Gb limit held in memory, this pattern is able to process files with an essentially arbitrary maximum size. (The size here is constrained by the max value of the java long datatype, which is approximately 263-1 or 1024 petabytes).
If the input file was simply a flat series of records, then this would be a trivial design change to the flow. The FileInput Node could be changed to use a delimited or parsed record sequence for its "Record detection" property and this would cause the FileInput node itself to take care of the iteration through the file, propagating a single record at a time. It is common to handle csv data in this way for example.
However, for the scenario we are looking at, the sequence of repeating elements is enclosed within a header and trailer section that has a different format to the repeating records. Additionally, the use case we are presented with requires reconciliation once all records are processed. Since the File Input Node propagates each record as a totally independent message flow invocation, we would need to store state information externally to the flow as we processed each file and then run the reconciliation itself from this externally cached data.
Instead, we will demonstrate how to use a message flow design which processes all records in a single message flow transaction to ensure atomicity of operations by using the approach set out in the diagram below:
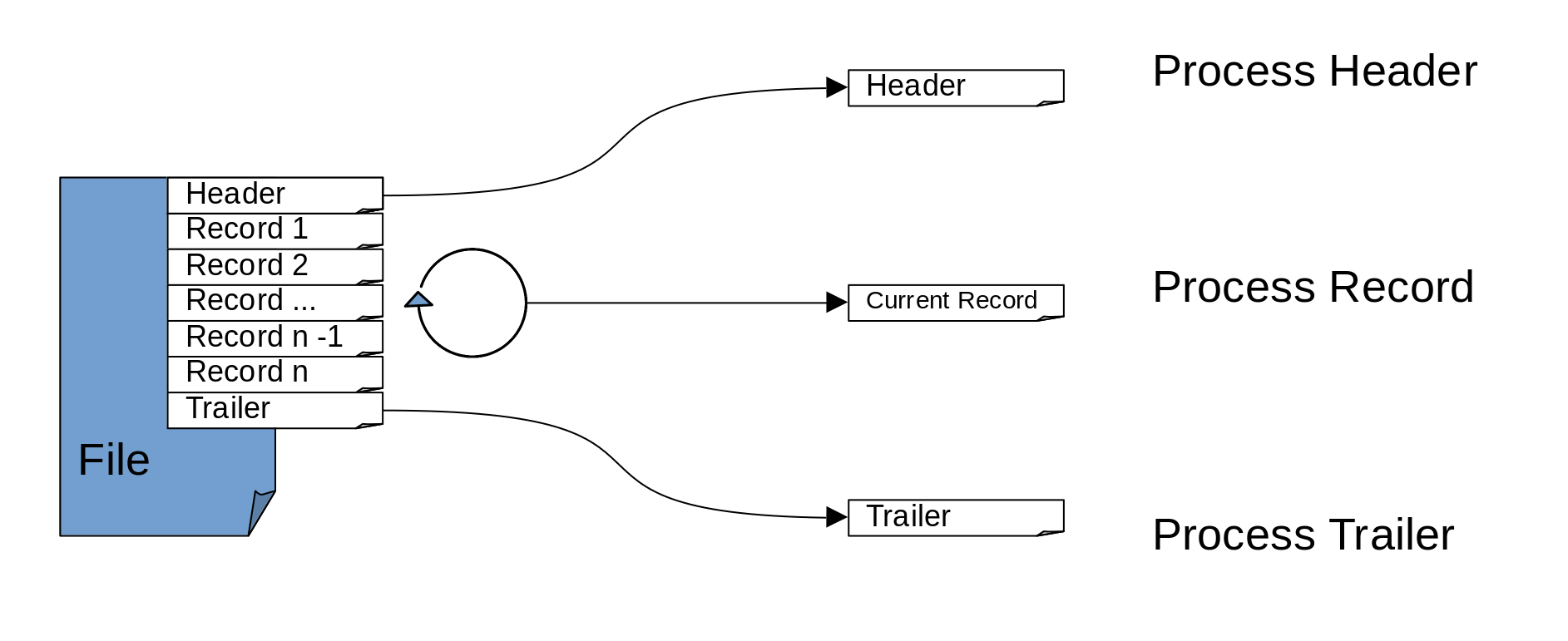
The flow will first read and parse the header section. It will then remember the offset into the file and use this offset to start the loop which reads each individual record. Since the read from the file will be occurring in the middle of the flow, we will use the FileRead Node rather than the FileInput Node. Once all the records have been read the trailer will be read and processed and finally the reconciliation logic will be executed as part of the trailer processing. We will use the DFDL parser to segment the message up into its component pieces and then process these one at a time, only ever holding one record in memory at once.
The final implementation of the flow is pictured below:
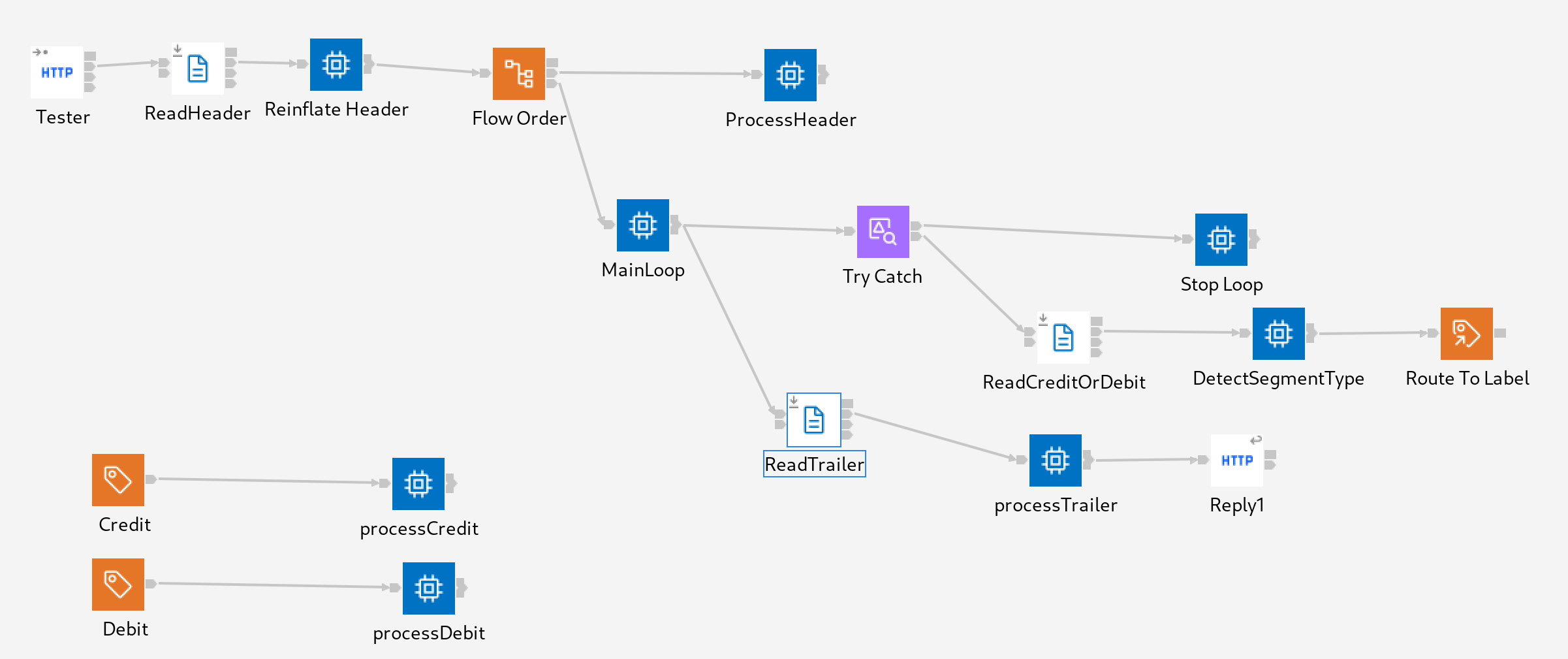
Let's step through the control flow in sequence.
- The flow is initiated by an HTTPInput node, this only serves to start processing and has no impact on the actual implementation. In a production flow the flow could be triggered by a File Exists node (introduced in 12.0.4.0) to avoid the need for an explicit manual trigger.
- The first FileRead node is set to use a Parsed Record Sequence using a DFDL model which consumes the xml decl and then treats all of the content between the HEADER tags as hex binary. This processing has 2 purposes. Firstly, it reads into memory any data we need from the header so that it can be stored for use as context later in the flow. Secondly, it tells us the offset in the file where the first repeating element begins.
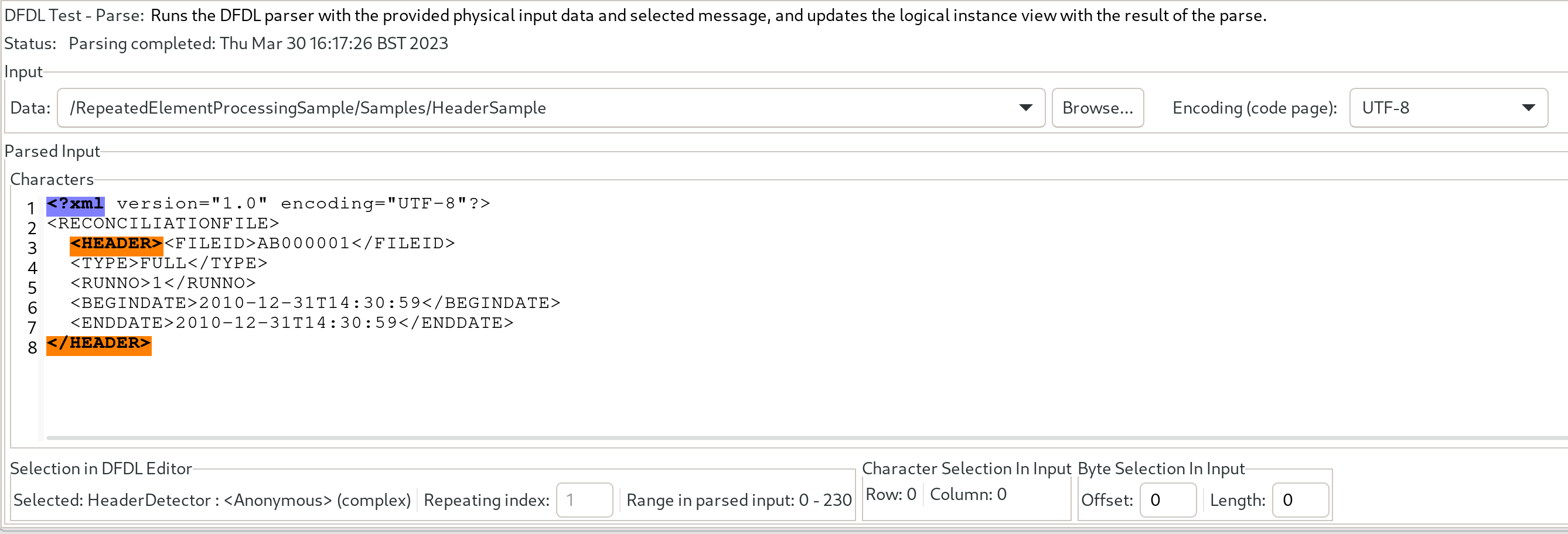
This FileRead Node uses the "HeaderDetector" message definition in the DFDL model and this consists of 2 sections. Firstly a preamble which is set to use an Initiator of "<?xml" and a terminator of "<HEADER>" and finally a HeaderContent section which has no initiator and a terminator of "</HEADER>". We can see from the DFDL test client image below the section bitstream portions identified as Initiators and Terminators:
So once the ReadHeader Node has finished executing, the following content will be stored as hexBinary in the HeaderContent element in the message tree:![]() XML
XML<FILEID>AB000001</FILEID> <TYPE>FULL</TYPE> <RUNNO>1</RUNNO> <BEGINDATE>2010-12-31T14:30:59</BEGINDATE> <ENDDATE>2010-12-31T14:30:59</ENDDATE> - The reinflate Header compute node adds back the HEADER tags which were consumed as markup by the DFDL parser and then uses the XML parser to parse the data into a usable format in the tree.
It would be possible to make the DFDL model aware of the elements inside the tags and avoid an XML parse but this would have complicated the model so for the sake of clarity this has been omitted from the example.SQL
DECLARE header BLOB; SET header = InputRoot.DFDL.HeaderDetector.HeaderContent; SET header = CAST('<HEADER>' AS BLOB CCSID 819) || header || CAST('</HEADER>' AS BLOB CCSID 819); CREATE LASTCHILD OF OutputRoot DOMAIN('XMLNSC') PARSE(header); - A flow order node routes the message first to the Process Header node where the Header content is stored in the Environment for later use in the flow. This data will form part of the final reconciliation process.
SQL
CREATE COMPUTE MODULE Reconcile_Large_File_processHeader CREATE FUNCTION Main() RETURNS BOOLEAN BEGIN -- In this node any processing required by the header is implemented -- If any context is required to complete the entire file processing at the end this can be place -- in the Environment, the key here is that we only hold this context information, we dont hold -- all of the repeating elements. -- In this case just store all the content for later CREATE LASTCHILD OF Environment.Variables DOMAIN('XMLNSC') NAME('HeaderContext'); -- we copy into a new parser here to avoid the elements going out of scope when we backtrack along the flow SET Environment.Variables.HeaderContext = OutputRoot.XMLNSC.header; --We also initialize some variables for tracking as we process each record SET Environment.Variables.TotalCredits = 0; SET Environment.Variables.TotalRecords = 0; SET Environment.Variables.TotalDebits = 0; RETURN TRUE; END; - The execution is then routed to the Main Loop compute node. This node loops until a flag in the Environment is set. The idea here is that downstream of the main loop when the end of all repeating elements is detected a node will set this flag and cause execution to breakout to the next section of the flow.
SQL
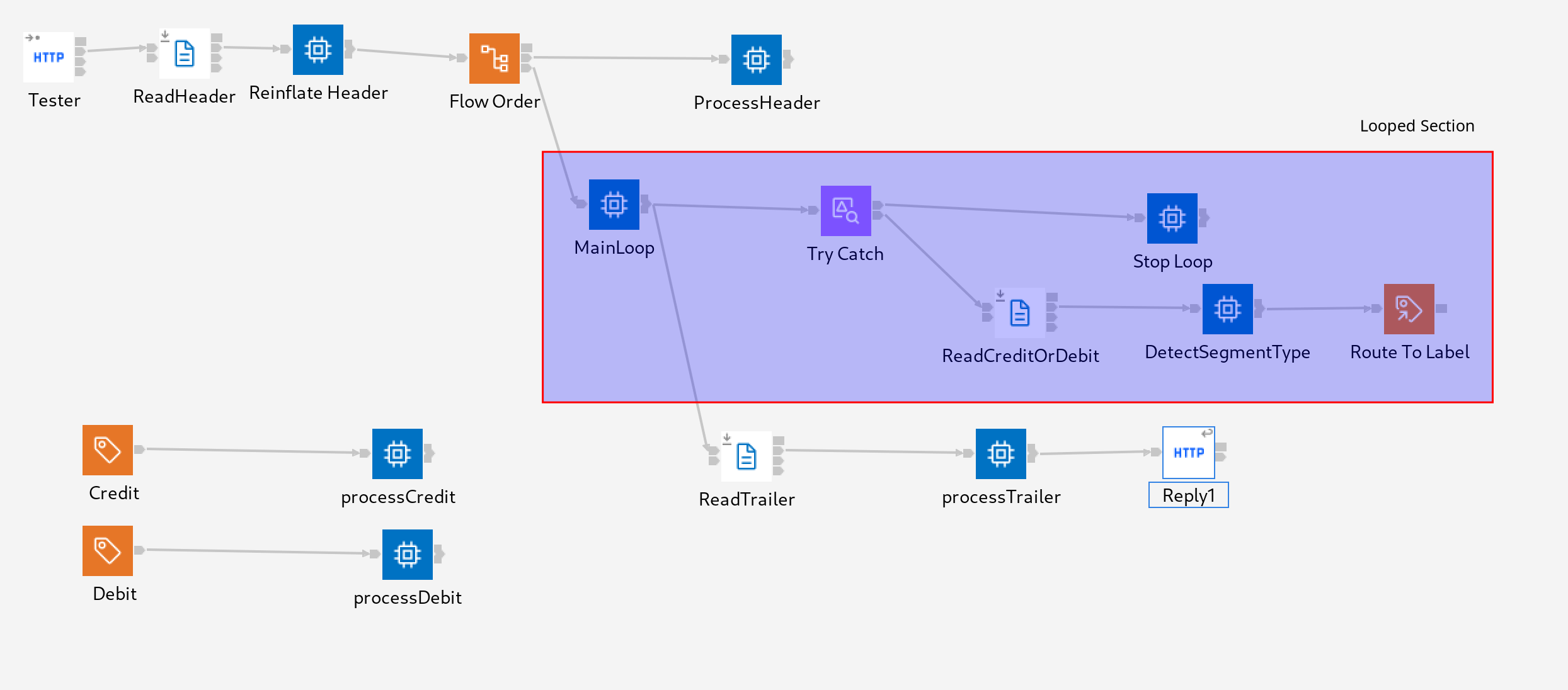
CREATE COMPUTE MODULE Reconcile_Large_File_MainLoop CREATE FUNCTION Main() RETURNS BOOLEAN BEGIN SET OutputLocalEnvironment.Destination.File.Offset = InputLocalEnvironment.File.Read.NextRecordOffset; -- The ProcessingRepeatingElements will be set to false when we reach the end of the -- repeating element sequence. SET Environment.Variables.ProcessingRepeatingElements = TRUE; WHILE Environment.Variables.ProcessingRepeatingElements DO PROPAGATE TO TERMINAL 'out'; SET OutputLocalEnvironment.Destination.File.Offset = Environment.Variables.FileReadData.NextRecordOffset; END WHILE; PROPAGATE TO TERMINAL 'out1'; -- return false to prevent propagating again to 'out' RETURN FALSE; END; END MODULE;Note that here we need to use the Environment tree rather than the LocalEnvironment because we want changes made in a later downstream node to be able to terminate the loop condition. The marked section on the flow diagram shows the portion of the flow that loops.
![]()
It is also important to note here that the loop is a "flat" loop. That is the loop fully unwinds back to the "MainLoop" compute node. If the loop was instead constructed so that execution was routed back into this compute node or achieved through RouteToLabel nodes then this could cause a stack overflow for files with a very large number of records. - Execution is propagated to a try/catch node. This is required because the File Read node will throw an exception when it is not able to match the trailer data to the repeating record model and we use the exception as the mechanism for stopping our main loop.
- On the try path we have another FileRead Node, this node reads a single instance of the repeating record. In this use case the repeating element could have been one of several different record types either "Credit" or "Debit" records. The structure of these records is identical for the purposes of this example, but this technique would work with repeating elements of different types provided markup could be identified which distinguishes them.
The repeated element is implemented by the model "CreditOrDebitDetector" which will match a DFDL choice based single entry based on the CREDIT or DEBIT xml tags and extract its content as hex binary. Here the CREDIT or DEBIT tags are used as the markup and note the use of the %WSP* mnemonic to consume any leading whitespace.![]()
- The compute node DetectSegment type examines the fieldname of the DFDL message to route processing to a label based on which specific type of record was received.
SQL
CREATE COMPUTE MODULE Reconcile_Large_File_DetectSegmentType CREATE FUNCTION Main() RETURNS BOOLEAN BEGIN -- Ensure the main loop can see if this was the last record and get offset information DELETE FIELD Environment.Variables.FileReadData; SET Environment.Variables.FileReadData = InputLocalEnvironment.File.Read; --Set the routing information to the segment type DECLARE name CHAR; DECLARE nameRef REFERENCE TO InputRoot.DFDL.CreditOrDebitDetector; MOVE nameRef LASTCHILD; SET name = FIELDNAME(nameRef); SET OutputLocalEnvironment.Destination.RouterList.DestinationData[1].labelName = name; SET OutputRoot = InputRoot; PROPAGATE TO TERMINAL 'out'; RETURN FALSE; END; END MODULE;Note also that this node stores metadata that the FileRead node creates in the LocalEnvironment so that the MainLoop compute node can use this to iterate to the next loop in the repeating element sequence.
- Execution is routed to either the "processCredit" or "processDebit" Compute Node depending on the record type. These nodes simulate the actual business logic that would be performed for each record. The message is parsed using the XMLNSC parser in the same way as the Reinflate Header node. In this instance to simulate business logic we update the total number of records processed and also keep a running sum of the number of credits and debits. For example:
SQL
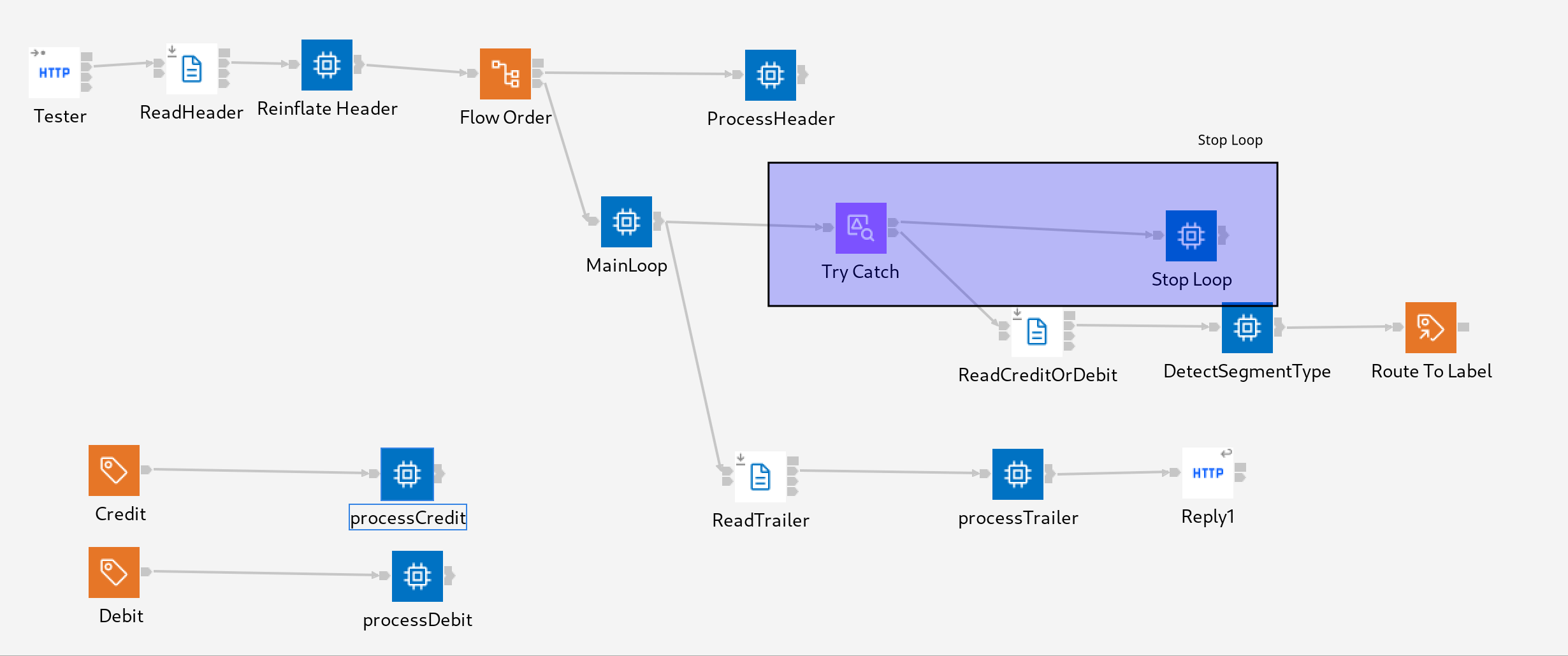
CREATE COMPUTE MODULE Reconcile_Large_File_processCredit CREATE FUNCTION Main() RETURNS BOOLEAN BEGIN DECLARE credit BLOB; SET credit = InputRoot.DFDL.CreditOrDebitDetector.Credit.content; SET credit = CAST('<CREDIT>' AS BLOB CCSID 819) || credit || CAST('</CREDIT>' AS BLOB CCSID 819); CREATE LASTCHILD OF OutputRoot DOMAIN('XMLNSC') PARSE(credit); SET Environment.Variables.TotalCredits = Environment.Variables.TotalCredits + CAST(OutputRoot.XMLNSC.CREDIT.AMOUNT AS DECIMAL); SET Environment.Variables.TotalRecords = Environment.Variables.TotalRecords + 1; RETURN TRUE; END; END MODULE; - Steps 6 to 9 repeat until the last record. At this point the FileRead Node throws an exception, and this is caught and handled in the Stop Loop compute node which sets a flag in the environment and the returns.
![]()
SQLCREATE COMPUTE MODULE Reconcile_Large_File_Stop_Loop CREATE FUNCTION Main() RETURNS BOOLEAN BEGIN SET Environment.Variables.ProcessingRepeatingElements = FALSE; RETURN TRUE; END; END MODULE; - The presence of the flag causes the loop in the MainLoop compute node to terminate, and the message is propagated to the ReadTrailer node.
SQL
WHILE Environment.Variables.ProcessingRepeatingElements DO - The ReadTrailer node uses a DFDL model to consume the entire trailer of the message and this is passed to processTrailer in a similar way to the processing of the Header.
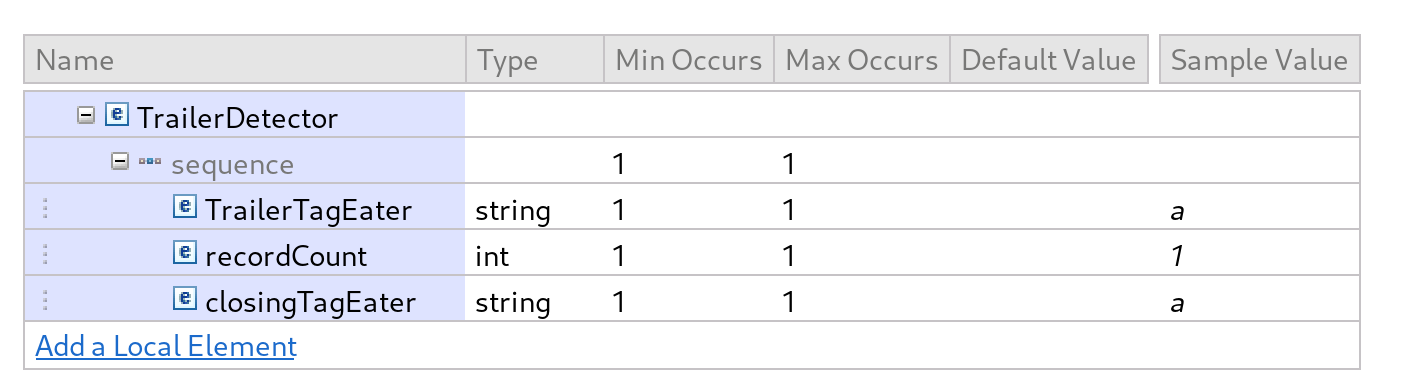
- In the processTrailer compute node, the Trailer entry is modelled completely as a DFDL message with no need to re-parse and the expected record count is extracted. This is compared to the running count of records accumulated in the environment to simulate a reconciliation process.
![]() SQL
SQLCREATE COMPUTE MODULE Reconcile_Large_File_processTrailer CREATE FUNCTION Main() RETURNS BOOLEAN BEGIN DECLARE recordCount INTEGER; SET recordCount = InputRoot.DFDL.TrailerDetector.recordCount; CREATE LASTCHILD OF OutputRoot DOMAIN('XMLNSC'); IF Environment.Variables.TotalRecords <> recordCount THEN SET OutputRoot.XMLNSC.ReconciliationResult.Result = 'FAILED'; SET OutputRoot.XMLNSC.ReconciliationResult.Reason = 'The number of records processed did not match the count provided in the RECORD COUNT element of this message'; ELSE SET OutputRoot.XMLNSC.ReconciliationResult.Result = 'SUCCESS'; END IF; SET OutputRoot.XMLNSC.ReconciliationResult.TotalCredits = Environment.Variables.TotalCredits; SET OutputRoot.XMLNSC.ReconciliationResult.TotalDebits = Environment.Variables.TotalDebits; SET OutputRoot.XMLNSC.ReconciliationResult.Balance = Environment.Variables.TotalCredits - Environment.Variables.TotalDebits; SET OutputRoot.XMLNSC.ReconciliationResult.TotalRecordsProcessed = Environment.Variables.TotalRecords; SET OutputRoot.XMLNSC.ReconciliationResult.ExpectedRecords = recordCount; RETURN TRUE; END; END MODULE; - Finally, the message is sent back to the originating client via the HTTP Reply node. The final output after executing the flow on a 2Gb file is:
XML
<ReconciliationResult> <Result>SUCCESS</Result> <TotalCredits>302271278771.47</TotalCredits> <TotalDebits>325414616363.66</TotalDebits> <Balance>-23143337592.19</Balance> <TotalRecordsProcessed>12549665</TotalRecordsProcessed> <ExpectedRecords>12549665</ExpectedRecords> </ReconciliationResult>The memory usage of the Integration Server after processing the file can be seen below:
![]()
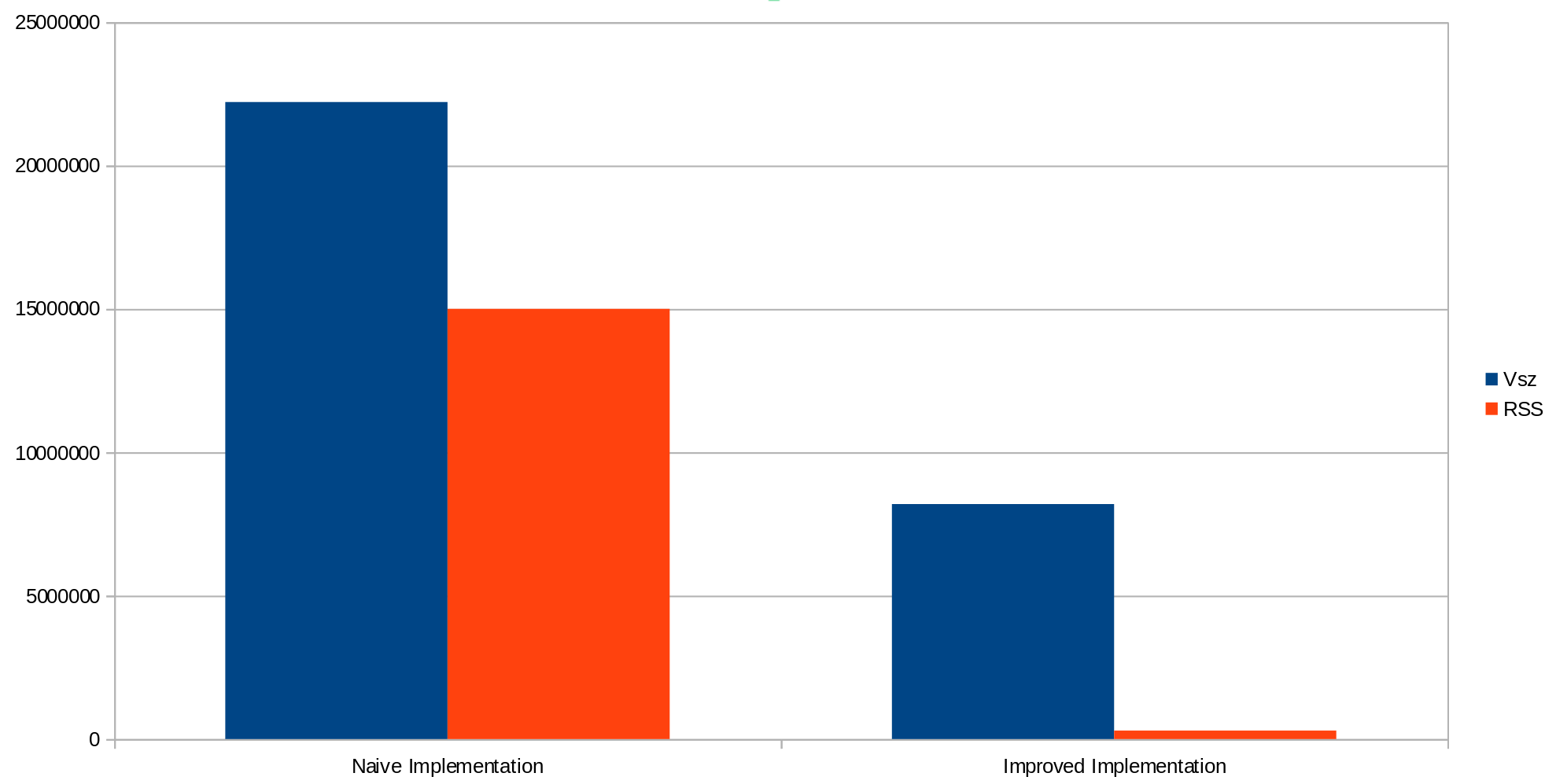
Comparing against the naive implementation we can see a substantial improvement:
![]()


Further Thoughts
In this article, we have focused on a use case where we wanted to keep all execution in a single flow invocation to ensure that the transaction was atomic. That is, either the entire file is processed, or the entire file failed. One drawback of this approach is that it limits the operation to a single thread. For some use cases, it may be more desirable to split the message up into records which can be processed in parallel, particularly if the processing cost per record is high. To do this the flow could be modified to serialise individual records onto an MQ queue which could then be read by multiple instances of a flow.
Additionally, the current implementation performs I/O for every record. On some systems, the latency associated with lots of small file read operations may be greater than that of a smaller number of larger file reads. In this case, it may be more performant to sacrifice some memory efficiency in exchange for lower I/O latency. In this case it may be better to have the main loop read batches of records in at a time, for example, 50 records at a time.
Such improvements and extensions are left as an exercise to the reader.
Conclusion
In this article, we have explored how we can improve the memory efficiency of flows which process large files that comprise repeating elements. We have discussed some of the limitation of a naive approach as well as how these can be overcome with a more efficient flow design. We have also used the DFDL parser to segment the message which allows us to read nested portions of an XML message without needing to parse the entire message at once. Using these techniques, we have seen a 39393Mb reduction in the RSS memory requirements for processing this message.
The project interchange containing both message flows discussed is available here.
Published at DZone with permission of Dave Crighton. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments