Provisioning Postgres From Docker to Kubernetes
Creating a container for a database isn't overkill. In fact, it allows you to bring all the advantages of containers to your DB. This article will show you how.
Join the DZone community and get the full member experience.
Join For Free
In this post, we will see how to create a Postgres container using Docker and restart Postgres containers without losing data. At the end of the article, we will deploy Postgres inside Kubernetes pods with a custom deployment that utilizes ConfigMaps and StatefulSets. Previously, we covered how to deploy Postgres inside Kubernetes using Helm charts - the Kubernetes package management system.
Why Use Containerized Databases?
Creating a container for a database may seem to add unnecessary overhead compared to simply installing it on a server. However, it allows users to bring all the advantages of containers to bear on their databases.
Separate Data and the Database
Containerization allows users to separate the database application and the data. As a result, it increases fault tolerance by enabling users to spin up a new container in the event of an application failure without affecting the underlying data. Additionally, containerization also allows users to scale and increase the availability of the database with relative ease.
Portability
The portability of containers helps users deploy and migrate databases to any supported containerized environment without any infrastructure or configuration changes. They also enable users to make configuration changes to the database application with minimal to no impact on underlying data in production environments. Furthermore, these containers lead to better resource utilization and decreased overall costs as they are inherently lightweight compared to other solutions like VMs.
Creating a Containerized Database
First, we need an image to act as the base for our container. While we can create an image from scratch, it will be unnecessary in most cases as common software like Postgres provides official container images with the option to customize the container. Therefore, we will use the official Postgres image in the Docker hub for creating this database container.
Next up? Time to create the container configuration. This can be done easily via the docker-compose file.
version: '3.1'
services:
postgres-db:
container_name: postgres-db
image: postgres:latest
restart: always
environment:
POSTGRES_USER: testadmin
POSTGRES_PASSWORD: test123
POSTGRES_DB: testdb
PGDATA: /var/lib/postgresql/data/pgdata
volumes:
- postgres-db-data:/var/lib/postgresql/data
ports:
- 5432:5432
volumes:
postgres-db-data:
name: postgres-db-data
We create a docker volume to store the Postgres data in the above configuration. Since this volume is reusable, you can recover the underlying data even if the container is removed. For the Postgres container, we use the latest Postgres image with environment variables setting the user, password, database, and data location within the container. In the volume section, we map the internal container data location to our volume and expose port 5432.
Once the file is created, we can run the docker-compose up command to start the container.
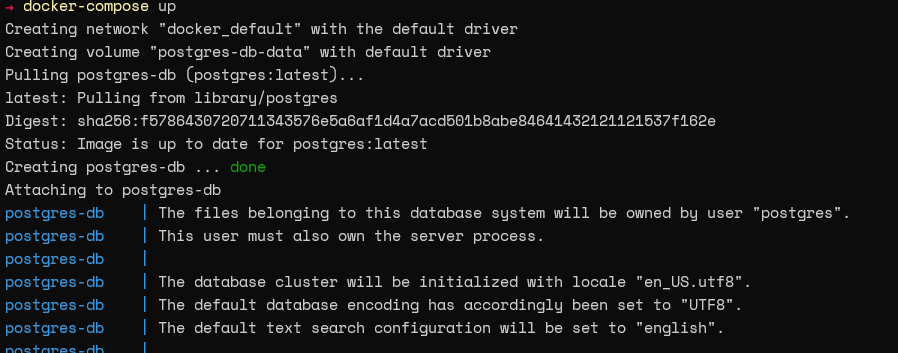
Next, we can run the docker ps command to see if the container is running successfully.
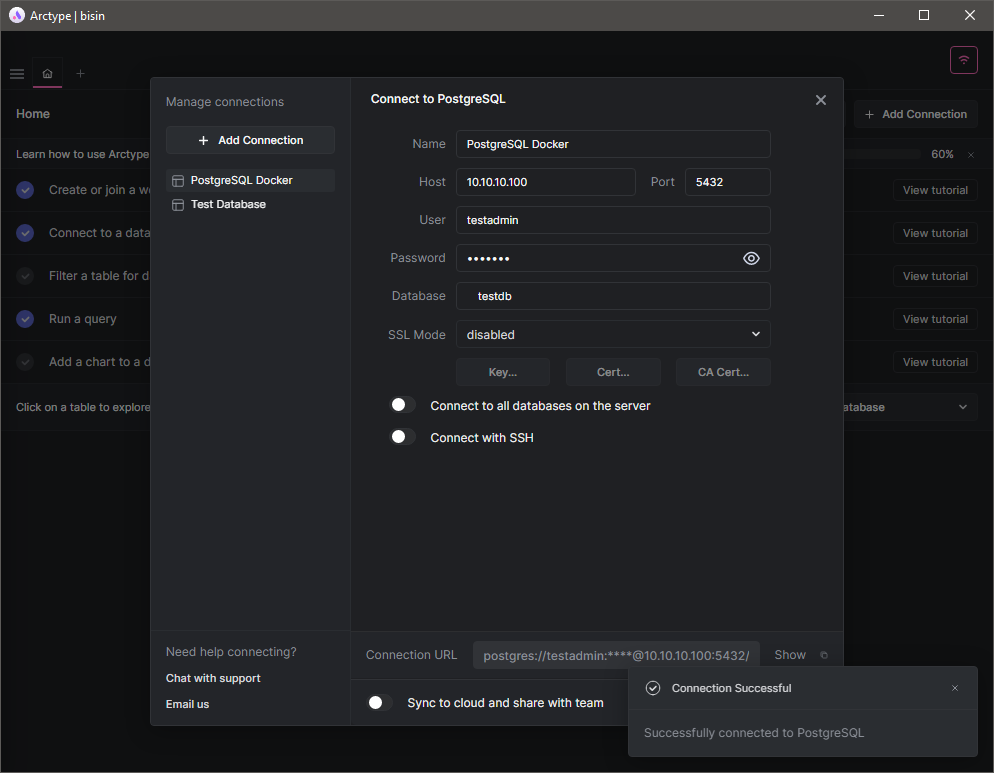
That's it. We have successfully created a containerized Postgres database. Is it working? We can verify that by trying to connect to the database via a SQL client. So let's use the Arctype SQL client to initialize a test connection. First, provide the database connection details. In this instance, we'll use the IP of the Docker host, port, and the credentials we supplied when creating the container. Then, as you can see in the following image, we can successfully initialize a connection to the database.
Creating a Repeatable Configuration
As mentioned previously, containers allow users to decouple the database data from the application and enable repeatable configurations. For example, assume that you encountered an error in your database software. In a traditional installation, this can lead to disastrous consequences, as both data and application are bound together. Even rollbacks are not possible, as they would result in data loss. However, containerization allows you to remove the errored container, spin up a new instance, and immediately access the data.
Let's have a look at this scenario in practice. First, let's create a table named test_data_table and insert some records into it using the Arctype client.

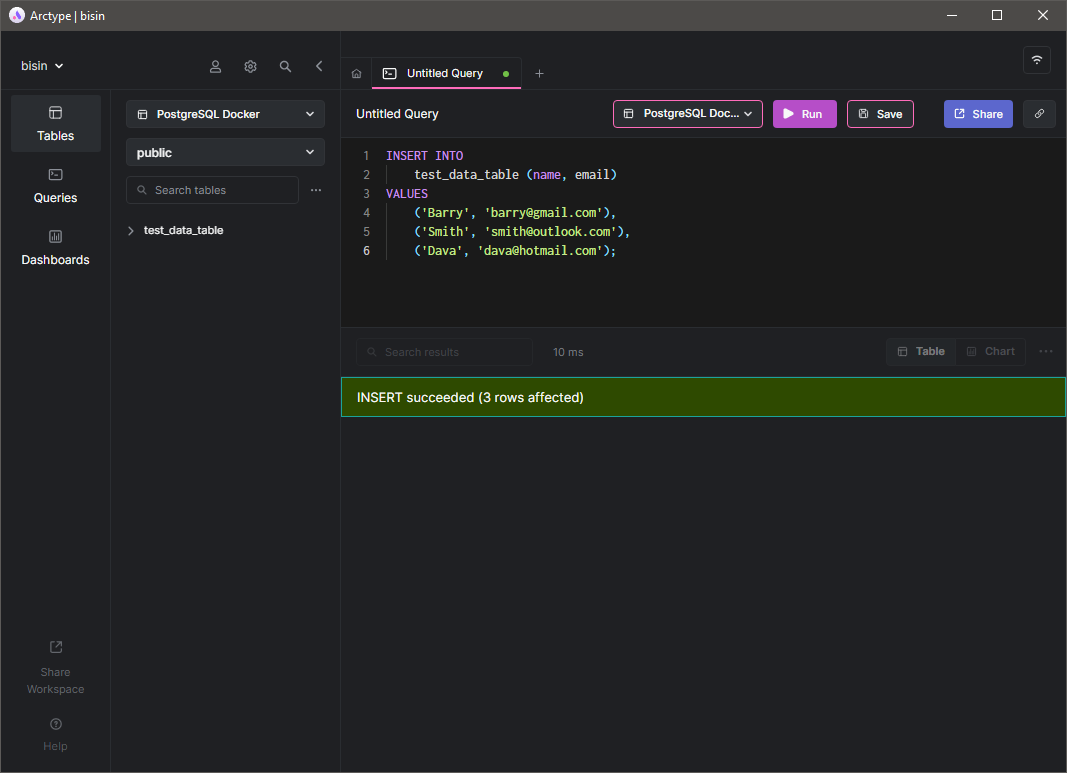
Now we have some data in the database. Let's remove the container using the docker-compose down command, which will delete the container from the docker environment.
Note - When the container is deleted, the SQL client will show an error saying connection refused.
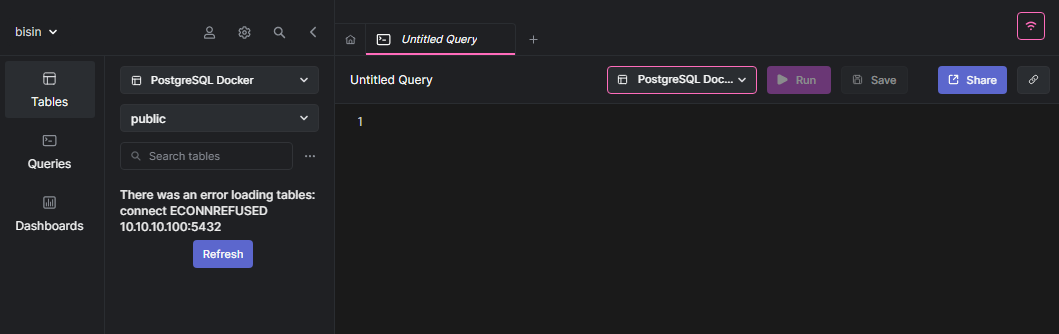
Next, let's make a slight modification to the compose file to change the container's name.
version: '3.1'
services:
postgres-db:
# New Container
container_name: postgres-db-new
image: postgres:latest
restart: always
environment:
POSTGRES_USER: testadmin
POSTGRES_PASSWORD: test123
POSTGRES_DB: testdb
PGDATA: /var/lib/postgresql/data/pgdata
volumes:
- postgres-db-data:/var/lib/postgresql/data
ports:
- 5432:5432
volumes:
postgres-db-data:
name: postgres-db-data
Next, spin up the container again and verify if it is running using the docker ps command.

Refresh the tables in the Arctype client to reestablish the connection. Then run a simple SELECT command to query for data in the test_data_table as shown below.

As you can see, we can recreate the container and access the data even if the container is removed.
Managing Containers Using Kubernetes
Docker is an excellent choice for local development environments or even running a few containers in a production environment. However, as most production environments consist of many containers, managing them quickly becomes unfeasible. This is where orchestration platforms like Kubernetes come into play, offering a complete feature-rich container orchestration platform to manage containers at scale.
The best way to deploy a Postgres container in Kubernetes is using a StatefulSet. It enables users to provision stateful applications and configure persistent storage, unique network identifiers, automated rolling updates, ordered deployments and scaling. All these features are required to facilitate stateful applications like a database. This section will see how to deploy Postgres containers in a K8s cluster.
Creating and Deploying a Postgres Pod
For this deployment, we will create a configmap to store our environment variables, a service to expose the database outside the cluster, and the StatefulSet for the Postgres Pod.
# PostgreSQL StatefulSet ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-db-config
labels:
app: postgresql-db
data:
POSTGRES_PASSWORD: test123
PGDATA: /data/pgdata
---
# PostgreSQL StatefulSet Service
apiVersion: v1
kind: Service
metadata:
name: postgres-db-lb
spec:
selector:
app: postgresql-db
type: LoadBalancer
ports:
- port: 5432
targetPort: 5432
---
# PostgreSQL StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgresql-db
spec:
serviceName: postgresql-db-service
selector:
matchLabels:
app: postgresql-db
replicas: 2
template:
metadata:
labels:
app: postgresql-db
spec:
# Official Postgres Container
containers:
- name: postgresql-db
image: postgres:10.4
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5432
# Resource Limits
resources:
requests:
memory: "265Mi"
cpu: "250m"
limits:
memory: "512Mi"
cpu: "500m"
# Data Volume
volumeMounts:
- name: postgresql-db-disk
mountPath: /data
# Point to ConfigMap
env:
- configMapRef:
name: postgres-db-config
# Volume Claim
volumeClaimTemplates:
- metadata:
name: postgresql-db-disk
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 25GiThe above configuration can be summed up in the following points:
- ConfigMap - postgres-db-config: This ConfigMap defines all the environment variables required by the Postgres container.
- Service - postgres-db-lb: The load balancer type service is defined to expose the Pods outside the container using port 5432
- StatefulSet - postgresql-db: StatefulSet is configured with two replicas using the Postgres container image with data mounted to a persistent volume. Additional resource limits are configured for both the container and the volume.
After creating this configuration, we can apply it and verify the StatefulSet using the following commands.
kubectl apply -f .\postgres-statefulset.yaml
kubectl get all
kubectl get pvc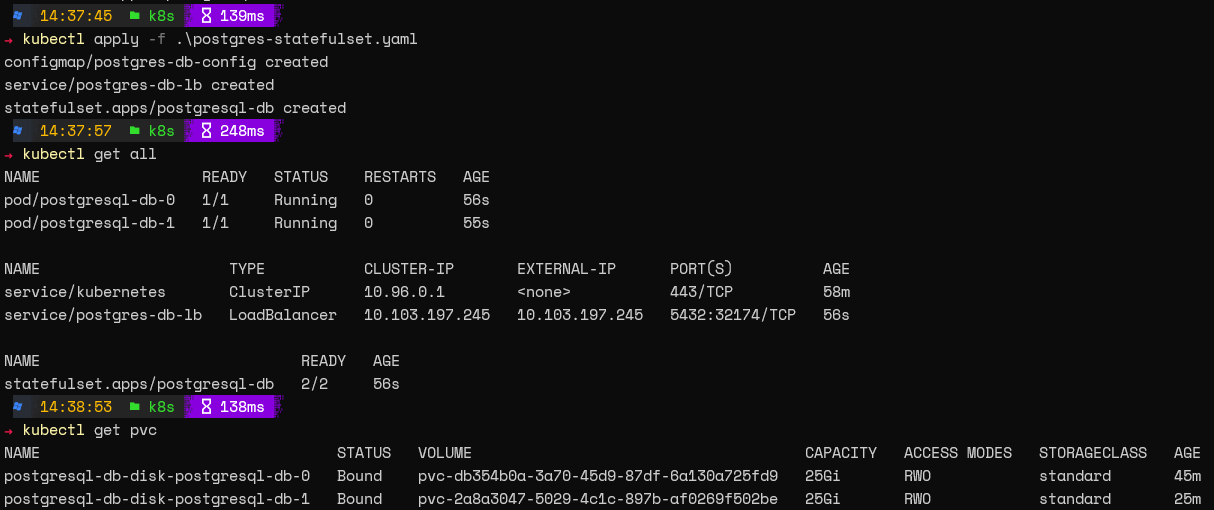
That's it! You have successfully configured the Postgres database on Kubernetes.
Accessing the Database
Since we have running Pods now, let's access the database. As we have set up a service, we can access the database using the external IP of that service. Provide the server details such as the default user and database (Postgres) using the Arctype client and test the connection.
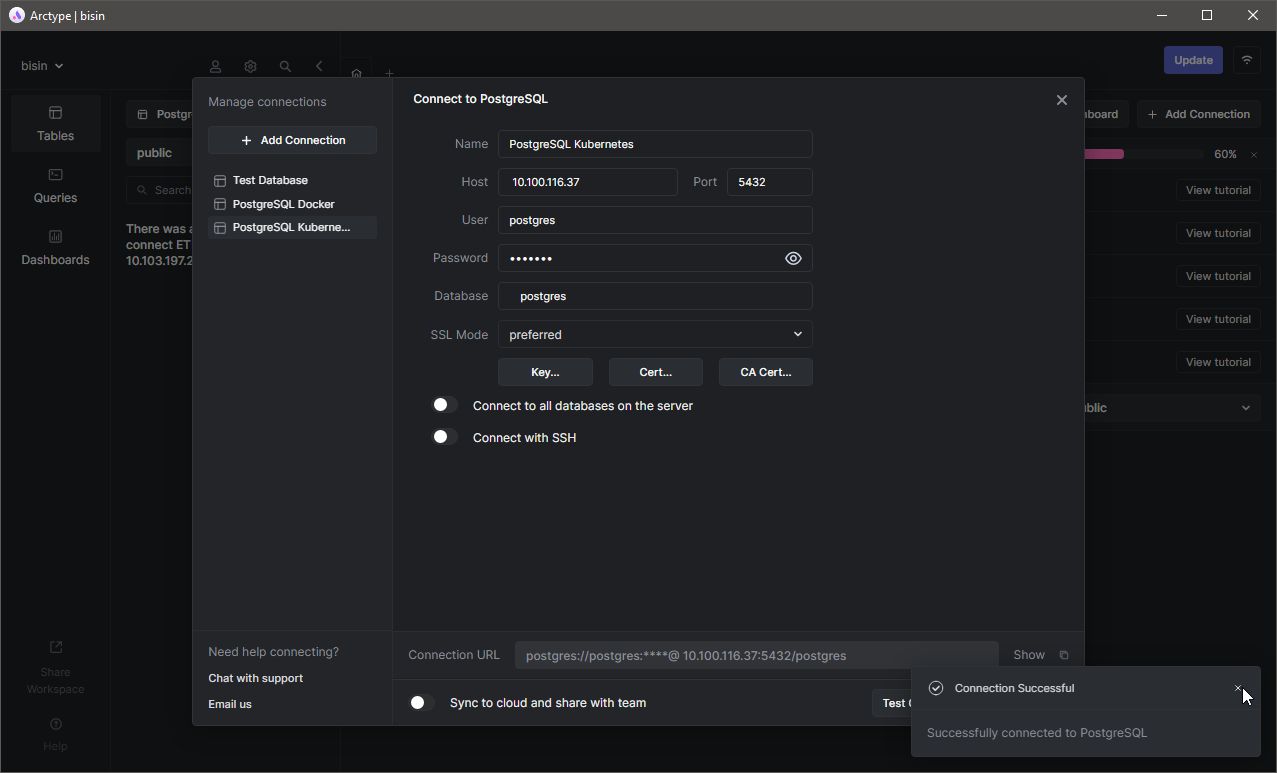
As with the docker example, let's create a table named test_data_table and add some records. Here, we will delete the entire StatefulSet. If we have configured everything correctly, the data will remain while the Pods get deleted.

Now, let's reset the StatefulSet and try accessing the database. As this is a new deployment, you will see a new external IP associated with the service.
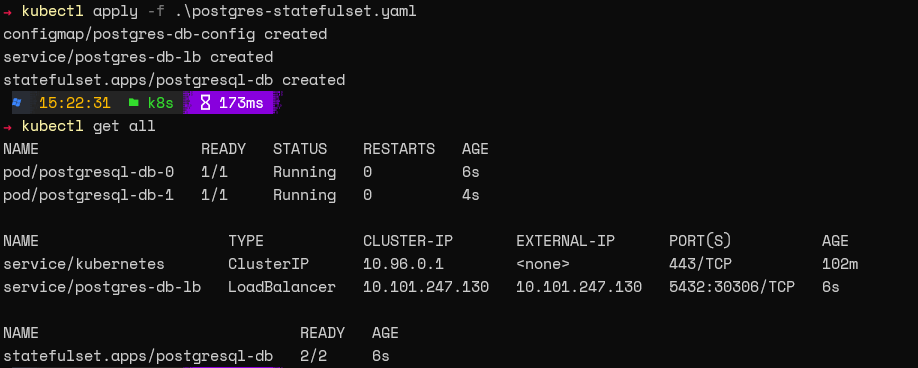
Modify the connection string on the Arctype SQL client and attempt to connect.

Then you will see the table we created previously. You will be able to reveal all the data in the table by running a SELECT command signifying that data is available regardless of the state of the Pods.

Best Practices When Working With Database Pods
There are some best practices to follow when deploying databases in Kubernetes to gain the best reliability and performance.
- Use Kubernetes Secrets to store sensitive information such as passwords. Even though we stored the user password in plaintext in our configuration for simplicity, any sensitive information should be stored in secrets in the production environment and referenced when needed.
- Implement resource limits for CPU, RAM, and storage. This helps manage resources within the cluster and ensures that Pods does not overconsume resources.
- Always configure backups for your volumes. Even if Pods can be recreated, the entire database will become unusable if the underlying data volumes get corrupted.
- Implement network policies and RBAC to control ingress and the users who can modify these resources for the best performance and security.
- Use separate namespaces to isolate databases from normal applications and manage connectivity through services.
Conclusion
Creating containerized databases allows users to harness all the benefits of containerization and apply them to databases. This containerization is applicable to any database, from market leaders like MySQL and Postgres to newer contenders designed from the ground up for cloud-native applications. For instance, Yugabytedb is a new database that can be run on any Kubernetes environment, like Amazon EKS. Managing containerized databases enables users to facilitate fault-tolerant, highly available, and scalable database architectures with a fraction of the resources required by traditional database deployments.
Published at DZone with permission of Shanika WIckramasinghe. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments