Pull Requests and Tech Debt
We all do pull requests, but are we doing them right? However well-intentioned, pull requests can actually contribute to tech debt when you're not careful!
Join the DZone community and get the full member experience.
Join For FreeI recently created a small DSL that provided state-based object validation, which I required for implementing a new feature. Multiple engineers were impressed with its general usefulness and wanted it available for others to leverage via our core platform repository. As most engineers do (almost) daily, I created a pull request: 16 classes/435 lines of code, 14 files/644 lines of unit tests, and six supporting files. Overall, it appeared fairly straightforward – the DSL is already being used in production – though I expected small changes as part of making it shareable.
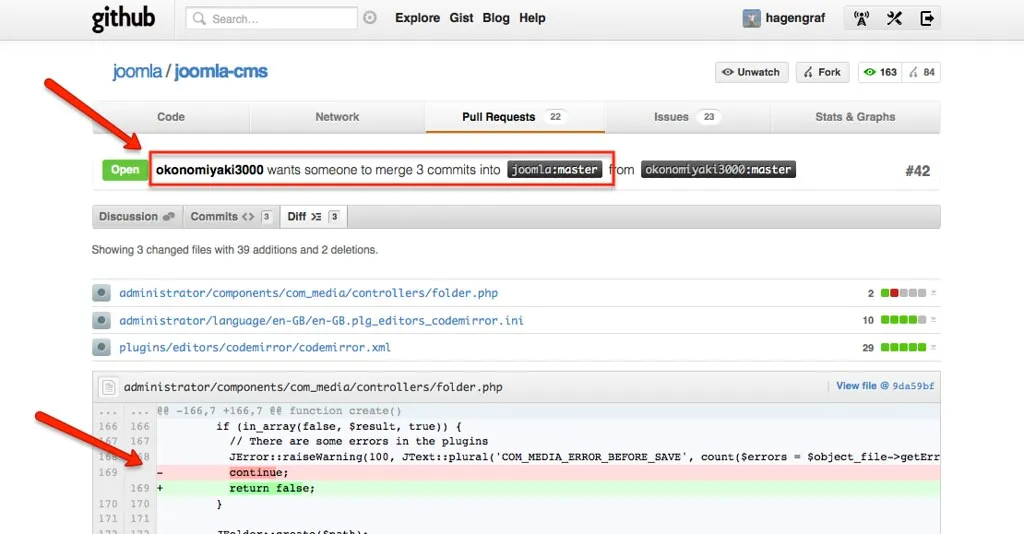 Boy, was I mistaken! The pull request required 61 comments and 37 individual commits to address (appease) the two reviewers’ concerns, encompassing approximately ten person-hours of effort before final approval. By a long stretch, the most traumatizing PR I’ve ever participated in!
Boy, was I mistaken! The pull request required 61 comments and 37 individual commits to address (appease) the two reviewers’ concerns, encompassing approximately ten person-hours of effort before final approval. By a long stretch, the most traumatizing PR I’ve ever participated in!
What was achieved? Not much, in all honesty, as the requested changes were fairly niggling: variable names, namespace, exceptions choice, lambda usage, unused parameter. Did the changes result in cleaner code? Perhaps slightly, did remove comment typos. Did the changes make the code easier to understand? No, believe it is already fairly easy to understand. Were errors, potential errors, race conditions, or performance concerns identified? No. Did the changes affect the overall design, approach, or implementation? Not at all.
That final question is most telling: for the time spent, nothing useful was truly achieved. It’s as if the reviewers were shaming me for not meeting their vision of perfect code, yet comments and the code changes made were ultimately trivial and unnecessary.
Don’t misinterpret my words: I believe code reviews are necessary to ensure some level of code quality and consistency. However, what are our goals, are those goals achievable, and how far do we need to take them? Every engineer’s work is impacted by what they view as important in their work: remember, Hello World has been implemented in uncountable different ways, all correct and incorrect, depending on your personal standards.
My conclusion: Perfect code is unattainable; understandable and maintainable code is much more useful to an organization.
Code Reviews in the Dark Ages

Writing and reviewing code was substantially different in the not-so-distant past when engineers debated text editors (Emacs, thank you very much) when tools such as Crucible, Collaborator, or GitHub were a gleam in their creators’ eyes, when software development was not possible on laptops when your desktop was plugged into a UPS to prevent inadvertent losses—truly the dark ages.
Back then, code reviews were IRL and analog: schedule a meeting, print out the code, and gather to discuss the code as a group. Most often, we started with higher-level design docs, architectural landmarks, and class models, then dove deeper into specific areas as overall understanding increased. Line-by-line analysis was not the intention, though critical or complicated areas might require detailed analysis. Engineers focus on different properties or areas of the code, therefore ensuring diversity of opinions, e.g., someone with specific domain knowledge makes sure the business rules, as she understands them, are correctly implemented. The final outcome is a list of TODOs for the author to ponder and work on.
Overall, a very effective process for both junior and senior engineers, allowing a forum to share ideas, provide feedback, learn what others are doing, ensure standard adherence, and improve overall code quality. Managers also learn more about their team and team dynamics, such as who speaks up, who needs help to grow, who is technically not pulling their weight, etc.
However, it’s time-consuming and expensive to do regularly and difficult to not take personally: it is your code, your baby, being discussed, and it can feel like a personal attack. I’ve had peers who refused to do reviews because they were afraid it would affect their year-end performance reviews. But there’s no other choice: DevOps is decades off, test-driven development wasn’t a thing, and some engineers just can’t be trusted (which, unfortunately, remains true today).
Types of Pull Requests
Before digging into the possible reasons for tech debt, let’s identify what I see as the basic types of pull requests that engineers create:
Bug Fixes
The most prevalent type – because all code has bugs – is usually self-contained within a small number of files. More insidious bugs often require larger-scale changes and, in fact, may indicate more fundamental problems with the implementation that should be addressed.
Mindless Refactors
Large-scale changes to an existing code base, almost exclusively made by leveraging your IDE: name changes (namespace, class, property, method, enum values), structural changes (i.e., moving classes between namespaces), class/method extraction, global code reformatting, optimizing Java imports, or other changes that are difficult when attempted manually.
Reviewers often see almost-identical changes across dozens – potentially hundreds – of files and require trust that the author did not sneak something else in, intentionally or not.
Thoughtful Refactors
The realization that the current implementation is already a problem or is soon to become one, and you’ll be dealing with the impact for some time to come. It may be as simple as centralizing some business logic that had been cut and pasted multiple times or as complicated as restructuring code to avoid endless conditional checks. In the end, you hope that everything functions as it originally did.
Feature Enhancements
Pull requests are created as the code base evolves and matures to support modified business requirements, growing usage, new deployment targets, or something else. The quantity of changes can vary widely based on the impact of the change, especially when tests are substantially affected.
Managing the release of the enhancements with feature flags usually requires multiple rounds of pull requests, first to add the enhancements and then to remove the previously implemented and supporting feature flags.
New Features
New features for an existing application or system may require adding code to an existing code base (i.e., new classes, methods, properties, configuration files, etc.) or an entirely new code base (i.e., a new microservice in a new source code repository). The number of pull requests required and their size varies widely based on the complexity of the feature and any impact on existing code.
Greenfield Development
An engineer’s dream: no existing code to support and maintain, no deprecation strategies required to retire libraries or API endpoints, no munged-up data to worry about. Very likely, the tools, tech stack, and deployment targets change. Maybe it’s the organization’s first jump into truly cloud-native software development. Engineers become the proverbial kids in a candy store, pushing the envelope to see what – if any – boundaries exist.
Greenfield development PRs are anything and everything: architectural, shared libraries, feature work, infrastructure-as-code, etc. The feature work is often temporary because supporting work still needs to be completed.
Where’s The Beef Context?
The biggest disadvantage of pull requests is understanding the context of the change, technical or business context: you see what has changed without necessarily explaining why the change occurred.
Almost universally, engineers review pull requests in the browser and do their best to understand what’s happening, relying on their understanding of tech stack, architecture, business domains, etc. While some have the background necessary to mentally grasp the overall impact of the change, for others, it’s guesswork, assumptions, and leaps of faith….which only gets worse as the complexity and size of the pull request increases.
[Recently a friend said he reviewed all pull requests in his IDE, greatly surprising me: first I’ve heard of such diligence. While noble, that thoroughness becomes a substantial time commitment unless that’s your primary responsibility. Only when absolutely necessary do I do this. Not sure how he pulls it off!]
Other than those good samaritans, mostly what you’re doing is static code analysis: within the change in front of you, what has changed, and does it make sense? You can look for similar changes (missing or there), emerging patterns that might drive refactoring, best practices, or others doing similar. The more you know about the domain, the more value you can add; however, in the end, it’s often difficult to understand the end-to-end impact.
Process Improvement
As I don’t envision a return of in-person code reviews, let’s discuss how the overall pull request process can be reviewed:
- Goals: Aside from working on functional code, what is the team’s goal for the pull request? Standards adherence? Consistency? Reusability? Resource optimization? Scalability? Be explicit on what is important and what is a trifle.
- Automation: Anything automated reduces reviewers’ overall responsibilities. Static code analysis (i.e., Sonar, PMD) and security checking (i.e., Synk, Mend) are obvious, but may also include formatting code, applying organization conventions, or approving new dependencies. If possible, the automation is completed prior to engineers being asked for their review.
- Documentation: Provide an explanation – any explanation – of what’s happening: at times, even the most obvious seems to need minor clarifications. Code or pull request comments are ideal as they’re easily found: don’t expect a future maintainer to dissect the JIRA description and reverse-engineer (assuming today it’s even valid). List external dependencies and impacts. Unit and API tests also assist. Helpful clarifications, not extensive line-by-line explanations.
- Design Docs: The more fundamental or impactful the changes are, the more difficult – and necessary – to get a common understanding across engineers. Not implying full-bore UML modeling, but enough to convey meaning: state diagrams, basic data modeling, flow charts, tech stacks, etc.
- Scheduled: Context-switching between your work and pull requests kills productivity. An alternative is for you or the team to designate time specifically to review pull requests with no review expectations at other times: you may but are not obligated.
Other Pull Request Challenges
- Tightly Coupled: Also known as the left hand doesn’t know what the right hand is doing. The work encompasses changes in different areas, such as the database team defining a new collection and another team creating the microservice using it. If the collection access changes and the database team is not informed, the indexes to efficiently identify the documents may not be created.
- All-encompassing: A single pull request contains code changes for different work streams, resulting in dozens or even hundreds of files needing review. Confusing, overwhelming reviewers try but eventually throw up their hands in defeat in the face of overwhelming odds.
- Emergency: Whether actual or perceived, the author wants immediate, emergency approval to push the change through, leaving no time for opinions or problem clarification and its solution (correct or otherwise). No questions asked if leadership screams loud enough, guaranteed to deal with the downstream fall-out.
Conclusions
The reality is that many organizations have their software engineers geographically dispersed across different time zones, so it’s inevitable that code reviews and pull requests are asynchronous: it’s logistically impossible to get everyone together in the same (virtual) room at the same time. That said, the asynchronous nature of pull requests introduces different challenges that organizations struggle with, and the risk is that code reviews devolve into a checklist, no-op that just happens because someone said so.
Organizations should constantly be looking to improve the process, to make it a value-add that improves the overall quality of their product without becoming bureaucratic overhead that everyone complains about. However, my experiences have shown that pull requests can introduce quality problems and tech debt without anyone realizing it until it’s too late.
Published at DZone with permission of Scott Sosna. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments