Pure Bliss With Pure Functions in Java
This deep dive into pure functions and collaborative development will help you see how object-oriented and functional programming can work together in Java.
Join the DZone community and get the full member experience.
Join For FreeWriting software is hard.
Writing good software is harder.
Writing good, simple software is the hardest.
Writing good, simple software as a team is the hardest… est.
You shouldn't need several hours to understand what a method, class, or package does. If you need a lot of mental effort to even start programming, you will run out of energy before you can produce quality. Reduce the cognitive load of your code and you will reduce its amount of bugs.
“This is puristic nonsense!” you say. “Intellectual masturbation! Software should be modeled after real-world, mutable objects!”
I'm not saying you should go on a vision quest and return as a hardcore functional programmer. That wouldn't be very productive. Functional and object-oriented programming can complement each other greatly.
I will show you how.
But first, let's get to the what and why of it.
What?
A pure function is a function that:
- …always returns the same result, given the same input.
- …does not have any side effects.
Put simply: When calling a pure function with input A, it always returns B, no matter how often, when and where you call it. Also, it does nothing else.

In Java, a pure function might look like this:
public static int sum(int a, int b) {
return a + b;
}If a is 2 and b is 3, the result is always5, no matter how often or how fast you call it, even if done so concurrently.
As a counterexample, this would be an impure function:
public static int sum(int a, int b) {
return new Random().nextInt() + a + b;
}Its output could be anything, no matter the input. It violates the first rule. If this would be part of a program, the program would become nigh impossible to reason about.

An example of the second rule, a function that has side effects:
public static int sum(int a, int b) {
writeSomethingToFile();
return a + b;
}Even though this method is static and always returns the same value, it is impure. It does more than it advertises. Even worse, it does so secretly.

These examples may look simple and harmless. But impurity adds up quickly.
Why?
Let's say you have a decent-sized program you want to add a new feature to. Before you can do so, you'll have to know what it does. You will probably start by looking at the code, reading documentation, following method calls, et cetera.
While you are doing this, you are creating a mental model of the program. You are trying to fit every possible flow of the data inside your mind. A human brain is not optimised for this task. After a few state changes here, some conditionals there, you start to get somewhat foggy.

Now we have a breeding ground for bugs.
So how can we prevent this? By reducing the complexity of our program, for starters. Pure functions can be of great help here.
How?
A great way to clarify complex code is breaking it up into smaller, more manageable pieces. Ideally, every bit has its own responsibility. This makes them easier to reason about, especially if we can test them in isolation.
While untangling the spaghetti, you will notice you are now able to free up some of your intellectual capabilities. You are slowly getting at the core of the problem. Every piece that can stand on its own can be moved and you are left with the essence of your program.
Finding that bug is much easier now. So is adding a cool new feature. To make things more concrete, here are some guidelines.
Partition
Firstly, partition the bigger pieces by their functionality. Think about the various parts of the solution and how they interconnect.

Break Up
Break up those parts into composable units. Define a function that can be used to filter items from a list, or an action that can be re-used for every single item. Maybe add helper functions that encapsulate logic that would otherwise end up inside deeply nested code.

Document
Write documentation when you feel you are ‘done’ implementing a unit. This will help you see the logic from a different perspective and reveals unforeseen edge cases. If necessary, add unit tests to further define the program's intents.

Rinse and repeat.
The definition of done is personal and can change over time. Don't overdo it. If it's still not clear enough, you will find out later. If not during a code review, maybe when adding a new feature to the project.
So far, so good, right? Theory always sounds great. But we need some convincing in the form of a practical example.
An Example
Let's say we have a client that sells IoT devices. Customers can install these devices in their home and connect them to the internet. They can control these devices with an app on their mobile phone.
Our client wants their customers to receive a push notification if their device has been offline for a while, so they have a chance to reconnect the device. If it stays offline, they want to push notifications periodically, to remind the customer to reconnect the device. But not too often, since they don't want unstable devices to cause an endless stream of warnings.
Also, our customer wants to be able to adjust the thresholds for sending these messages. At runtime, without having to pay us to do it for them. There should be at least one threshold, but there could be any number of them.
Using our backend software, we can detect the online status of these IoT devices. If they go offline, we store the moment they went offline.
Naive Implementation
How can we implement this? This feature looks quite simple on paper, so we could just start and see how far we'd get.
After doing some scaffolding we quickly get to the core of the problem: determining whether notifications should be sent for each offline device. Sounds simple, right?
public void run() {
// @todo Send notifications for offline devices
}We add some for loops here.
for (Map.Entry<Device, Instant> offlineDevice : offlineDevices.entrySet()) {
for (Duration threshold : thresholds) {
// ...
}
}Some if statements there.
if (firstThresholdWasPassed) {
// ...
}Looking good!
Wait, there's a special case for the last threshold.
if (i == thresholds.size()) {
// ...
}Oh, and one for a single threshold.
if (thresholds.size() == 1) {
// ...
}Crap, we forgot to check if the notification for each threshold was already sent. In 3 places.
if (!lastOfflineNotificationInstant.isPresent()) {
// ...
}And what if it was sent before the device went offline?
if (Duration.between(disconnectInstant, lastOfflineNotificationInstant.get()).isNegative()) {
// ...
}SonarLint is foaming at the mouth, telling us to reduce the cognitive complexity of 69, where 15 is allowed. The unit tests are getting quite complex as well, having to use an external Clock an whatnot.
We cannot let our future selves see this, they'd kill us!
Luckily, we have our three-step program. Let's begin at 1.
Partitioning by Functionality
Now, to untangle this mess. Our first step is to partition the bigger pieces by functionality, to think about the various parts of the solution and how they interconnect.
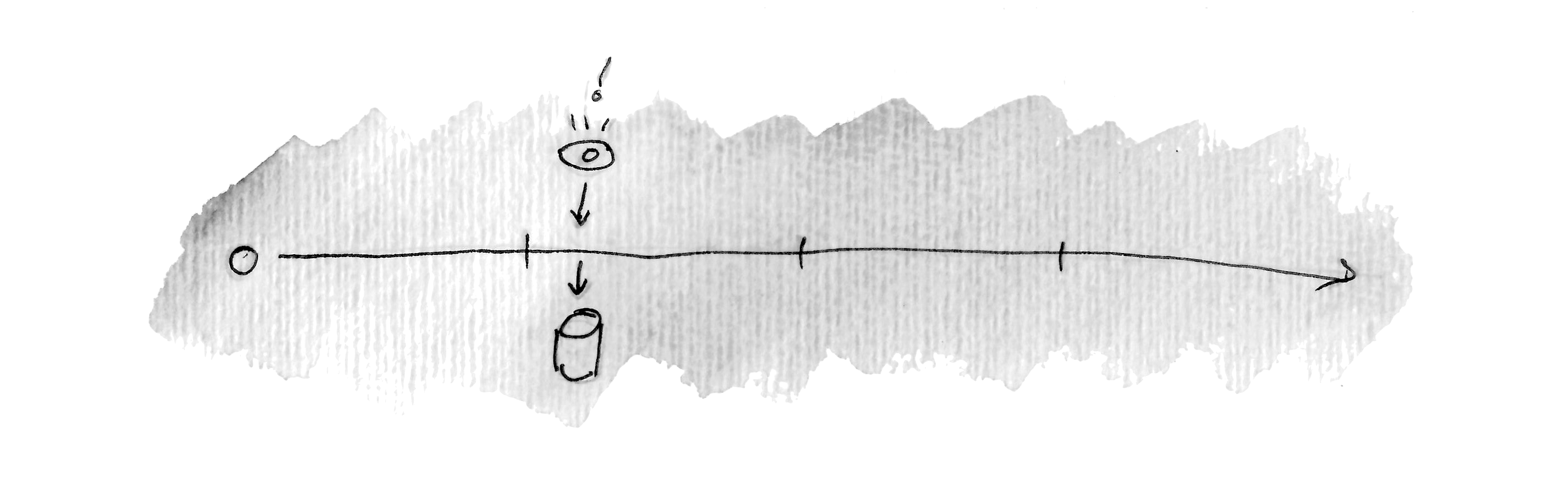
We could visualize our problem by drawing a timeline, starting at the instant a device went offline:
 On the timeline we can plot the various thresholds:
On the timeline we can plot the various thresholds:

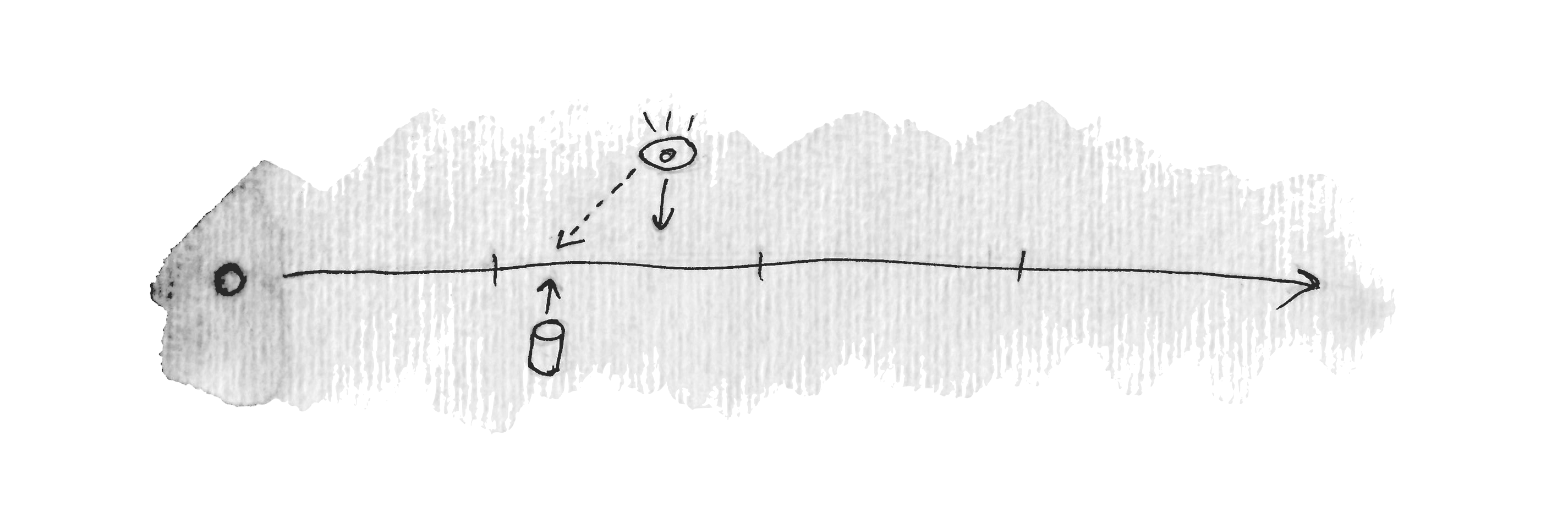
Every time our job is running, we have arrived at a certain point on the timeline. If we have not yet passed a threshold, nothing needs to be done:

If we do pass a threshold, we should send a notification and remember the time we sent it:
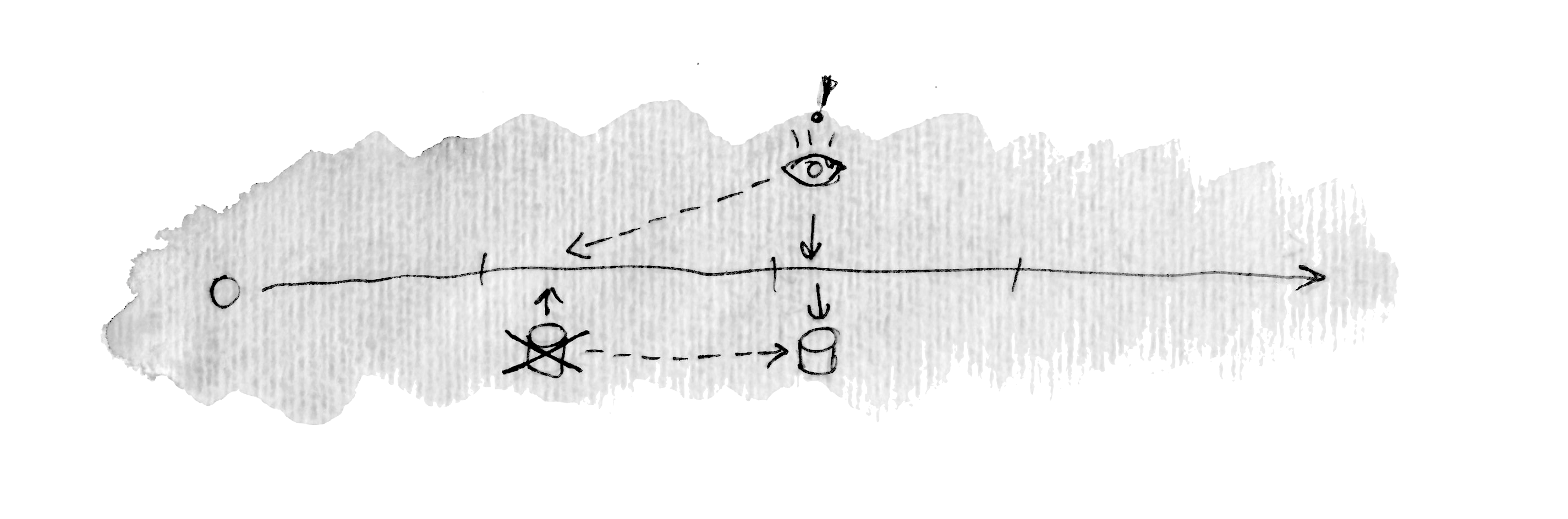
Next time we run our job, we should take the sent notification into account. If we have passed a threshold that the user was already notified about, we do nothing:
Only when passing another threshold, we can send another notification:
And so on and so forth.
How do we express this in code? It seems we need to know:
- Which threshold (if any) we passed last.
- Which threshold (if any) we sent the last notification for.
That's it, basically. If we know these, we can determine if we should send a notification. All the special cases and complexity are captured by these two core parts of our solution.
Now we need to see if we can simplify our solution any further by breaking it up into composable parts.
Breaking It Up Into Composable Units
The two above statements look awfully familiar, no? That's because they are. They both define a threshold or nothing. They both need similar input:
- The moment the device went offline.
- The threshold(s).
- The point in time we are currently evaluating.
Now that we know the input and output of our unit, we can define its signature. Using the fancy java.time API, we can express it as such:
Optional calculateLastPassedThreshold(Instant start, Instant current, Duration[] thresholds);We can now use this function to get both thresholds we needed. Did I say function? Let's make that a pure function: declare it static and make sure it's deterministic and doesn't create any side effects:
static Optional<Duration> calculateLastPassedThreshold(Instant start, Instant current, List<Duration> thresholds) {
Duration timePassed = Duration.between(start, current);
if (timePassed.compareTo(thresholds.get(0)) <= 0) {
return Optional.empty();
}
for (int i = 0; i < thresholds.size(); i++) {
if (timePassed.compareTo(thresholds.get(i)) <= 0) {
return Optional.of(thresholds.get(i - 1));
}
}
return Optional.of(thresholds.get(thresholds.size() - 1));
}There! Aside from its breathtaking purity, it has another pro: It can be unit tested very easily. You don't need mocks nor external clocks to test this part of the code.
Can you feel the amount of space your brain just regained? When programming the rest of our solution, we can just trust that this function will do what it says.
So what's left?
We can now determine, for each device, if we should send a notification. Again, we can isolate this part of our program, make it pure and test it thoroughly:
static boolean shouldSendNotification(Instant jobStart, Instant deviceOffline, Instant lastNotification, List<Duration> thresholds) {
Optional<Duration> lastPassedThreshold = calculateLastPassedThreshold(deviceOffline, jobStart, thresholds);
if (!lastPassedThreshold.isPresent()) {
return false;
}
if (lastNotification.isBefore(deviceOffline)) {
return true;
}
Optional<Duration> lastPassedThresholdNotifiedAbout = calculateLastPassedThreshold(deviceOffline, lastNotification, thresholds);
return !lastPassedThreshold.equals(lastPassedThresholdNotifiedAbout);
}Or, more concisely:
static boolean shouldSendNotification(Instant jobStart, Instant deviceOffline, Instant lastNotification, List<Duration> thresholds) {
Optional<Duration> lastPassedThreshold = calculateLastPassedThreshold(deviceOffline, jobStart, thresholds);
return lastPassedThreshold.isPresent() && (lastNotification.isBefore(deviceOffline) || !lastPassedThreshold.equals(calculateLastPassedThreshold(deviceOffline, lastNotification, thresholds)));
}And when you know the device has no previously sent notifications, you can just use:
static boolean shouldSendNotification(Instant jobStart, Instant deviceOffline, List<Duration> thresholds) {
return calculateLastPassedThreshold(deviceOffline, jobStart, thresholds).isPresent();
}Now the only thing left is calling these functions for every offline device, every time our job runs:
public void run() {
Instant jobStart = Instant.now();
offlineDevices.entrySet().stream()
.filter(offlineDevice -> pushNotificationService
.getLastOfflineNotificationInstant(offlineDevice.getKey())
.map(instant -> shouldSendNotification(jobStart, offlineDevice.getValue(), instant, thresholds))
.orElseGet(() -> shouldSendNotification(jobStart, offlineDevice.getValue(), thresholds))
)
.forEach(offlineDevice -> pushNotificationService.sendOfflineNotification(offlineDevice.getKey()));
}We're bordering on iamverysmart-territory here. Not everyone likes this style of coding and it is arguably harder to parse than a more traditional style. So the least we can do is document our units.
Documenting Our Solution
Aside from playing nice with others, describing our code can also help us catch that last bug, or reveal an edge case we hadn't thought of yet.
Documentation in our case most obviously comes in the form of Javadoc, for example:
/**
* Checks whether a notification should be sent by determining which threshold has been passed last for the
* calculated amount of time passed between the device going offline and the job running.
*
* @param jobStart The instant the job calling this function was started.
* @param deviceOffline The instant the device went offline.
* @param lastNotification The instant the last notification was sent.
* @param thresholds The list of notification thresholds.
* @return True if the notification should be sent, false if not.
*/
static boolean shouldSendNotification(Instant jobStart, Instant deviceOffline, Instant lastNotification, List<Duration> thresholds) {
// ...
}
Unit tests can also be regarded as documentation since they can define the intended use of the program under test very precisely. In the case of pure functions, where you often need to test a list of varying input, parameterized tests can come in handy.
While writing tests and documentation, we shift our thinking from the problem to the solution, and its users. By thinking from this other perspective, subtle problems in our code are highlighted and can be fixed on the spot.
Afterthoughts
It can be hard to convince others or even yourself of the value of this approach. Churning out functionality has more obvious business value than meticulously crafting software.
When approaching existing code this way, you can end up wasting hours while adding no measurable (short-term) value. Try explaining that during the daily stand-up.
On the other hand, preventing a bug is cheaper than fixing it, and the more clean your code is, the less time it takes to add a feature or find an error, especially if the code hasn't been touched in a while.
Somewhere along the line, the balance is tipped. On one side lies the holy grail, the unachievable perfect piece of software. On the other side, the unmaintainable spaghetti monster slithers, shitting on deadlines, ballooning budgets and destroying teams.
Listen to your instincts, communicate your intentions, listen to your peers and learn from one another: making great software is an ongoing (team) effort.
Source code
All code referenced in this post is open source and can be found in its GitHub repository. Feel free to check it out, tinker with it and come up with better solutions.
Feedback
I'd love to hear your feedback in the form of pull requests, issues, or comments! There are some nice discussions going on over here:
Or you can post your comments below.
Published at DZone with permission of Piet van Dongen. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments