Why Push-Based Systems Fail at Scale — and How Hybrid Fan-Out Fixes It
Push-based systems work until celebrity-scale traffic creates massive fan-out pressure. Modern platforms solve this using hybrid architectures.
Join the DZone community and get the full member experience.
Join For FreeReal-time systems look simple on architecture diagrams. A user posts content, the backend publishes an event, and connected users instantly receive notifications through persistent WebSocket connections. At small scale, the model works beautifully. At large scale, it becomes one of the fastest ways to melt distributed infrastructure.
Most push-based architectures fail for one reason: they assume traffic is evenly distributed. Production traffic never is. One user may have 50 followers. Another may have 10 million. Designing both scenarios using the same fan-out strategy creates massive operational problems during peak traffic. That is why large-scale platforms evolved from naive push delivery into hybrid push/pull systems optimized around uneven load distribution.
The Naive Push Architecture
The first design most engineers create is straightforward:
- A user publishes a post
- The backend sends the event to a broker
- WebSocket servers receive the event
- Notifications are pushed to all connected followers
On paper, the architecture looks clean.
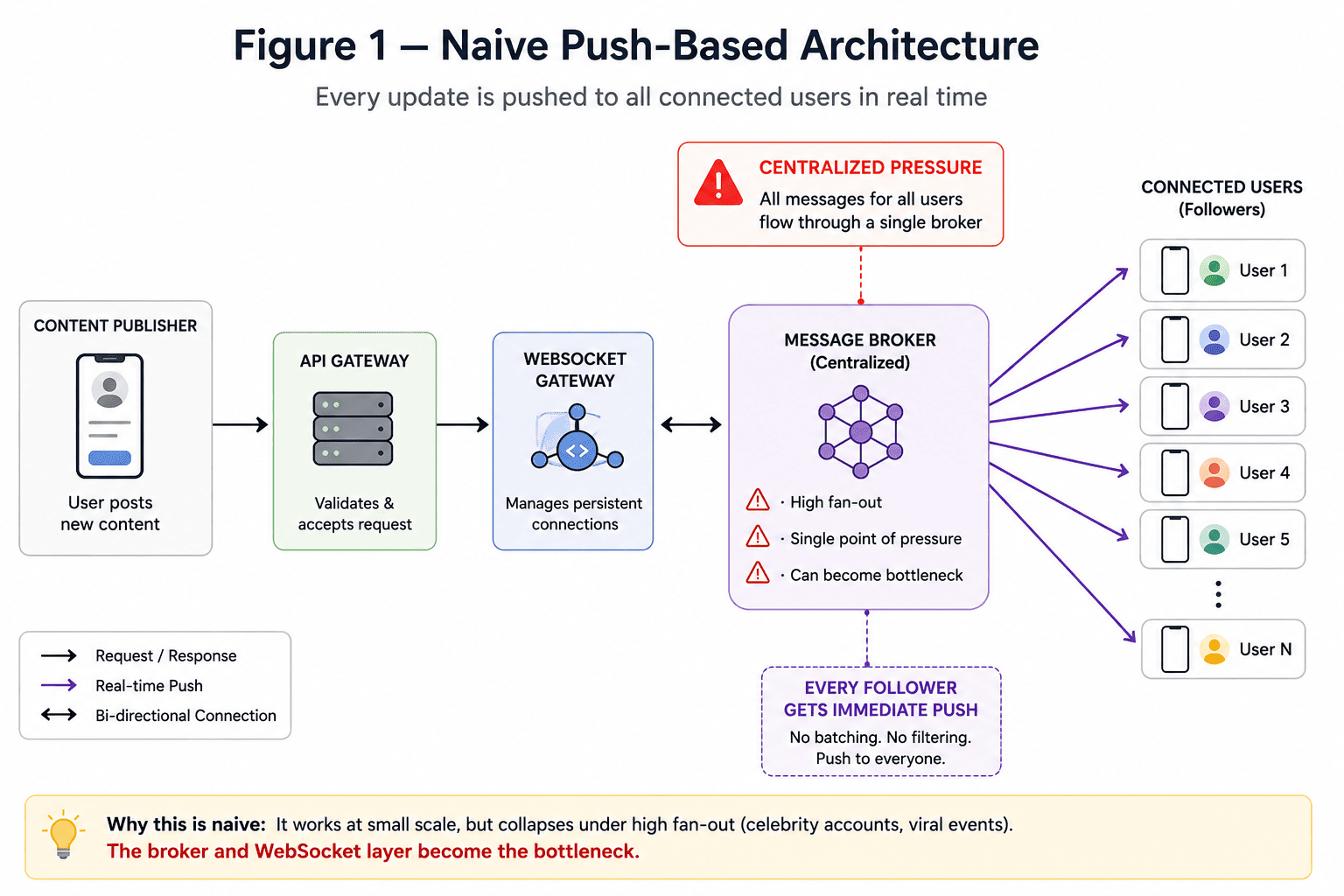
The system appears scalable because:
- WebSockets provide real-time delivery
- Brokers decouple services
- Horizontal scaling seems possible
But hidden underneath the simplicity is a dangerous scaling assumption:
every user generates similar traffic patterns. That assumption collapses the moment a celebrity account posts.
The Celebrity Fan-Out Problem
Imagine a user with 10 million followers posting a new update.
The system now attempts to:
- Generate millions of delivery events,
- Route them through brokers,
- Maintain millions of active socket writes,
- Deliver updates almost simultaneously.
The bottleneck is no longer application logic. The bottleneck becomes:
- Broker throughput
- Connection management
- Queue depth
- Network bandwidth
- Retry amplification
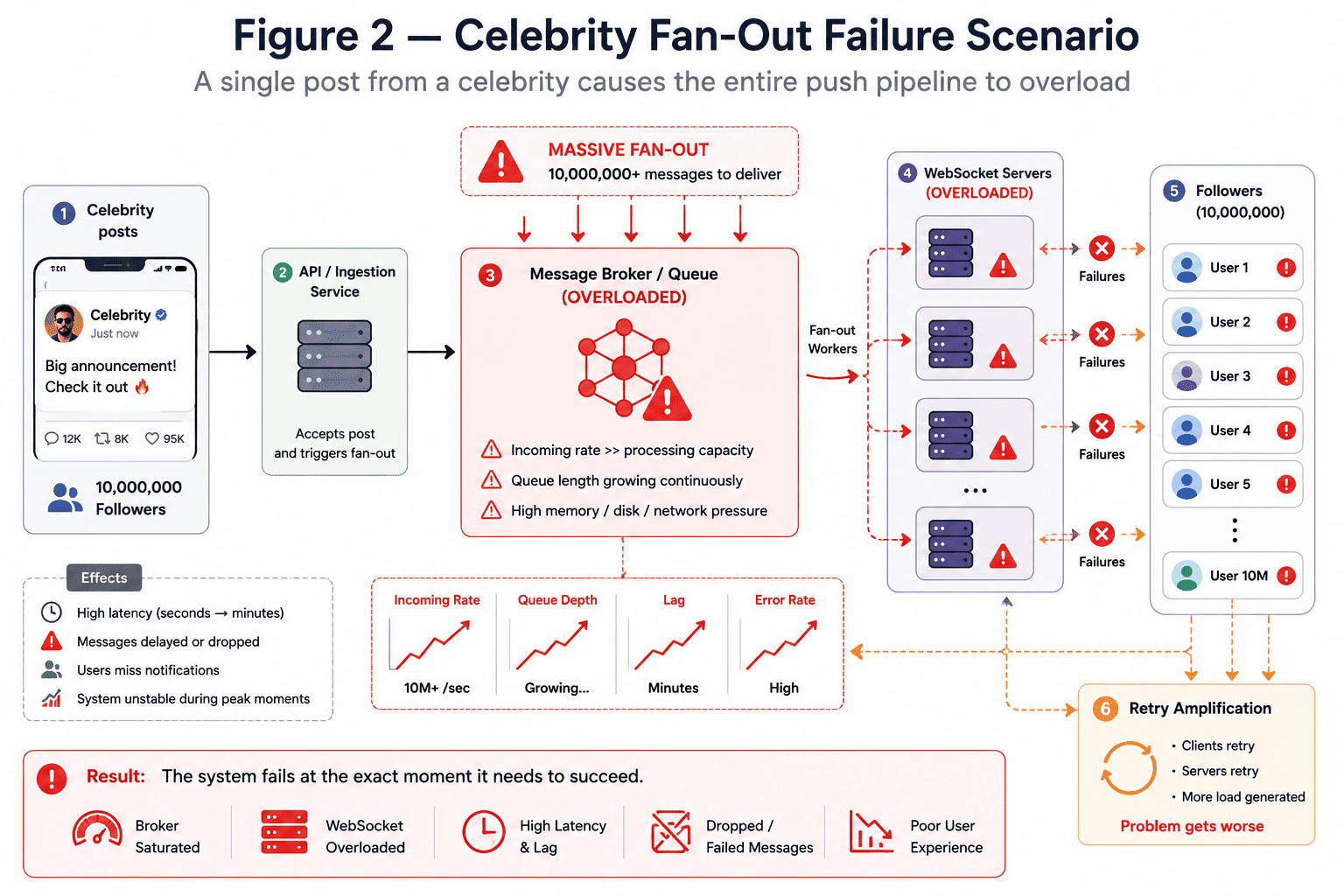
This is where many real-time systems fail in production. As delivery pressure increases:
- Queues begin backing up
- Consumers lag behind
- WebSocket nodes become saturated
- Latency grows from milliseconds into seconds or minutes
Then retries begin. Clients retry because acknowledgments are delayed. Servers retry because deliveries fail. Load balancers redistribute unstable traffic. The system begins amplifying the overload condition itself.
This behavior is common in distributed systems:
Reliability mechanisms designed to recover from failure end up accelerating collapse under overload.
The architecture appears stable during normal traffic. It fails at the exact moment traffic matters most.
Why Pure Push Architectures Break
The real issue is fan-out-on-write. Every post immediately creates work proportional to follower count. For small accounts, this is inexpensive. For celebrity-scale accounts, a single write operation generates massive downstream pressure:
- Enormous queue pressure
- High-volume socket delivery
- Enormous broker traffic
The system becomes optimized around worst-case fan-out instead of average workload. That is operationally expensive and difficult to stabilize. This is why most large-scale feed systems avoid pure push delivery for all users.
The Hybrid Push/Pull Model
Modern systems solve the problem differently. Instead of treating every account identically, they dynamically switch between:
- Push-on-write
- Pull-on-read
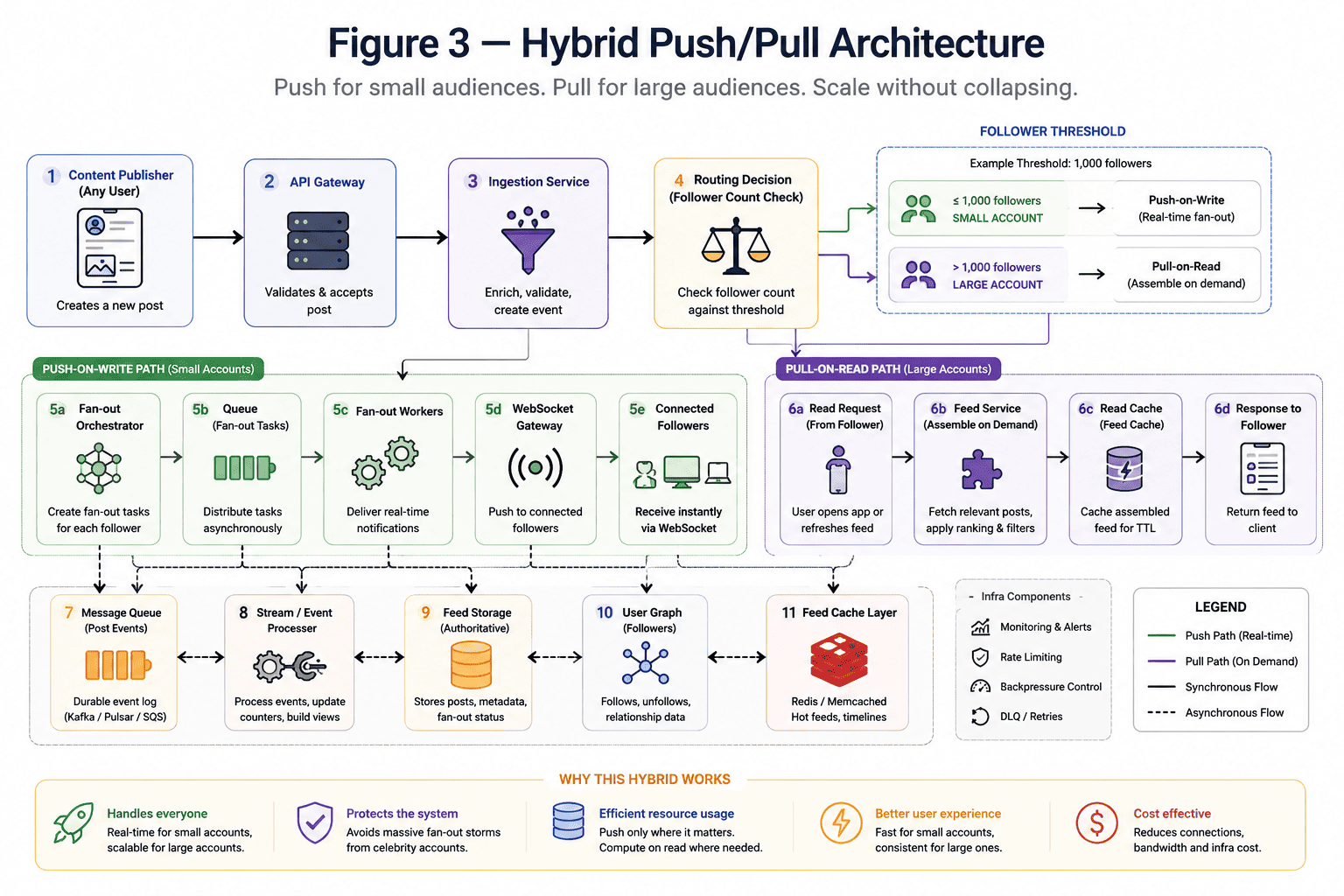
The decision is usually based on follower thresholds.
Push-on-Write for Small Accounts
For smaller accounts:
- Updates are immediately pushed,
- Queue workers fan out notifications,
- Followers receive low-latency real-time updates.
This keeps the user experience fast while infrastructure costs remain manageable.
Pull-on-Read for Large Accounts
For celebrity-scale accounts:
- Posts are stored normally
- Fan-out is avoided
- Feeds are assembled when users open the app
Instead of generating millions of writes immediately, the workload shifts to read time. This dramatically reduces broker pressure and prevents large fan-out storms from destabilizing the platform. Twitter/X publicly discussed similar strategies years ago because global push fan-out becomes prohibitively expensive at scale.
The important engineering insight is:
Push and pull are not competing architectures.
They are complementary scaling strategies selected dynamically based on traffic patterns.
Feed Assembly Introduces New Complexity
Once systems adopt pull-on-read, another problem appears: feed assembly. Now the platform must dynamically build personalized feeds using:
- Follower relationships
- Ranking algorithms
- Muted users
- Blocked accounts
- Recent activity
- Recommendation signals
This shifts complexity from writes to reads. To reduce repeated database work, systems commonly introduce:
- Redis timeline caches
- Materialized feed views
- Asynchronous feed builders
- Hot-feed caching layers
The challenge becomes balancing:
- Freshness
- Latency
- Consistency
- Infrastructure cost
- Cache invalidation
The architecture is no longer just “real-time delivery.” It becomes distributed workload management.
WebSockets Make Infrastructure Stateful
Many system design discussions stop once WebSockets are introduced. Production systems become significantly harder after that point. WebSockets create stateful infrastructure.
Now the platform must know:
- Which user is connected
- Which server owns the connection
- How to recover missed events after reconnects
This changes routing behavior completely. Requests can no longer be routed blindly across stateless servers. Most systems introduce:
- Sticky sessions,
- Session affinity,
- Distributed connection registries,
- Redis pub/sub coordination.
Then mobile networks create another challenge: temporary disconnects. A user loses connectivity for three seconds. What happened during that gap? Without replay recovery, notifications disappear permanently.
Replay Buffers and Recovery Logic
Reliable real-time systems usually implement:
- Sequence IDs
- Replay buffers
- Reconnect checkpoints
- Gap recovery logic
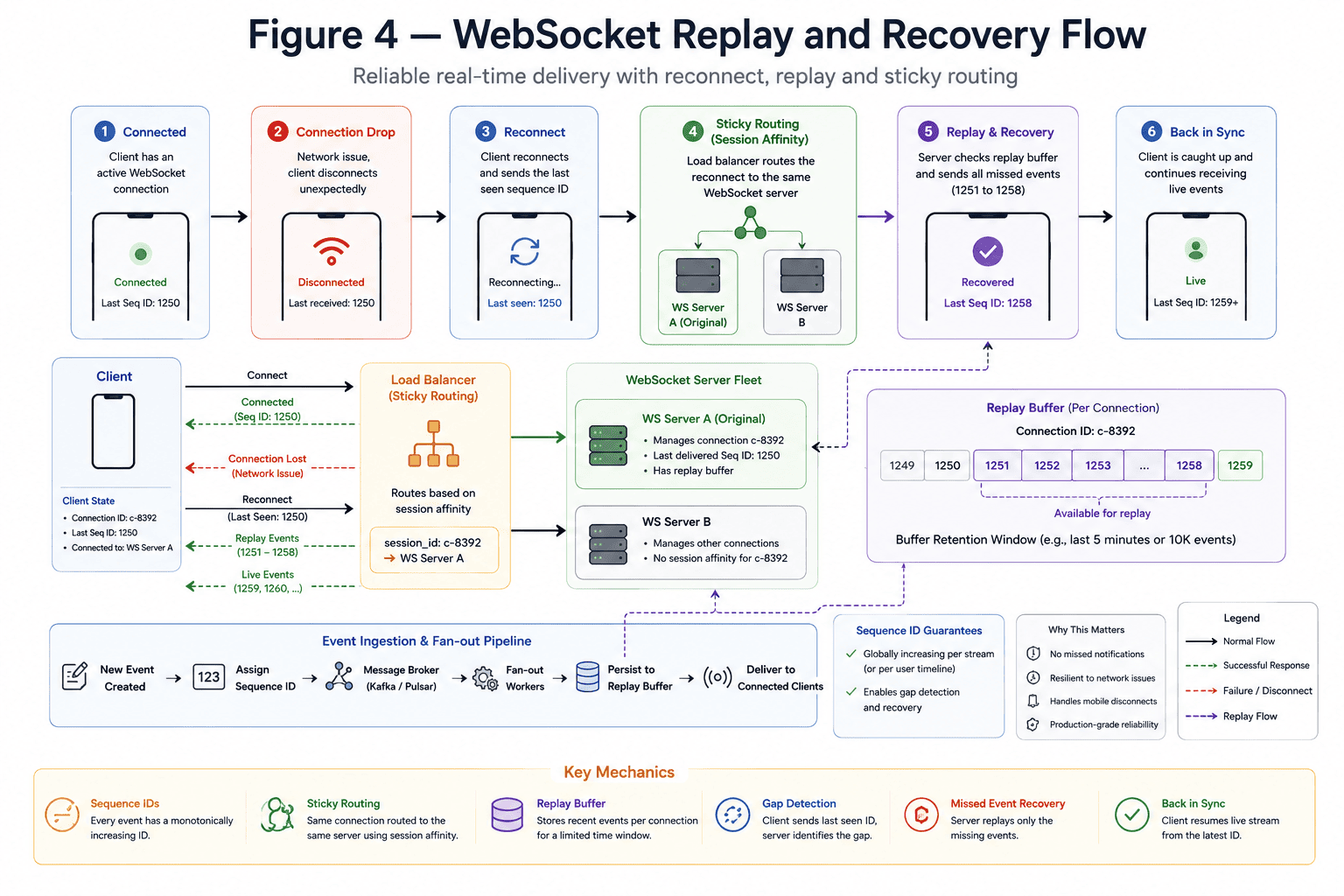
When the client reconnects:
- It sends the last processed sequence ID
- The server identifies missing events
- Replay buffers resend missed messages
- Live streaming resumes
This is where systems move beyond interview-level architecture. The challenge is no longer simply delivering events. The challenge is maintaining continuity during instability. Real-world distributed systems spend enormous engineering effort handling:
- Partial failures
- Reconnect storms
- Duplicate delivery
- Inconsistent network conditions
Operational Tradeoffs Teams Often Underestimate
One of the biggest mistakes in real-time architectures is optimizing only for delivery speed while ignoring operational cost.
Push-heavy systems keep large numbers of persistent connections open simultaneously. At global scale, this introduces pressure across multiple infrastructure layers:
- Connection memory usage
- Broker throughput
- Network egress
- Heartbeat traffic
- Reconnect storms during outages
Even healthy systems can become unstable during regional network disruptions.
For example, if thousands of mobile clients reconnect at the same time after a temporary outage, WebSocket gateways may suddenly experience authentication spikes, replay requests, and connection churn simultaneously. This often creates secondary overload events long after the original incident is resolved.
This is why mature systems introduce additional controls such as:
- Connection rate limiting
- Replay window expiration
- Backpressure handling
- Circuit breakers
- Adaptive retry strategies
Another overlooked problem is message ordering.
In distributed fan-out systems, messages may arrive out of order because events are processed asynchronously across multiple workers or partitions. Without sequence tracking, users may briefly see inconsistent timelines or duplicate notifications.
Production-grade systems therefore prioritize the following instead of assuming perfect real-time synchronization:
- Idempotent delivery,
- Sequence-aware replay,
- Eventual consistency handling
The engineering challenge is not simply pushing events quickly. The challenge is maintaining stability while millions of users interact with the platform under unpredictable traffic conditions.
Final Thoughts
Most distributed systems look elegant until traffic becomes uneven.
That is the hidden reality behind large-scale architecture. The difficult part is not handling average load. The difficult part is surviving pathological load without collapsing the platform.
Real systems evolve through operational pain:
- Broker saturation
- Retry storms
- Replay failures
- Queue buildup
- Cascading latency amplification
The best architectures are rarely the simplest ones. They are the ones that continue functioning when the system is under maximum stress.
In distributed systems, every design is ultimately a negotiation between:
- Latency
- Throughput
- Durability
- Availability
- Cost
Those forces shape every scalable platform on the internet.
The systems that survive at scale are not the ones with the cleanest diagrams. They are the ones designed to absorb failure without collapsing under pressure.
References
- Apache Kafka Documentation
- Redis Pub/Sub Documentation
- WebSocket Protocol RFC 6455
- Twitter Scalability Architecture Discussion
- Designing Data-Intensive Applications by Martin Kleppmann
- Google SRE Book — Handling Overload
Opinions expressed by DZone contributors are their own.
Comments