Queuing Theory for Evaluating System Performance in Event Driven Architecture
Learn about the fundamentals of Event Driven Architecture will explain queueing theory and how you can use it to evaluate system performance.
Join the DZone community and get the full member experience.
Join For FreeEvent Driven Architecture (EDA) is gaining a lot of popularity due to the benefits it offers to an enterprise to easily connect multiple disparate systems. Instead of creating a direct or point-to-point communication links between the systems that need to talk to each other, the communication process can be decoupled by having the systems interact by passing the events in a format that is programming language neutral (XML, JSON or delimited text).
Service Oriented Architecture (SOA) has been widely adopted by the enterprises having loosely coupled services that interact with each other over an agreed protocol (SOAP, REST) to offer different business capabilities. EDA is not a replacement for SOA, rather it complements the existing SOA infrastructure by providing a means by which a system can interact asynchronously without the knowledge of other systems in an enterprise.
Building Blocks of Event Driven Architecture
Events
An event can be defined as a user or a system driven action that is captured by the system to signify an important interaction with a customer, an opportunity, error conditions or a deviation in the service or threshold. The event may result in the invocation of other services or business processes based on the event outcome to offer value-added services to the customer, enhance customer experience, cross-sell or avoid bad customer experience due to system errors. It is a good practice to standardize the event payload structure by having an event specification followed throughout the organization. All the events generated should have an event header and event body. Event header provides a context for the event i.e. the type of event, event generation time, the source of the event, and message properties to enable the filtering of the events. Event body contains the event data that should conform to the schema definition.
Event Processors and Publishers
Generally, the events generated by the system are in a Raw format which might not be of much use to the other systems in an enterprise. The Raw events might need to be enriched with additional customer or product information before they can be consumed by the other services or systems. Also, the raw event needs to be converted to an enterprise standard event definition for consistency and easy consumption by multiple subscribers.
Simple Event Processors can be developed in-house by the application teams supporting the system that generates the events, however, there are scenarios where Complex Event Processors (CEP) might be needed. CEPs are specialized event processing product offered by various vendors (TIBCO, Oracle, SAP) that helps in aggregating and correlating multiple events from different systems to derive new events which otherwise could be challenging with the custom-built simple event processors. As an example, the customer might prematurely close a CD account held with a bank by withdrawing the money by official check. Since this customer action is an early withdrawal from a CD account, the bank might charge early withdrawal fees to the customer. Here a single action of closing the CD account by the customer generates a raw event for account closure which then could be processed by the event processors to generate multiple events (derived events) for account closure, an official check issued, and/or early withdrawal fees.
Core Messaging Infrastructure
Once the raw event has been processed, enriched and transformed to an enterprise standard event, the event needs to be published to a Topic provided by the messaging infrastructure. There are many options available for building the enterprise-wide messaging infrastructure (a.k.a. Message Bus or Event Bus) by using WebsphereMQ, ActiveMQ, RabbitMQ or Kafka. Kafka is a highly scalable and distributed messaging system gaining lot of popularity among enterprises for Message Oriented Middleware (MOM) infrastructure.
Event Subscribers
Once the event is published to a specific Topic on the Message/Event Bus, all the subscribers that have subscribed to the Topic will get the events and then take further action – call other services or generate additional events after applying some business rules.
System Performance
It is important to decouple the event generation and event processing from the customer-facing business processes to avoid any delay in the response time due to the additional processing overhead of event handling. One of the ways to avoid this delay in the response time is to asynchronously store the raw events in the event/audit tables and then send them to the message queue or write the raw events directly to a message queue for processing. By putting the raw events in a message queue before the events are processed and published helps in decoupling the business process generating the events and the actual processing of the events, however, this adds the complexity to the overall architecture. There could be a delay in the event processing and publishing if the rate at which the raw events are generated is higher than the rate at which the events are processed and published by event processors. There could be a business requirement to process the events within X seconds and any delay could result in sub-optimal customer experience or even an undesired consequences. As an example, sending the debit card transaction alert to the customer after 5 mins of swiping the card might not be a good customer experience and a delay of 15 mins in alerting the customer can result in a potential fraud costing a significant expense to the bank.
In order to avoid any delays in event processing, it is important to run performance tests to evaluate the system performance under peak load. We can also evaluate the system performance before actually running the performance tests by applying the Queuing theory. This helps in setting up a theoretical benchmark against which we can run the performance tests to evaluate the system performance involving messaging infrastructure.
Queuing Theory
Queuing theory has been widely used in Operations Research to calculate the waiting times and the resources required to service customers in call centers, service patients in hospitals and traffic engineering. It is also used in computer science for analyzing the stacks (a queue storing system state) used for running the processes and resources on the CPU.
Any system that involves a queue inherently introduces a delay in serving the customer e.g. waiting on the line when you call the customer care service of your internet provider, cable or phone service provider and you are asked to wait for X mins before being served. How’s that the service provider is able to provide you an estimated wait time until you get to talk to a customer service agent? How does your bank know how many agents to staff the call center to service customer calls or how many representatives are required at a bank branch to serve the customers stopping by at the branch? Queuing theory helps in answering all these questions i.e. average waiting time for the customers, the number of customer service agents required to service customer and the average number of customers that could be waiting in the queue before they are served.
Queuing Theory principles can also be applied to a system generating and processing the events. The events are messages waiting in a queue to be served (processed) by the event processor application hosted on the server. Following are some of the performance metrics that can be evaluated-
- Average waiting time for the events in the queue
- Average Queue Length or Queue Depth
- Number of event processor instances (server nodes) required to ensure that the delay in event processing is within the acceptable limit
Little’s Theorem
Little’s theorem provides an important mathematical relationship between the customer or event arrival rate (λ) and the customer or event processing times (T) and is expressed as-
N = λT
where
N is the average number of customers or events in the queuing system
λ is the average customer or event arrival rate
T is the average service time for the customer or event processing time
Queuing System Characteristics
We’ll now take a look at some of the important characteristics of the queuing system and how they help in further classifying the queuing system to simplify the analysis as it relates to event processing.
Event Generation or Event Arrival
Events generated by the system that are put on a raw queue for processing are assumed to have an arrival rate λ expressed as the number of events generated per second, minute or hour.
The event arrival follows Poisson Distribution and has an important characteristic of the system being memory-less i.e. the arrival of the next event is independent of the arrival of the current event. The total number of events occurring in a small interval of time is unknown and assumed to be a random variable. The inter-arrival time between the events is also considered to be a random variable i.e. the time before the next event occurs after the current event is generated is unknown. The inter-arrival wait time for the events follows exponential distribution i.e. the probability of the event occurring in a time interval is proportional to the length of the time interval. In other words, once the event has occurred the probability that the next event will occur in 1 second is higher than the probability that the next event will occur in 500 ms.
Event Processing
Events processed by the event processor are assumed to have processing rate of μ expressed as the number of events processed per second, minute or hour.
The time it takes to process the event is also considered to have an exponential distribution.
Number of Servers or Processing Nodes
The number of servers or the processing nodes that are available to process the generated events. When modeling the event processor application hosted on an application server there could be multiple container threads running in parallel to process the events. Hence the total number of servers, in this case, would depend on the number of nodes the application is installed and the maximum number of container threads defined for each node based on the available resources (memory, CPU, and network I/O).
Total number of servers i.e. the processing threads = number of nodes * container threads on each node
Queuing System Classification
Kendall’s Notation
Queuing systems are commonly classified using Kendall’s notation which follows the convention A/S/n.
A – Event arrival process
S – Event service process
n – Number of servers to process the events
In the event processing scenario where the event arrival and event processing has an exponential distribution, the event arrival and event service processes are denoted by “M” i.e. Markov or memory-less. We also assume that there will be multiple servers to process the events in parallel to achieve the required throughput.
Kendall notation for the event processing system can be expressed as M/M/n.
The queuing system can also be further classified based on the finite or infinite queue length. In order to have a finite queue length, it’s important that λ/μ < 1 i.e. the event generation rate or arrival rate is less than the event processing rates. If λ/μ > 1 then the events will gradually start queuing up and theoretically, we would need an infinite queue to prevent any loss of events due to queue getting filled up.
It is undesirable to have a queuing system where λ/μ > 1 as it will require an infinite queue which is practically in-feasible and will also result in unacceptable delays in processing the events. So, if we design a system where event arrival rate is always less than the event processing rate i.e. λ/μ < 1 then the question would be why we need a queue? Even if we have a queue to decouple the event generation and event processing, would the queue length or queue depth always be “Zero” or “One”?
We discussed that the arrival rate for events is average arrival rate and randomly distributed. It could happen that all the events arrive in a small interval of time or may be spread throughout the given time window. Also, the processing time of the events can vary and is randomly distributed. It is very likely that more events arrive in a small time interval than the system can actually process. There could be scenarios where the system generates a large number of events with spikes due to increased activity on the website as a result of an ongoing marketing campaign or batch processes during offline processing. Even if the overall system is designed to have λ/μ < 1, there is a randomness in the system where the event arrival rate could exceed the event processing rate in a small time interval. Hence, it’s important to have a queue to persisted the events temporarily before they are processed by the server.
Simple Event Processor Queuing Model
We’ll analyze a simple event processor queuing model (M/M/n) where λ/μ < 1
We are interested in calculating the following system parameters-
- Length of the System (Ls) – Total count of the average number of events in the queue and the events currently processed by the event processor
- Length of the queue (Lq) – Average number of events in the queue
- Waiting time in the system (Ws) – Total waiting time in the queue and the time it takes for the event to get processed in the event processor
- Waiting time in the queue (Wq) – Waiting time in the queue
Following diagram shows an event processing system having multiple event generators putting the events on the queue which are then processed by event processor application running on multiple nodes.
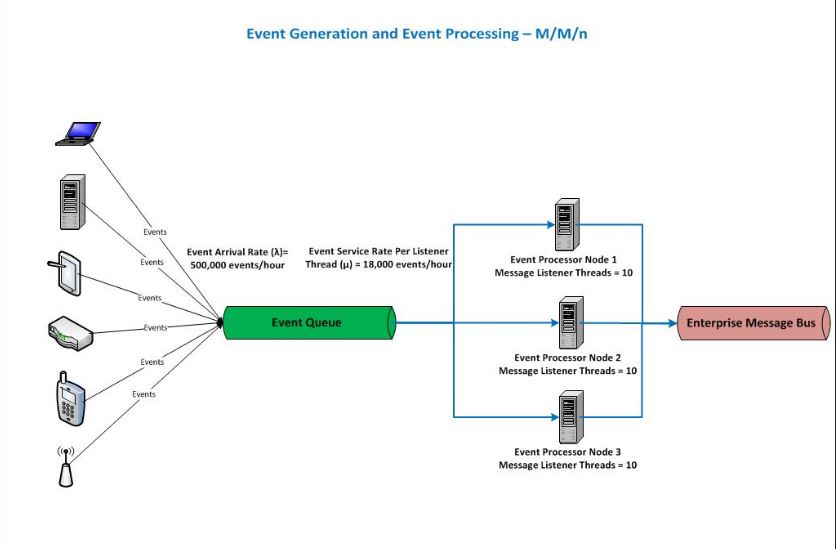
The aggregated average event arrival rate (λ) in this scenario is 500,000 events/hour and the average event processing rate (μ) is 18,000 events/hour for each message listener thread on the server node. We are assuming that the event processor application is installed on 3 nodes and each node has 10 message listener container threads available to poll the events from the event queue.
So, for this M/M/n queuing system we have the following-
λ = 500,000 events/hour
μ = 18,000 events/hour
n = 30
There are calculators available based on the queuing theory that helps in calculating the performance metrics that we discussed in this article. Using the calculator, we can easily arrive at the following results for the above queuing system.
Results
- Total number of events (event queue and event processor) – 35.09 events
- Number of events in the event queue – 7.31 events
- Total event processing time (Time spent in event queue and event processing time) – 0.25 seconds
- Event waiting time in the event queue – 0.05 seconds
It is important to note that there could be various other factors specific to the use case that can impact the system performance. For instance, there could be micro-batching of event streams such that the event processor processes a small batch of events instead of a single event at a time. Queuing theory principles discussed in this article would still apply for evaluating the system performance before running the actual performance tests by taking into account the size of batched events.
To summarize, we discussed how the queuing theory can be applied to event processing required for implementing Event Driven Architecture in an enterprise. By knowing the event arrival rate and event processing rate, we can easily calculate the average event processing time and the average event queue length. Queuing analysis can help in approximate sizing of the infrastructure (Queue capacity, number of server nodes, number of container threads ) even before we run the performance tests. It also provides a theoretical baseline to compare the results of performance test runs. Once the performance tests are run and metrics captured, one can arrive at the real system performance metrics and the right sizing of the infrastructure for the queuing system.
Opinions expressed by DZone contributors are their own.
Comments