Rails Asynchronous Processing
Learn about the implementation of a simple asynchronous processing use case in Rails utilizing a sample application into which I have integrated the code.
Join the DZone community and get the full member experience.
Join For FreeWhen I log into my bank account and want a report of all my account transactions for say, six months or a year, the web application says it received my request and asks me to check later to get the PDF report. After some time, I would be able to download the report. This is an example of asynchronous processing.
In this article, I describe the implementation of a simple asynchronous processing use case in Rails. I have a sample application called "mahrasa," short for Mahboob Rails sample application, into which I have integrated the code.
Use Case
The user uploads a CSV file to the application. She gets a message saying the file is received and is being processed. A link is displayed where the user can check the status. In the backend, the file is processed asynchronously and post-processing the status is updated on the status page.
Design
Rails has many gems that enable asynchronous processing. Some of them are delayed_job, Resque, sidekiq, and delayed.
I went with delayed as it is the newest kid on the block and states advanced features on its repository page, as given below:
Delayedis a multi-threaded, SQL-driven ActiveJob backend used at Betterment to process millions of background jobs per day.It supports postgres, mysql, and sqlite, and is designed to be:
Reliable, with co-transactional job enqueues and guaranteed, at-least-once execution
Scalable, with an optimized pickup query and concurrent job execution
Resilient, with built-in retry mechanisms, exponential back-off, and failed job preservation
Maintainable, with robust instrumentation, continuous monitoring, and priority-based alerting
Why
Delayed?The
delayedgem is a targeted fork of bothdelayed_jobanddelayed_job_active_record, combining them into a single library. It is designed for applications with the kinds of operational needs seen at Betterment, and includes numerous features extracted from Betterment's codebases, such as:
Multithreaded job execution via
concurrent-rubyA highly optimized,
SKIP LOCKED-based pickup query (on postgres)Built-in instrumentation and continuous monitoring via a new
monitorprocessNamed priority ranges, defaulting to
:interactive,:user_visible,:eventual, and:reportingPriority-based alerting thresholds for job age, run time, and attempts
An experimental autoscaling metric, for use by a horizontal autoscaler (we use Kubernetes)
A custom adapter that extends
ActiveJobwithDelayed-specific behaviors
Let me add a disclaimer here that I haven't verified all the claims, so this article is not an endorsement that you should go with delayed in your application.
The installation steps of delayed are pretty simple:
- Add the following to your Gemfile:
gem 'delayed'- Run
bundle install. - Create the table
delayed_jobs.
$ rails generate delayed:migration rails db:migrate- Add the following line to config/application.rb:
config.active_job.queue_adapter = :delayed
Inserting data in PostgreSQL with psql is blazingly fast. However, mahrasa uses SQLite3 database. The equivalent to psql in the case is SQLite3 itself. Before coding the job with SQLite3, I decide to check other data insert methods also, and time them to get an understanding of their relative performance. The options are:
- Insert the data row by row.
- Use csvsql to copy the file into the database.
- Bulk insert the rows using ActiveRecord-import.
- Use SQLite3 to copy the file into the database.
For each option, I wrote an application job, whose details are given below:
ImportGdcJob
This job is the implementation of option 1. It reads the input CSV file in a loop and for each line, it inserts a row in the database calling the create method of the model Gdc.
ImportGdcJob2
This job is the implementation of option 2. csvsql needs a header line with column names. My CSV file does not have a header row. Therefore, this job first creates a temp.csv file with the first line having column names and then appends the entire input CSV file. It then runs the tool csvsql to copy the file into the database. You can install csvsql in a Python toolkit called csvkit.
$ pip install csvkit
ImportGdcJob3
This job is the implementation of option 3. It bulk inserts data with ActiveRecord-import by invoking the input method on the model class Gdc.
ImportGdcJob4
This job is the implementation of option 4. It executes a system statement to run SQLite3 passing it a shell script as input. The shell script creates a temp_table and imports the input CSV file data into it. It then inserts data from the temp_table into global_daily_cumulative. This routing of data via a temp_table takes care of automatic id generation in the primary column, which SQLite3 does not handle.
The procedure for running and testing these jobs is as follows:
- Run the steps, up to Create Table, in the How to Run section.
- In ImportGdcJob4.rb, comment on the line:
AsyncOperation.where(id: job.arguments.first[:id]).update(:status => "processed")- In one terminal, start
rakejobs:
$ rake delayed:work- In another terminal, start the Rails console and call the job's class name.
$ rails c
> ImportGdcJob2.perform_later The following screenshots show the output of running ImportGdcJob2 in Terminal 1 and Terminal 2, respectively.
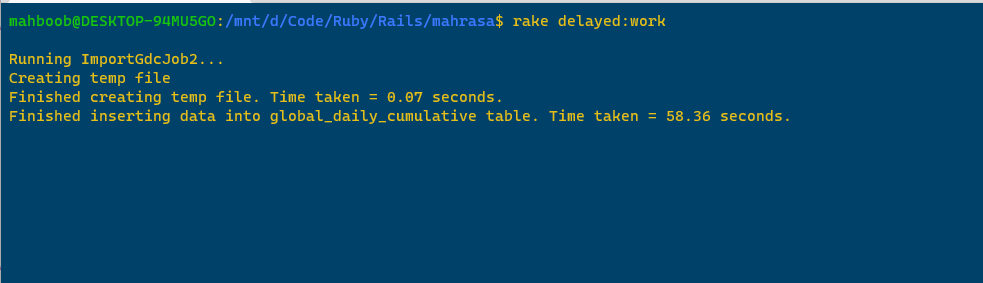
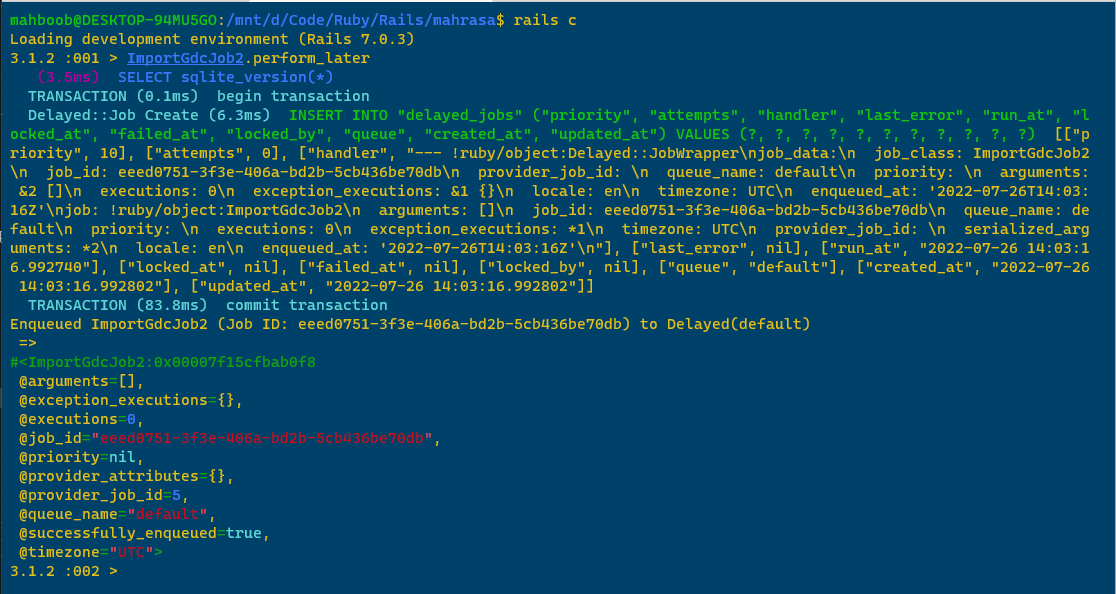
Since ImportGdcJob was a line-by-line insert into the database, I knew it would be awfully slow and so I ran it with only 1,000 rows. The execution times were in the expected order:
| Job | Time (Seconds) |
|---|---|
ImportGdcJob [1000 rows only] |
144.53 |
ImportGdcJob2 |
58.43 |
ImportGdcJob3 |
6.02 |
ImportGdcJob4 |
4.91 |
Integrating Into Rails
Since it is the fastest, the fourth option is the preferred option. The job is called in the controller as an asynchronous operation, as shown in the following code block:
def import
# copy uploaded file app/jobs directory
FileUtils.cp(File.new(params[:csvfile].tempfile),
"#{Rails.root}/app/jobs/global_daily_cumulative.csv")
# insert async_operations row
@filename = params[:csvfile].original_filename
@ao = AsyncOperation.new(:op_type => 'Import CSV',
:filename => @filename,
:status => :enqueued)
# enqueue the job
if @ao.save
ImportGdcJob4.perform_later(id: @ao.id)
end
render :ack
endThe view renders a link to check the status of the data insert job.
How To Run
- Clone my repository:
$ git clone https://github.com/mh-github/mahrasa.git -b delayed1- Go into the project folder:
$ cd mahrasa- Make sure you have Ruby 3.1.2 installed and use it.
$ rvm install 3.1.2
$ rvm use 3.1.2- Install the gems:
$ bundle install- Run the database migrations:
$ bin/rails db:migrate RAILS_ENV=development- Create table: Execute the following command from the SQLite3 prompt or within a database IDE like SQLite Browser or DBeaver.
CREATE TABLE "global_daily_cumulative" ( "id" INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL, "date" TEXT, "place" TEXT, "confirmed" INTEGER, "deaths" INTEGER, "recovered" INTEGER);- Uncomment line: If you have commented line #7 ImportGdc4.rb to test the job, uncomment it.
- Run the server:
$ rails s- In another terminal, start
rakejobs.
$ cd mahrasa
$ rake delayed:work- Access the application in the browser at http://localhost:3000.
- Click on the link "Upload global_daily_cumulative.csv."
- Click the button "Choose File."
- In the file explorer, navigate to the folder mahrasa/test and select the file global_daily_cumulative.csv.
- You will see a message that the file is received and gives a link to check the status of the job. If you click the link you will go to the status page and know the current status of the job.
View when the job is enqueued:

View after the job is processed:

You can check in the database that the CSV file row count is the same as the record count in the table.
sqlite> select count(*) from global_daily_cumulative;
158987Final Thoughts
The word "delayed" has an unfortunate negative connotation. When I first heard the term "delayed jobs," I thought that these were slow and inefficient jobs suffering from inefficient code and had to be tuned at the server/database level, even code reviewed. Later on, I realized what they actually were. These were just asynchronously executed objects and the word "delayed" was being used as an adjective because they used the library called "delayed_job."
Use the available gems and time them to your sample workloads. It may so happen that the speed difference among these is not that critical. For really high volume processing you may have to go to first RabbitMQ and then finally Apache Kafka.
Opinions expressed by DZone contributors are their own.
Comments