Recommendation Engine Models
By
 ·
·
Interview
·
·
Interview
Likes
(2)
Likes
There are no likes...yet! 👀
Be the first to like this post!
It looks like you're not logged in.
Sign in to see who liked this post!
Comment
Save
26.9K Views
Join the DZone community and get the full member experience.
Join For FreeIn
a classical model of recommendation system, there are "users" and
"items". User has associated metadata (or content) such as age, gender,
race and other demographic information. Items also has its metadata
such as text description, price, weight ... etc. On top of that, there
are interaction (or transaction) between user and items, such as userA
download/purchase movieB, userX give a rating 5 to productY ... etc.

Now given all the metadata of user and item, as well as their interaction over time, can we answer the following questions ...
- What is the probability that userX purchase itemY ?
- What rating will userX give to itemY ?
- What is the top k unseen items that should be recommended to userX ?
In this approach, we make use of the metadata to categorize user and item and then match them at the category level. One example is to recommend jobs to candidates, we can do a IR/text search to match the user's resume with the job descriptions. Another example is to recommend an item that is "similar" to the one that the user has purchased. Similarity is measured according to the item's metadata and various distance function can be used. The goal is to find k nearest neighbors of the item we know the user likes.
Collaborative Filtering Approach
In this approach, we look purely at the interactions between user and item, and use that to perform our recommendation. The interaction data can be represented as a matrix.
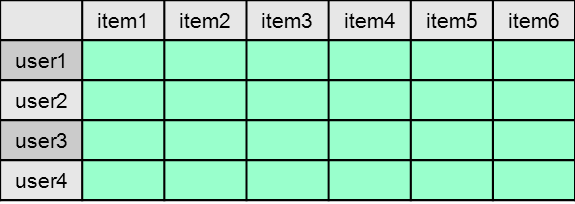
Notice that each cell represents the interaction between user and item. For example, the cell can contain the rating that user gives to the item (in the case the cell is a numeric value), or the cell can be just a binary value indicating whether the interaction between user and item has happened. (e.g. a "1" if userX has purchased itemY, and "0" otherwise.
The matrix is also extremely sparse, meaning that most of the cells are unfilled. We need to be careful about how we treat these unfilled cells, there are 2 common ways ...
- Treat these unknown cells as "0". Make them equivalent to user giving a rate "0". This may or may not be a good idea depends on your application scenarios.
- Guess what the missing value should be. For example, to
guess what userX will rate itemA given we know his has rate on itemB, we
can look at all users (or those who is in the same age group of userX)
who has rate both itemA and itemB, then compute an average rating from
them. Use the average rating of itemA and itemB to interpolate userX's
rating on itemA given his rating on itemB.
In this model, we do the following
- Find a group of users that is “similar” to user X
- Find all movies liked by this group that hasn’t been seen by user X
- Rank these movies and recommend to user X

This introduces the concept of user-to-user similarity, which is basically the similarity between 2 row vectors of the user/item matrix. To compute the K nearest neighbor of a particular users. A naive implementation is to compute the "similarity" for all other users and pick the top K.
Different similarity functions can be used. Jaccard distance function is defined as the number of intersections of movies that both users has seen divided by the number of union of movies they both seen. Pearson similarity is first normalizing the user's rating and then compute the cosine distance.
There are two problems with this approach
- Compare userX and userY is expensive as they have millions of attributes
- Find top k similar users to userX require computing all pairs of userX and userY
Location Sensitive Hashing and Minhash
To
resolve problem 1, we approximate the similarity using a cheap
estimation function, called minhash. The idea is to find a hash
function h() such that the probability of h(userX) = h(userY) is
proportion to the similarity of userX and userY. And if we can find 100
of h() function, we can just count the number of such function where
h(userX) = h(userY) to determine how similar userX is to userY. The
idea is depicted as follows ...

It will be expensive to permute the rows if the number of rows is large. Remember that the purpose of h(c1) is to return row number of the first row that is 1. So we can scan each row of c1 to see if it is 1, if so we apply a function newRowNum = hash(rowNum) to simulate a permutation. Take the minimum of the newRowNum seen so far.
As an optimization, instead of doing one column at a time, we can do it a row at the time, the algorithm is as follows

To solve problem 2, we need to avoid computing all other users' similarity to userX. The idea is to hash users into buckets such that similar users will be fall into the same bucket. Therefore, instead of computing all users, we only compute the similarity of those users who is in the same bucket of userX.
The idea is to horizontally partition the column into b bands, each with r rows. By pick the parameter b and r, we can control the likelihood (function of similarity) that they will fall into the same bucket in at least one band.

Item-based Collaboration Filter
If we transpose the user/item matrix and do the same thing, we can compute the item to item similarity. In this model, we do the following ...
- Find the set of movies that user X likes (from interaction data)
- Find a group of movies that is similar to these set of movies that we know user X likes
- Rank these movies and recommend to user X
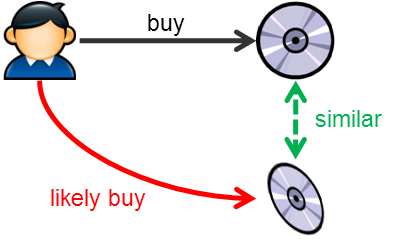
It turns out that computing item-based collaboration filter has more benefit than computing user to user similarity for the following reasons ...
- Number of items typically smaller than number of users
- While
user's taste will change over time and hence the similarity matrix need
to be updated more frequent, item to item similarity tends to be more
stable and requires less update.
If we look back at the matrix, we can see the matrix multiplication is equivalent to mapping an item from the item space to the user space. In other words, if we view each of the existing item as an axis in the user space (notice, each user is a vector of their rating on existing items), then multiplying a new item with the matrix gives the same vector like the user. So we can then compute a dot product with this projected new item with user to determine its similarity. It turns out that this is equivalent to map the user to the item space and compute a dot product there.

In other words, multiply the matrix is equivalent to mapping between item space and user space. Now lets imagine there is a hidden concept space in between. Instead of jumping directly from user space to item space, we can think of jumping from user space to a concept space, and then to the item space.
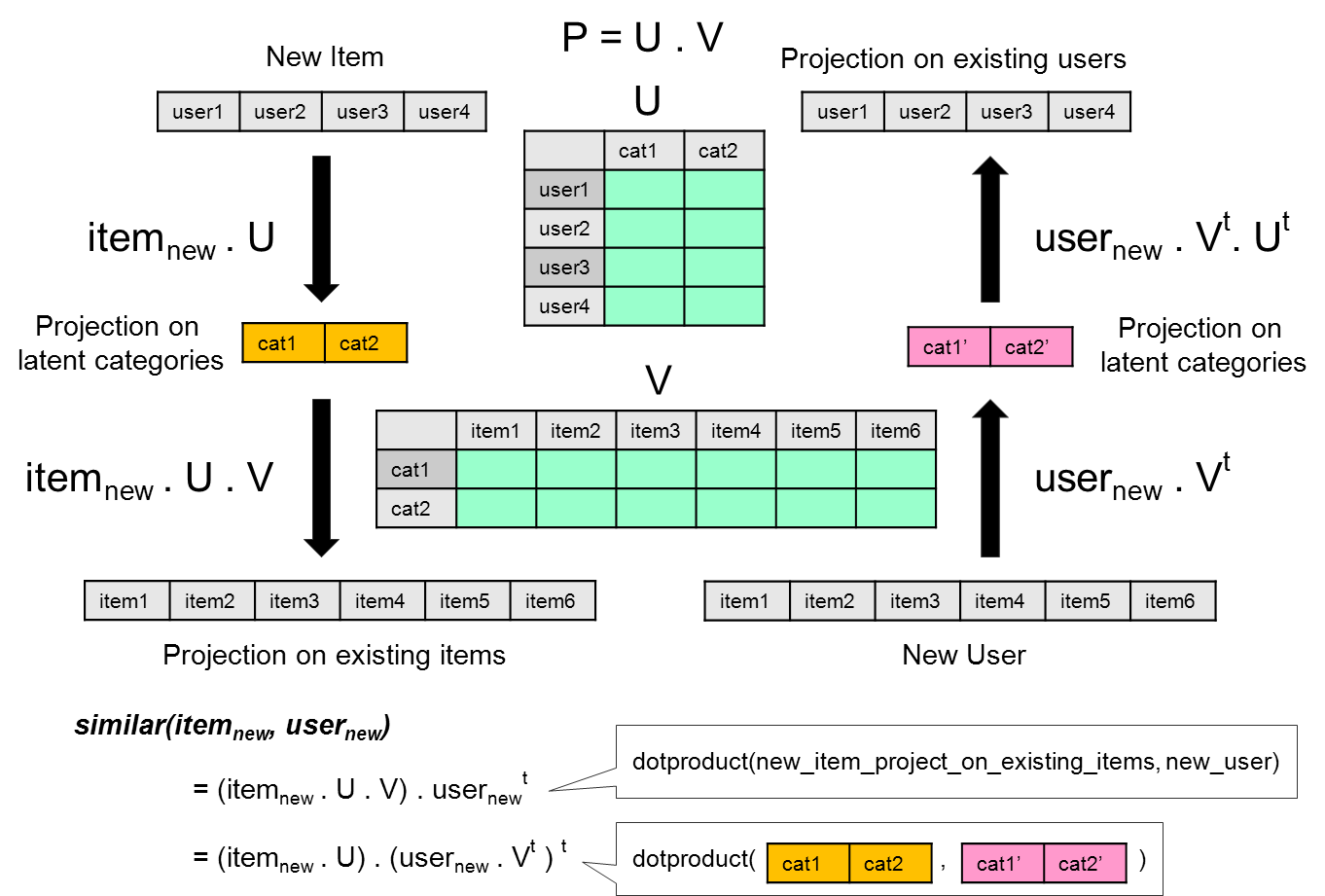
Notice that here we first map the user space to the concept space and also map the item space to the concept space. Then we match both user and item at the concept space. This is a generalization of our recommender.
In other words, we can decompose P into U*squareroot(D) and squareroot(D)*V.
Calculate SVD decomposition for matrix with large dimensions is expensive. Fortunately, if our goal is to compute an SVD approximation (with k diagonal non-zero value), we can use the random projection mechanism as describer here.
Association Rule Based
In this model, we use the market/basket association rule algorithm to discover rule like ...
{item1, item2} => {item3, item4, item5}
We represent each user as a basket and each viewing as an
item (notice that we ignore the rating and use a binary value). After
that we use association rule mining algorithm to detect frequent item
set and the association rules. Then for each user, we match the user's
previous viewing items to the set of rules to determine what other
movies should we recommend.
Evaluate the recommender
After we have a recommender, how do we evaluate the performance of it ?
The basic idea is to use separate the data into the
training set and the test set. For the test set, we remove certain
user-to-movies interaction (change certain cells from 1 to 0) and
pretending the user hasn't seen the item. Then we use the training set
to train a recommender and then fit the test set (with removed
interaction) to the recommender. The performance is measured by how
much overlap between the recommended items with the one that we have
removed. In other words, a good recommender should be able to recover
the set of items that we have removed from the test set.
Leverage tagging information on items
In
some cases, items has explicit tags associated with them (we can
considered the tags is a user-annotated concept space added to the
items). Consider each item is described with a vector of tags. Now
user can also be auto-tagged based on the items they have interacted.
For example, if userX purchase itemY which is tagged with Z1, and Z2.
Then user will increase her tag Z1 and Z2 in her existing tag vector.
We can use a time decay mechanism to update the user's tag vector as
follows ...
To recommend an item to the user, we simply need to calculate the top k items by computing the dot product (ie: cosine distance) of the user tag vector and the item tag vector.
Source: http://horicky.blogspot.com/2011/09/recommendation-engine.html
Space (architecture)
Concept (generic programming)
Matrix (protocol)
Row (database)
Interaction
Data structure
Engine
Opinions expressed by DZone contributors are their own.
Comments