Redis Is Not Just a Cache
In this article, take a look at Redis as a cache, relational database advantages, and more.
Join the DZone community and get the full member experience.
Join For FreeDo You Always Need a Classic Database?
For some time now the huge amount of data that needs to be processed forces any app to have a caching strategy in front of the databases. The databases, even with huge underline optimizations, can’t always provide enough speed and availability. The main reason is that the farther is the data, the harder it is to access it. Another reason is that usually, a database persists data on disk and not on RAM. They do have embedded cache on RAM for increasing the optimizations but, even so, having a dedicated separated cache is a well-used strategy.
The usual solution to solve the performance issues when accessing a database is caching. Caching isn’t new. Caching actually means to keep a smaller amount of data that you frequently access closer to you. We have caches on processors, databases have embedded caches also and you can even code your own cache in your app.
But things evolved and now we have highly available distributed in-memory caches which are used by various instances at the same time
Redis as a Cache
Maybe the most popular distributed in-memory data store, which is not a cache but it’s used as one, is Redis. To quote from their documentation:
“Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes with radius queries and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.”
Redis is fast. It is known as one of the fastest datastores out there. It is optimized for CPU caches and has minimum to no context switching. It was designed from the start to be an in-memory database. This doesn’t mean just to move the data from disks to RAM. It was, from the start, optimized for that.
Since Redis is very fast and can store all kinds of data structures, it was a good candidate for distributed caching.
Therefore, Redis gained very high popularity as being a cache. There are even cache-loaders libraries that use Redis as a cache layer between an app and a database. Please look at the Redisson map loader, for example.
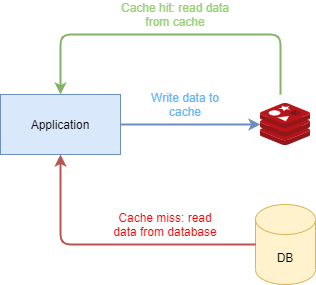
So, using a distributed cache highly improves the performance. But the code and the architecture is more complex now. The data is duplicated. Is located both on the DB and on the cache, and we have to keep them in sync. The code should manage the whole caching strategy, invalidate the cache, repopulate the cache, just for preserving the data consistency. We achieve higher performance and scalability indeed but by introducing a risky complexity.
Data Is Duplicated
You might ask why should we keep the data in both places? Couldn’t we keep the data just in Redis? By doing so, we will reduce the code complexity. But first, let’s look at some of the characteristics and advantages of a classic database to see if we can achieve them using Redis directly.
Relational Database Advantages
Traditionally speaking, a cache does not persist data for a long period. We keep the data in the cache just for quick access but for a long time persistence, we usually use a central database.
And beside the persistence, a relational database (RDBMS) gives you other characteristics for data consistency. With a relational database, you can define all kinds of relations between data, all kinds of constraints, complex queries, and it is built to guarantee the consistency between multiple related tables. It has some important advantages, and, even with the popularity of NoSQL databases, the relational databases aren’t going anywhere near time soon.
But using Redis as a cache and a relational database as a primary persistence store adds a layer of complexity, because you have to keep the data synchronous between them and your code would have to manage that.
Considering your caching strategy, you will have to build some complex code to send the data between Redis and the database. And don’t misunderstand me here, sometimes you will have to do this. Like I said before, an RDBMS has its advantages and we can’t just throw it away.
But do we have to do this every time? What happens if we don’t need a very complex relation between different data, and it is enough to just store a key map? Could we not use an RDBMS?
Redis as the Central Datastore
Like I said before, the advantages of an RDBMS are relational consistency and long time persistence. Well, if we don’t need a relational mapping between the data it will remain just the persistence. There are a lot of NoSQL databases that offer key map stores, but we can use Redis directly for that.
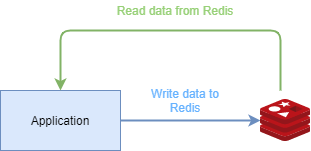
Redis Persistence
There are two persistence models in Redis. RDB (stands for Redis Database File) and AOF (stands for Append Only File).
RDB saves snapshots at specified time intervals. They are great for restoring the state quickly thus being good for backups. RDB maximize Redis performances since the only work done by the parent process is to fork a child process which will create the snapshot.
But since RDB is scheduled at a specific time interval it is not a good option if you cannot afford to eventually lose some data. Forking is an expensive operation and you cannot afford to fork after every data change so it could happen that the most recent data to not be saved in the last snapshot.
AOF is a different persistence model. It consists of an append-only file in which you only add every data at the final. It is more durable since, usually, the fsync policy is scheduled way often than a whole rdb snapshot. And, since the file is append-only, the data is incorruptible. Even if a power outage comes when the last line isn’t written completely, you can easily rebuild the state until that broken line.
But it has some disadvantages. The first one is that the aof file is usually bigger than the equivalent rdb file. Also, if the fsync policy is scheduled too often, for example after every write command, the performance will be drastically reduced. By default, the fsync is scheduled to run every second.
Which one should you use?
If you want a safeness level similar to what Postgres offers, you will have to use them both. By using RDB you can recover faster after a restart and by using AOF you will avoid the data loss in case of a failure. But, if you can afford some losses, you can go along just with RDB. Keep in mind that Redis plans to unite them both into a single persistence model.
Other Advantages
The Future Is Byte Addressable
Since the spinning disks were a de facto persistence unit for so much time, most of the current databases are still optimized for running on spinning disks. They have some optimizations like data co-location to reduce rotational lag and even incorporate specialized formatting to place indexes on particular parts of the platter. But these kinds of optimizations don't make sense on current technologies like DRAM or SSD which are based on NAND flash memory. As such, everything moves from accessing spinning disks to SSD and DRAM. Redis stores data on DRAM and it is optimized to be byte-addressable. The future is byte addressable and Redis is already there.
Scalability and High Availability
Redis offers different ways to achieve scalability and high availability.
You can achieve horizontal scalability using Redis sharding by splitting your data across different Redis nodes. Sharding will release the burden from a single instance and you will benefit from multiple cores and computational power. However, you should be aware of the limitations of sharding as the inability to support multi-key operations and transactions.
High availability is obtained using replication. The master node is synchronously replicated and you will be protected against node failures, data center failures and Redis process failures. If the master fails, the replica will take its place. It is also possible to have a replica in a different AZ. This will protect you against some catastrophic events where an entire AZ would fail.
If you are going to use the Redis enterprise cluster, all of this will be abstract to you. You will have sharding and high availability without the need of extra code. You can code as you would be connected to just a simple Redis instance.
If you want to find more about Redis scalability please look at this link.
Complex Data Structures
Redis could handle not just strings like a traditional key-value store, but different data structures like: binary safe strings, lists, sets, sorted sets, hash sets, bitmaps, hyper logs, streams, etc. This makes Redis not just a key-value store but an entire data structure server. For more details about the Redis data structure, please look here.
Not a Silver Bullet
Everything sounds great until here, but as a general truth, nothing is a silver bullet, and, of course, neither is Redis. The main disadvantage is that all the data should fit in memory. This makes Redis suitable for machines that can have sufficient RAM for all of your data. If not, you have to split your data across different shards, but be aware that you lose some guarantees like transactions, pipelining, or pub/sub.
Conclusion
For a very long time, Redis was seen as just a cache. A very good distributed cache but still just a cache between a central app and the main DB. As you can see, Redis is much more than just a cache, and it tries to escape from this misconception. Redis is not a cache, it is a distributed data store. It can handle different data structures in a thread-safe mode incredibly fast and provides different mechanisms for data persistency.
Considering all of these, even if Redis is used very successfully as a cache, it can do a lot more. If you don’t need some SQL properties like relational data and high storage, why should you create a complicated three-level layer system using an app, Redis as a cache and a DB? In those scenarios, you can use just Redis as the main persistence layer.
Opinions expressed by DZone contributors are their own.
Comments