The Right to Be Forgotten in Event-Driven Data Products
Using event sourcing to propagate deletes across the data mesh for consistent retention and right-to-be-forgotten compliance.
Join the DZone community and get the full member experience.
Join For FreeCompanies operating under regulatory frameworks such as GDPR, CPPA, and other privacy laws increasingly find themselves under pressure to enforce strict and timely retention and deletion policies for customer data. These regulations not only require data to be stored securely but also mandate that organizations delete customer information wherever it exists when the customer requests deletion, upon customer exit, or when retention windows expire. In practice, this "right to be forgotten" means that every copy, transformation, and analytical artifact referencing that individual must be identified and purged within defined timeframes.
In many organizations, especially those with complex analytical ecosystems, this is far more difficult than it sounds. Operational systems often have clear deletion semantics, but analytical platforms (data lakes, warehouses, dashboards, machine learning pipelines) tend to accumulate replicated and transformed copies of customer data that sit outside the operational flow. When a deletion occurs upstream, downstream analytical systems may not hear about it, may not react in time, or may not have a reliable mechanism to trace lineage and apply deletions consistently. This gap creates compliance risk, audit failures, and fragmentation across analytical domains.
In this blog, I’ll explore how event sourcing concepts that are already widely used to replicate operational state between applications can be extended into the analytical plane to solve real-world data retention use cases. By using the same real-time event rails (such as Kafka) to propagate delete signals across data products and aggregated data products, organizations can achieve consistent, auditable, and timely enforcement of retention and right-to-be-forgotten requirements throughout their entire data mesh.
The Challenge With Deletes in Analytics
Many analytical systems can move inserts and updates quickly through CDC streams, event hubs, or scheduled ingestion jobs, but deletes rarely receive the same treatment. In many pipelines, delete events show up as tombstones or null payloads that are easy to overlook, especially when ingestion frameworks focus primarily on inserting and updating data. The problem becomes even more pronounced in analytical storage layers built on append-only formats like Parquet, which cannot apply row-level deletes without an overlay such as Delta Lake, Hudi, or Iceberg. When those overlays are not used or not used consistently across the data ecosystem, and when teams introduce their own filtering logic during ingestion, delete events may have nowhere to go and simply disappear without being applied downstream.
These issues increase as data moves across domains and is transformed into new data products or aggregated data products. Derived data products, aggregates, and ML features often encode upstream information in ways that are not directly tied back to the original record, making it difficult to know what should be removed when a delete event arrives. Without a standard mechanism to propagate and enforce deletes across every dependent data product, each team handles them differently: some immediately, some periodically, and some not at all. The result is that inserts and updates flow naturally through analytics systems, but deletions become fragmented and inconsistent, leaving personal data lingering in downstream data products long after it has been removed from the source.
Bringing event-sourcing principles to the analytical plane provides a more reliable path forward. Instead of treating deletes as exceptional cases or relying on ad-hoc cleanup logic, we can treat them as first-class events that travel through the same rails, Kafka, or similar systems that already carry updates. When an upstream change or deletion occurs, the data product responsible for representing that domain updates its state and emits an event reflecting that change. Downstream data products then react deterministically, removing or adjusting any relayed or derived data tied to that domain record. This creates an ecosystem where retention and "right to be forgotten" are enforced not through manual coordination or periodic cleanup controls, but through an ongoing stream of state transitions that every data product and every consumer of a data product can trust.
Solution
Event sourcing gives applications a reliable way to share state changes (creates, updates, and deletes) through replayable append-only logs. When one service updates customer information or removes it entirely, downstream services learn about it by consuming the same ordered stream of events. They update or delete their own local view of state accordingly, keeping the system consistent without ever relying on snapshots or periodic batch syncs.
There are many ways an organization might try to solve the challenge of propagating deletes and retention rules across analytical systems. The approach shown here is simply one representation, but it illustrates a pattern that brings clarity and consistency to how deletions should flow through a data mesh. At the center of the model is a replayable event log, such as Kafka, which acts as the shared rail that carries state changes from operational systems into data products, and then from those products into downstream aggregate data products and consumers.
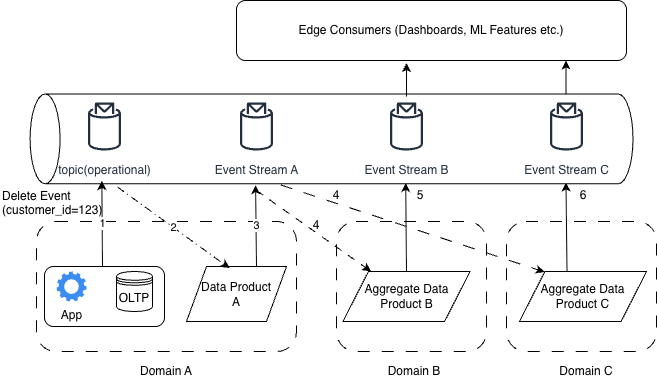
In the proposed solution above, the operational data store emits a delete event when a customer record is removed or when a retention window expires. That event is published to a Kafka topic, where the data product responsible for representing that source domain (Domain A) consumes it and applies the deletion to its own analytical state. Once the data product (Data Product A) updates its local view, it then emits its own event describing the new state of the domain record. This second event flows back onto the same Kafka rail (on a different cross-data product topic) and serves as the signal that downstream data product(s) must use to remain consistent.
Downstream data products (B and C) listen to these events just as upstream ones do. When they receive a deletion, they must apply it to their own aggregates, derived features, curated views, or any domain-specific transformations they maintain. These products can also publish events for their own dependents. The same pattern continues all the way to the edges of the analytical ecosystem, including reporting layers, ML feature pipelines, and any other consumer that maintains state based on upstream information.
The key idea is that every data product and every consumer of a data product subscribes to the same flow of events and uses those events to keep its own state aligned with the current truth. Deletes are no longer handled through manual cleanup or scattered logic across pipelines. They move through the mesh the same way inserts and updates do, and every system that holds a copy or derivative of customer information applies those changes in a predictable and auditable way. This creates a reliable environment where retention and the "right to be forgotten" are not special cases but natural state transitions carried through the same stream that powers the rest of the organization.
Conclusion
In this blog, I explored how event-sourcing techniques can be extended beyond operational systems to solve one of the hardest problems in analytics, the consistent enforcement of data retention and delete requirements across data products and their dependents. By treating deletions as first-class events and propagating them through a shared event log, organizations can ensure that every downstream data product, aggregate data product, and consumer that depends on that upstream state reacts deterministically. This creates an analytical environment where the "right to be forgotten" is not an afterthought but an inherent property of how data flows through the mesh.
By using event-sourcing techniques to propagate delete events, organizations can achieve reliable and auditable retention across domains, reduce compliance risk, and remove the fragile cleanup logic that often accumulates in analytical platforms. If you are already using Kafka, PubSub, or CDC streams to synchronize operational systems, the same foundations can bring order and consistency to your analytical stack. Consider evaluating where delete propagation breaks down today, and whether an event-driven approach could provide the clarity and trustworthiness your data products need.
Opinions expressed by DZone contributors are their own.
Comments