Scalable System Design Patterns
By
 ·
·
News
·
·
News
Likes
(5)
Likes
There are no likes...yet! 👀
Be the first to like this post!
It looks like you're not logged in.
Sign in to see who liked this post!
Comment
Save
48.5K Views
Join the DZone community and get the full member experience.
Join For FreeLooking back after 2.5 years since my
previous post on scalable system design techniques, I've observed
an emergence of a set of commonly used design patterns. Here is my
attempt to capture and share them.
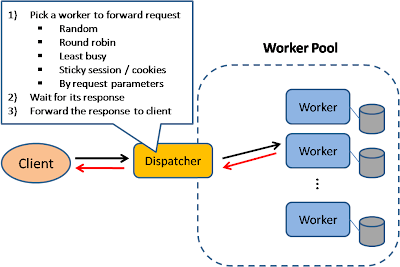
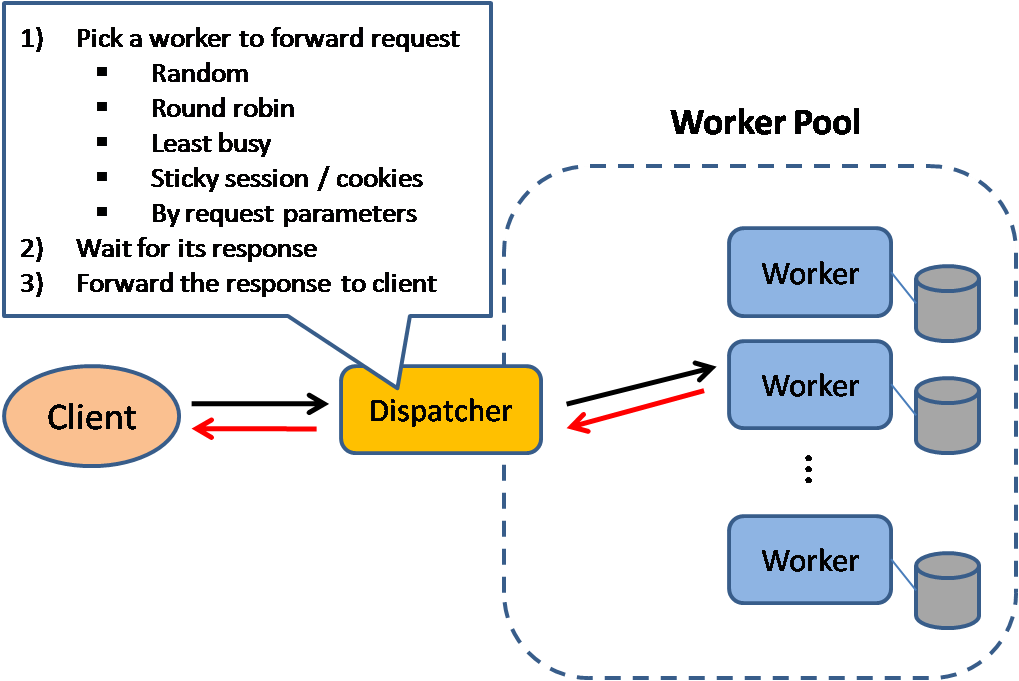
Load Balancer
In this model, there is a dispatcher that determines which worker instance will handle the request based on different policies. The application should best be "stateless" so any worker instance can handle the request.
This pattern is deployed in almost every medium to large web site setup.
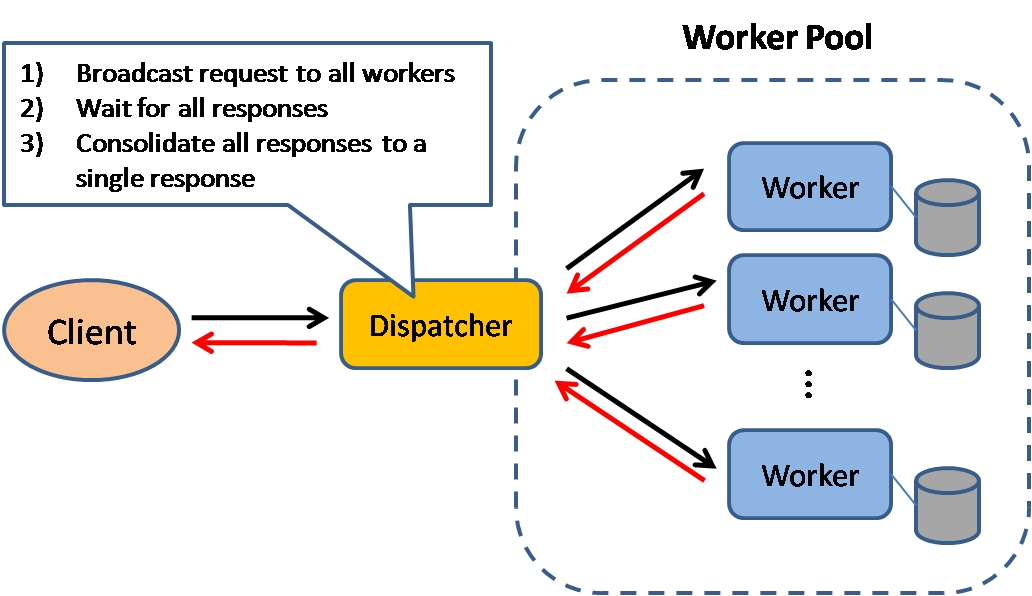
Scatter and Gather
In this model, the dispatcher multicast the request to all workers of the pool. Each worker will compute a local result and send it back to the dispatcher, who will consolidate them into a single response and then send back to the client.
This pattern is used in Search engines like Yahoo, Google to handle user's keyword search request ... etc.

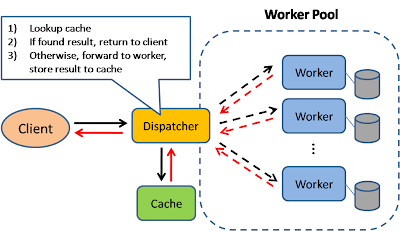
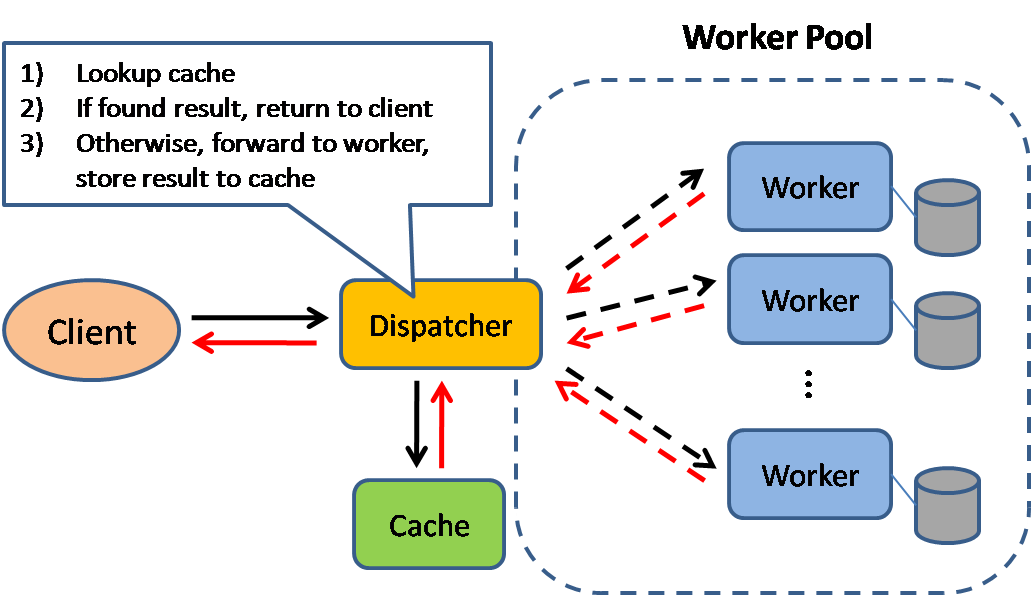
Result Cache
In this model, the dispatcher will first lookup if the request has been made before and try to find the previous result to return, in order to save the actual execution.
This pattern is commonly used in large enterprise application. Memcached is a very commonly deployed cache server.
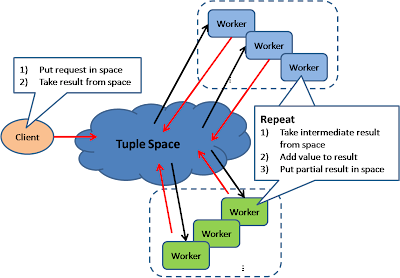
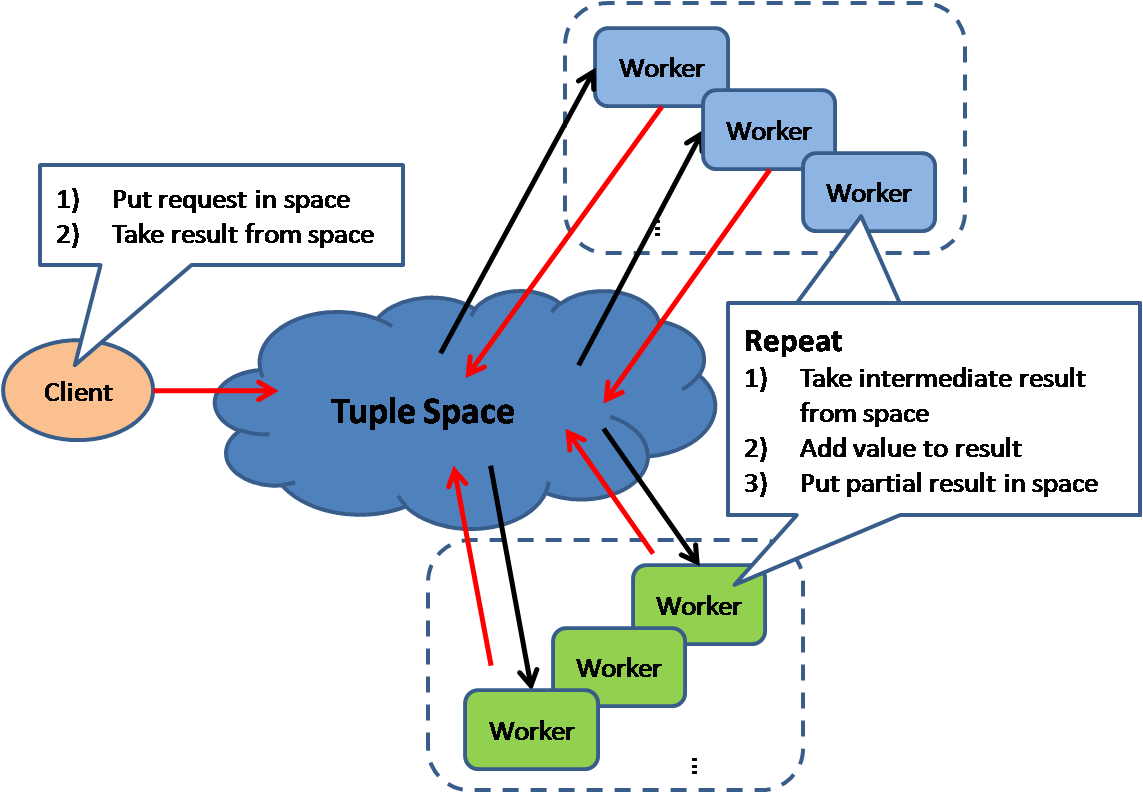
Shared Space
This model also known as "Blackboard"; all workers monitors information from the shared space and contributes partial knowledge back to the blackboard. The information is continuously enriched until a solution is reached.
This pattern is used in JavaSpace and also commercial product GigaSpace.
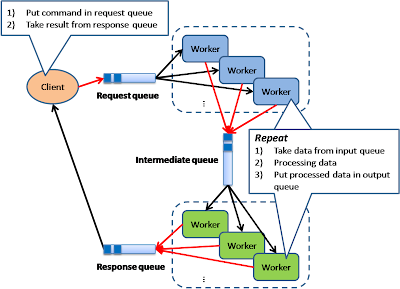
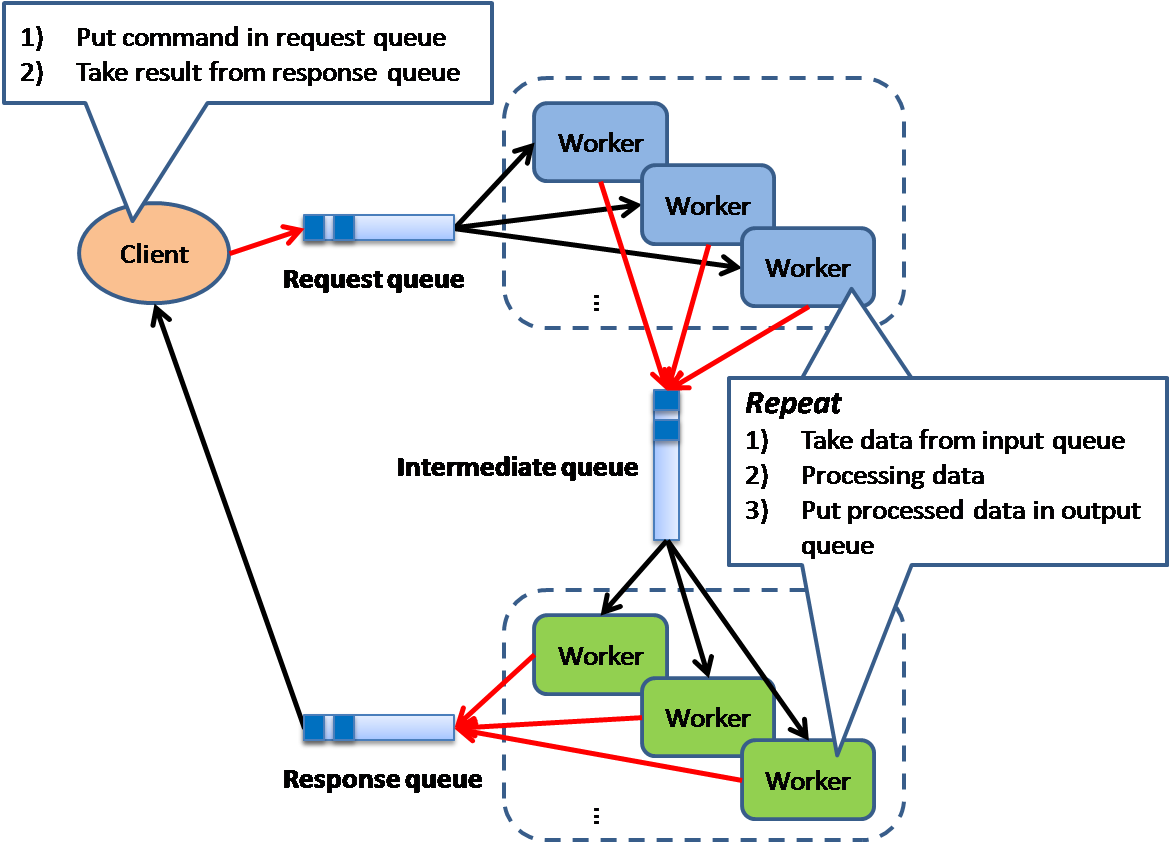
Pipe and Filter
This model is also known as "Data Flow Programming"; all workers connected by pipes where data is flow across.
This pattern is a very common EAI pattern.
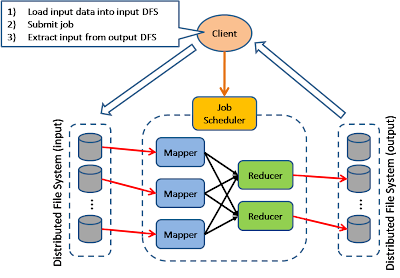
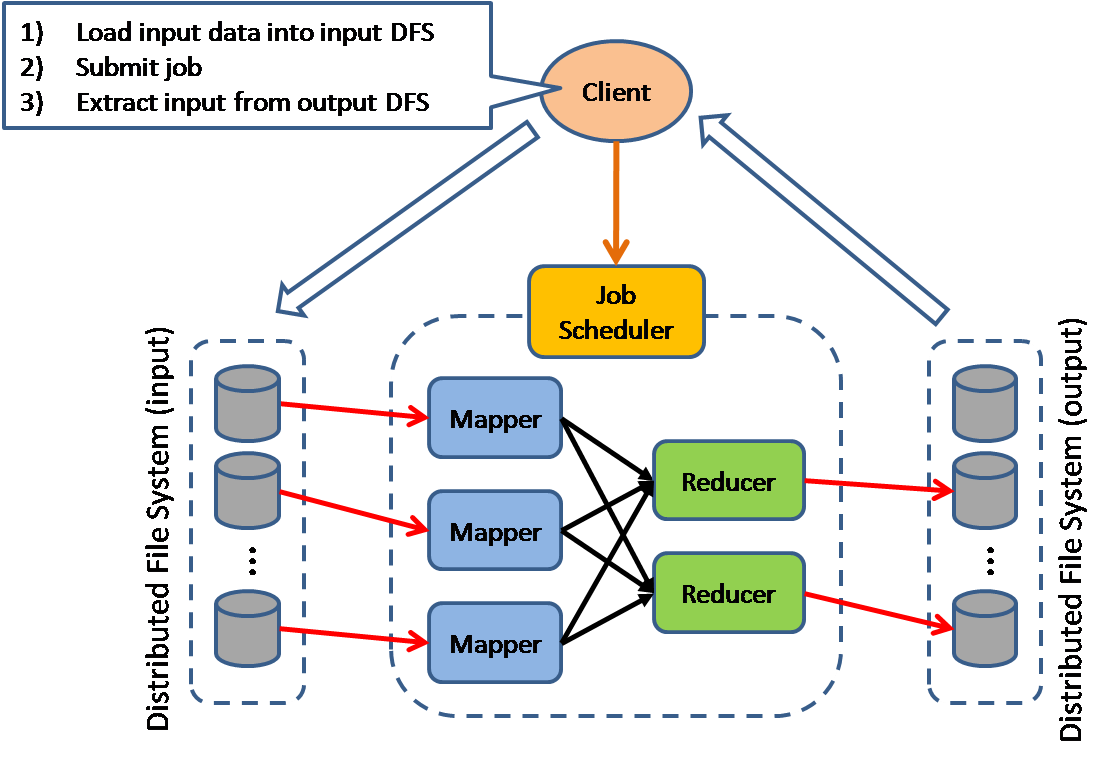
Map Reduce
The model is targeting batch jobs where disk I/O is the major bottleneck. It use a distributed file system so that disk I/O can be done in parallel.
This pattern is used in many of Google's internal application, as well as implemented in open source Hadoop parallel processing framework. I also find this pattern can be used in many many application design scenarios.
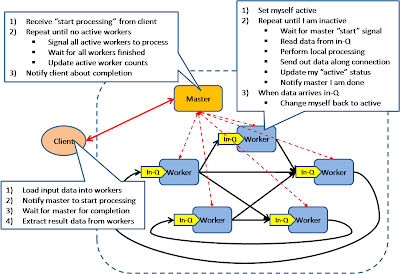
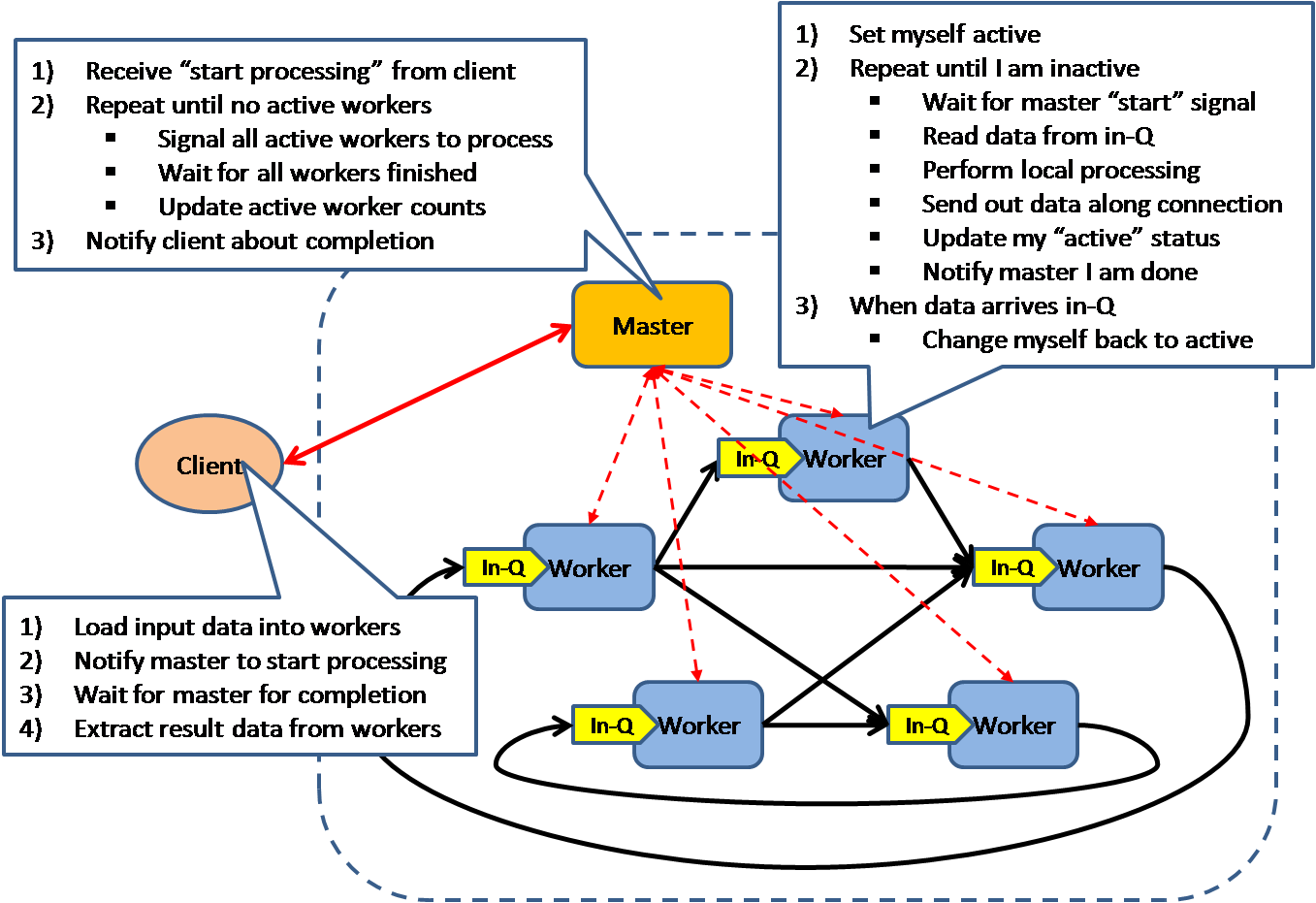
Bulk Synchronous Parellel
This model is based on lock-step execution across all workers, coordinated by a master. Each worker repeat the following steps until the exit condition is reached, when there is no more active workers.
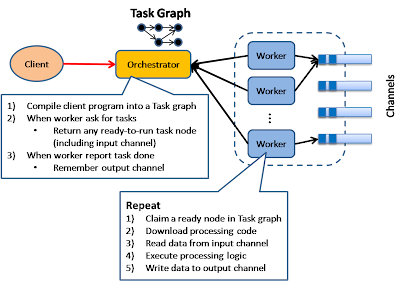
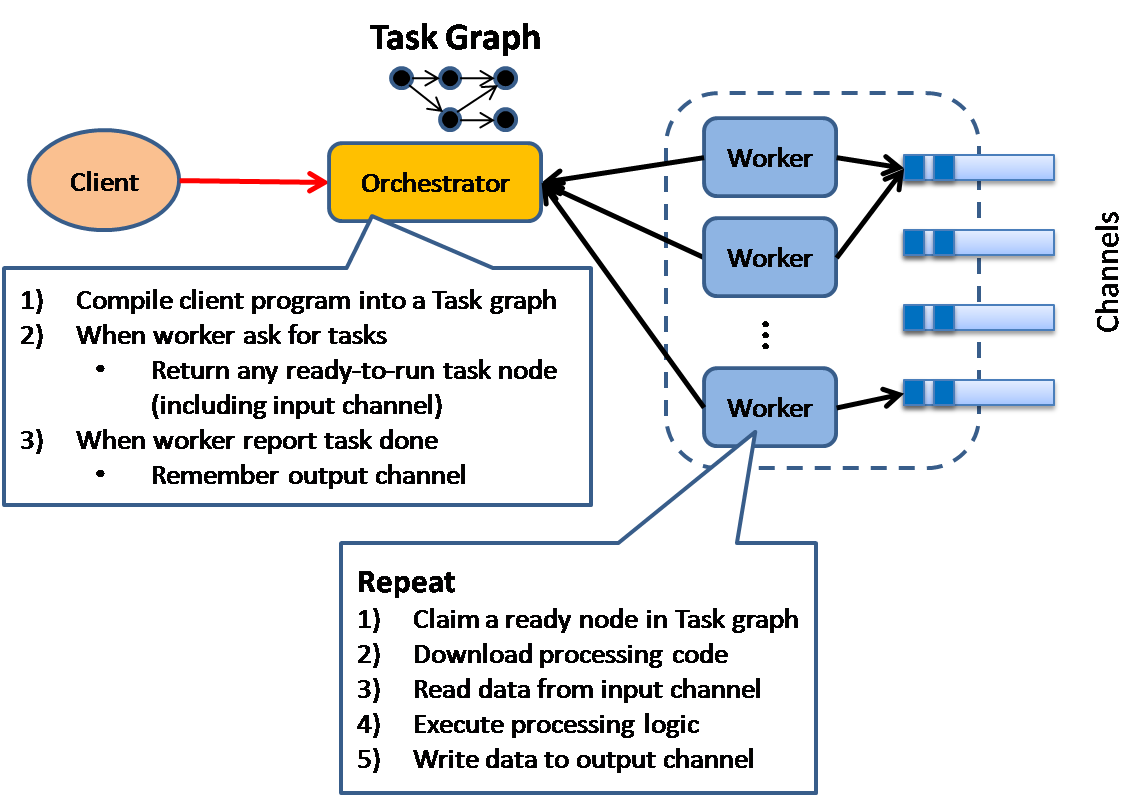
Execution Orchestrator
This model is based on an intelligent scheduler / orchestrator to schedule ready-to-run tasks (based on a dependency graph) across a clusters of dumb workers.
This pattern is used in Microsoft's Dryad project
Although I tried to cover the whole set of commonly used design pattern for building large scale system, I am sure I have missed some other important ones. Please drop me a comment and feedback.
Also, there is a whole set of scalability patterns around data tier that I haven't covered here. This include some very basic patterns underlying NOSQL. And it worths to take a deep look at some leading implementations.
Load Balancer
In this model, there is a dispatcher that determines which worker instance will handle the request based on different policies. The application should best be "stateless" so any worker instance can handle the request.
This pattern is deployed in almost every medium to large web site setup.
Scatter and Gather
In this model, the dispatcher multicast the request to all workers of the pool. Each worker will compute a local result and send it back to the dispatcher, who will consolidate them into a single response and then send back to the client.
This pattern is used in Search engines like Yahoo, Google to handle user's keyword search request ... etc.
Result Cache
In this model, the dispatcher will first lookup if the request has been made before and try to find the previous result to return, in order to save the actual execution.
This pattern is commonly used in large enterprise application. Memcached is a very commonly deployed cache server.
Shared Space
This model also known as "Blackboard"; all workers monitors information from the shared space and contributes partial knowledge back to the blackboard. The information is continuously enriched until a solution is reached.
This pattern is used in JavaSpace and also commercial product GigaSpace.
Pipe and Filter
This model is also known as "Data Flow Programming"; all workers connected by pipes where data is flow across.
This pattern is a very common EAI pattern.
Map Reduce
The model is targeting batch jobs where disk I/O is the major bottleneck. It use a distributed file system so that disk I/O can be done in parallel.
This pattern is used in many of Google's internal application, as well as implemented in open source Hadoop parallel processing framework. I also find this pattern can be used in many many application design scenarios.
Bulk Synchronous Parellel
This model is based on lock-step execution across all workers, coordinated by a master. Each worker repeat the following steps until the exit condition is reached, when there is no more active workers.
- Each worker read data from input queue
- Each worker perform local processing based on the read data
- Each worker push local result along its direct connection
Execution Orchestrator
This model is based on an intelligent scheduler / orchestrator to schedule ready-to-run tasks (based on a dependency graph) across a clusters of dumb workers.
This pattern is used in Microsoft's Dryad project
Although I tried to cover the whole set of commonly used design pattern for building large scale system, I am sure I have missed some other important ones. Please drop me a comment and feedback.
Also, there is a whole set of scalability patterns around data tier that I haven't covered here. This include some very basic patterns underlying NOSQL. And it worths to take a deep look at some leading implementations.
File system
Design
Published at DZone with permission of Ricky Ho. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments