Using Schema Registry to Manage Real-Time Data Streams in AI Pipelines
Learn how schema registries ensure data consistency, integrity, and scalability in real-time AI pipelines using Apache Kafka and modern streaming tools.
Join the DZone community and get the full member experience.
Join For FreeIn today’s AI-powered systems, real-time data is essential rather than optional. Real-time data streaming has started having an important impact on modern AI models for applications that need quick decisions. However, as data streams increase in complexity and speed, ensuring data consistency is a significant engineering challenge. As we know, AI models are heavily dependent on the input data used to train them. The quality of this input data is very important and should not be corrupted or contain errors. The accuracy, reliability, and fairness of the model’s predictions can be significantly affected if the quality of the input data is compromised.
The above statement is concrete, while AI models are being developed and subsequently made ready to identify patterns, make predictions based on input data. If we integrate these developed and tested trained AI models with real-time data stream processing pipelines, the predictions can be achieved on the fly. Because the real-time data streaming plays a key role for AI models as it allows them to handle and respond to data as it comes in, instead of just using old fixed datasets. You could read here my previous article, “AI on the Fly: Real-Time Data Streaming from Apache Kafka to Live Dashboards.” But the big question is how we can ensure real-time data that comes as a stream from various sources is free from errors and not at all bad data. By spotting patterns and trained data, AI systems decide. If this data has mistakes, doesn’t add up, or is messy, the model might pick up wrong patterns. This can lead to outputs that are biased, off the mark, or even risky.
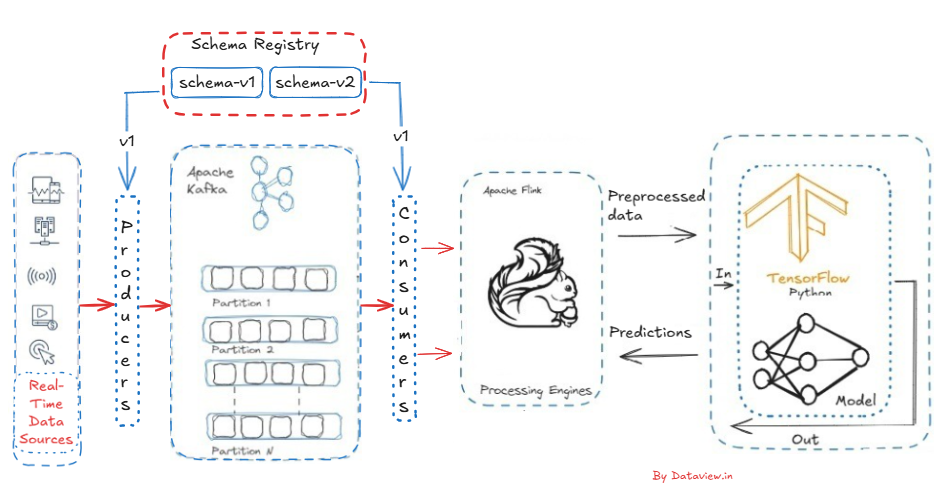
However, as data streams become more complex and attain greater velocity, managing data consistency and schema evolution is a formidable engineering challenge. This is where Schema Registry comes in. It is the central location for all data schema definitions and so plays a vital role in maintaining integrity across real-time pipelines, compatibility among various downstream applications (separate from raw sources), and handling the scalability needs of these same pipelines.
What Scheme Registry Do
A schema registry is essential for data governance and consistency in a streaming platform by ensuring that messages follow a pre-defined structure before they are published to an Apache Kafka Topic. By using it to validate every incoming message against a known schema, the registry can save us from corrupt, invalid, and incompatible data being sent to Kafka that might disrupt downstream processing, cause consumer crashes, or hurt data quality. It stores a versioned history of all the schemas of registered data streams and schema change history.
Before constructing a Kafka-based data pipeline, we need to register or assign schema info in the schema registry about the data available at the source point. Schema Registry is a distributed storage layer for schemas by making use of the underlying storage mechanism of Kafka. It assigns a unique ID to each registered schema. Instead of appending the whole schema info, only the schema ID needs to be set with each set of records by the producer while sending messages to Kafka’s topic.
Where to Integrate Scheme Registry
Preferably, we can use Apache Kafka as a data ingestion tool in the entire streaming processing ecosystem, and the Schema Registry should be integrated at the point where data is produced. Besides, between the downstream consumers that continuously consume the messages/data from Kafka’s topic and subsequently push to processing engines like Flink, etc. Of course, Flink-1.18.1 can directly consume messages from Kafka’s topic without depending on additional consumers. You can read here. We need to register the schema with the Schema Registry that includes a schema identifier in the message payload prior to ingesting the stream from the sources to Kafka’s topic. By this identifier, all the downstream consumers fetch the correct schema from the Schema Registry that has already registered and subsequently deserialize and validate the incoming data. By doing this, schema consistency will be ensured, backwards/forward compatibility will be enabled, and data formats will be able to evolve safely over time, reducing the risk of runtime errors due to incompatible data.
Which Schema Registry to Use
The Schema Registry is an external process that runs on a server outside of the Apache Kafka cluster, and it is essentially a database for the schemas. There are multiple types of schema registries available that support various data serialization formats such as Avro, JSON, or Protobuf. Some are cloud native with a license subscription, and others are open-source.
Confluent Schema Registry
Confluent Schema Registry is the most popular and widely used schema registry. Developed by Confluent for use with Apache Kafka. Can be deployed to run as a standalone service or with Confluent Platform. Additionally, provide a REST API for registering and retrieving schemas. Avro, JSON Schema, and Protobuf are the supported data formats. It is available under the Confluent Community License as well as the Confluent Enterprise (subscription) license with additional advanced features.
Apicurio Registry
An open-source, cloud-native schema registry developed by Red Hat. Apicurio Registry has multiple storage options where we can configure it to store data in backend storage systems, depending on the use case. Storage options include Apache Kafka, PostgreSQL, or Microsoft SQL Server. It supports adding, removing, and updating the following artifact types:
- OpenAPI
- AsyncAPI
- GraphQL
- Apache Avro
- Google Protocol Buffers
- JSON Schema
- Kafka Connect schema
- WSDL
- XML Schema (XSD)
- AWS Glue Schema Registry
It is a fully managed schema registry provided by AWS that is tightly integrated with AWS services like Kinesis, MSK (Managed Streaming for Kafka), and Lambda. It has the features of automatic schema registration and evolution. Besides, it is an integration with AWS Glue ETL jobs and streaming services. This schema registry can be used when operating entirely within AWS and looking for serverless, managed schema governance.
Karapace
Karapace schema registry is a free and open-source tool and licensed under Apache 2.0. Karapace is a 1-to-1 replacement for Confluent’s Schema Registry and Apache Kafka REST proxy. It supports the storing of schemas in a central repository, which clients can access to serialize and deserialize messages. The schemas also maintain their own version histories and can be checked for compatibility between their respective versions. Karapace supports Avro, JSON Schema, and Protobuf data formats.
Takeaways
In today’s AI pipelines, which demand low-latency data ingestion and real-time inference, schema registries are a key element in ensuring that consistency and interoperability can be achieved across large numbers of distributed systems. By inverting data producers’ and consumers’ knowledge through a centralized (Schema) contract, Registries permit tight validation, backward-forward compatibility constraints, and controlled evolution. This ensures that upstream changes don’t break downstream consumers, one of the most important properties in a streaming architecture based on technologies like Apache Kafka or Flink.
In addition, schema registries allow for versioning, metadata management, and hook up to tooling — increasing the observability, monitoring, and operational reliability of the data layer. Since AI systems are more and more based on streaming data to make real-time decisions, a schema registry should not only be considered best practices but rather the core design principle for building scalable, fault-tolerant, and production-grade ML infrastructure.
Thank you for reading! If you found this article valuable, please consider liking and sharing it.
Published at DZone with permission of Gautam Goswami. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments