A Developer's Guide to Sentiment Analysis With Naive Bayes and Python
Learn sentiment analysis with Python and Scikit-learn using Naive Bayes. Build, train, and evaluate a text classifier for real-world applications.
Join the DZone community and get the full member experience.
Join For FreeSentiment analysis is a powerful tool for understanding customer feedback, social media comments, and product reviews. It allows us to programmatically determine whether a piece of text is positive, negative, or neutral. While complex models like Transformers (e.g., BERT) often grab the headlines, the classic Multinomial Naive Bayes classifier remains a surprisingly effective, efficient, and interpretable baseline, especially for text-based tasks.
In this guide, we'll walk through a complete sentiment analysis project using Python and Scikit-learn. We'll cover:
- Why Naive Bayes is a great starting point for text
- Exploratory Data Analysis (EDA) to understand our dataset
- Data preprocessing to clean and prepare the text
- Vectorization using TF-IDF
- Model training using a Scikit-learn
Pipeline - Performance evaluation with code for Confusion Matrix, ROC-AUC, and Precision-Recall curves
- Making predictions on new, unseen data
Why Naive Bayes for Text?
Before we dive in, why choose Naive Bayes?
- Speed: It's incredibly fast to train, even on large datasets.
- Efficiency: It requires a relatively small amount of training data to produce a decent result.
- Works well with high dimensions: Text classification is a high-dimensional problem (one dimension for every unique word in your vocabulary). Naive Bayes handles this "wide" data gracefully.
It's called "naive" because it makes a "naive" assumption: that the presence of one word in a document is independent of the presence of all other words. While this is obviously false (the word "New" is highly dependent on the word "York"), the model works exceptionally well in practice.
Step 1: Setup and Exploratory Data Analysis (EDA)
Before writing any machine learning code, we must first understand our data. For this project, we'll simulate a movie review dataset with pre-labeled positive (1) and negative (0) reviews.
First, let's get our imports and data ready.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from wordcloud import WordCloud
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn.metrics import (
accuracy_score,
confusion_matrix,
classification_report,
RocCurveDisplay,
PrecisionRecallDisplay
)
# --- Download NLTK assets ---
# (Only need to run this once)
# nltk.download('stopwords')
# nltk.download('wordnet')
# nltk.download('omw-1.4') # For WordNet
# --- 1. Simulate our DataFrame ---
# In a real project, you'd use pd.read_csv() here
data = {
'review': [
"This movie was absolutely fantastic! The acting was superb.",
"I loved this film. The story was compelling and beautiful.",
"A truly great and moving picture. Highly recommend.",
"What a wonderful movie. I'll watch it again.",
"The best film I've seen all year.",
"Completely boring. I fell asleep halfway through.",
"A terrible plot and awful acting. Do not recommend.",
"This was a bad movie. Just plain bad.",
"I hated it. The end was a letdown.",
"The characters were flat and the story was predictable."
],
'sentiment': [1, 1, 1, 1, 1, 0, 0, 0, 0, 0] # 1 = Positive, 0 = Negative
}
df = pd.DataFrame(data)Now, let's explore.
1. Check Class Balance
Is our dataset balanced? An imbalanced dataset (e.g., 90% positive, 10% negative) can mislead our model.
sns.countplot(x='sentiment', data=df)
plt.title('Class Distribution (0=Negative, 1=Positive)')
plt.show()Our tiny dataset is perfectly balanced, which is ideal.
2. Visualize With Word Clouds
Word clouds show the most frequent words for each sentiment.
positive_text = ' '.join(df[df['sentiment'] == 1]['review'])
negative_text = ' '.join(df[df['sentiment'] == 0]['review'])
# Positive Word Cloud
wc_positive = WordCloud(width=800, height=400, background_color='white').generate(positive_text)
plt.figure(figsize=(10, 5))
plt.imshow(wc_positive, interpolation='bilinear')
plt.title('Most Frequent Words in Positive Reviews')
plt.axis('off')
plt.show()Positive reviews are dominated by words like "fantastic," "great," "loved," "superb," and "beautiful."
# Negative Word Cloud
wc_negative = WordCloud(width=800, height=400, background_color='black', colormap='Reds').generate(negative_text)
plt.figure(figsize=(10, 5))
plt.imshow(wc_negative, interpolation='bilinear')
plt.title('Most Frequent Words in Negative Reviews')
plt.axis('off')
plt.show()Negative reviews feature "terrible," "awful," "boring," "bad," and "hated."
3. Analyze Review Lengths
Is there a correlation between the length of a review and its sentiment?
df['review_length'] = df['review'].apply(len)
sns.histplot(data=df, x='review_length', hue='sentiment', multiple='stack', bins=20)
plt.title('Distribution of Review Lengths by Sentiment')
plt.show()In our simple data, there's no clear pattern, but in a larger dataset, you might find (for example) that negative reviews are often shorter and more "to the point."
Step 2: Data Preprocessing — Cleaning Our Text
Raw text is messy. To make it usable, we need to clean it. We'll write a single function to do this.
- Convert to lowercase: Ensures "Movie" and "movie" are treated as the same word.
- Remove punctuation and numbers: These characters generally don't add sentiment value.
- Remove stop words: Eliminate common words like "the," "a," and "is" that don't carry sentiment.
- Lemmatization: Reduce words to their root form (e.g., "running" becomes "run," "was" becomes "be"). This group relates words together.
stop_words = set(stopwords.words('english'))
lemmatizer = WordNetLemmatizer()
def preprocess_text(text):
# 1. Convert to lowercase
text = text.lower()
# 2. Remove punctuation and numbers
text = re.sub(r'[^a-zA-Z\s]', '', text)
# 3. Tokenize (split into words)
words = text.split()
# 4. Remove stop words and lemmatize
words = [lemmatizer.lemmatize(word) for word in words if word not in stop_words]
# 5. Join back into a string
return ' '.join(words)
# Let's see the 'before and after'
print(f"Original: {df['review'][0]}")
print(f"Cleaned: {preprocess_text(df['review'][0])}")
# Apply this function to our entire 'review' column
df['cleaned_review'] = df['review'].apply(preprocess_text)Output:
Original: This movie was absolutely fantastic! The acting was superb.
Cleaned: movie absolutely fantastic acting superbStep 3: Building and Training the Naive Bayes Model
Now we convert the cleaned text into numbers that our model can understand.
Vectorization (TF-IDF)
We'll use TF-IDF (Term Frequency-Inverse Document Frequency).
- Term frequency (TF): How often a word appears in a single document (a review).
- Inverse document frequency (IDF): How rare a word is across all documents.
This technique gives a high score to words that are frequent in one review but rare in all other reviews. This helps the model find unique, sentiment-bearing words.
Using a Pipeline (The Right Way)
The best practice in Scikit-learn is to use a Pipeline. A pipeline chains our steps (vectorizer and model) into one object. This preven
Classification Report and Confusion Matrix
# 1. Define our features (X) and target (y)
X = df['cleaned_review']
y = df['sentiment']
# 2. Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 3. Create the Scikit-learn Pipeline
# This pipeline will:
# 1. Apply TfidfVectorizer
# 2. Train a MultinomialNB model
pipeline = Pipeline([
('tfidf', TfidfVectorizer(max_features=5000, ngram_range=(1, 2))),
('model', MultinomialNB())
])
# 4. Train the model
# We just call .fit() on the pipeline!
pipeline.fit(X_train, y_train)
# 5. Make predictions
y_pred = pipeline.predict(X_test)Step 4: Evaluating Model Performance
How did our model do? We evaluate its predictions on the X_test data.
Classification Report and Confusion Matrix
- Accuracy: Overall percentage of correct predictions. (Use with caution on imbalanced data!)
- Precision: Of all reviews we predicted as positive, how many were positive?
- Recall: Of all actual positive reviews, how many did we find?
- F1-score: The harmonic mean of Precision and Recall. A great all-around metric.
# 1. Accuracy
print(f"Accuracy: {accuracy_score(y_test, y_pred):.2f}")
print("-" * 40)
# 2. Classification Report
print(classification_report(y_test, y_pred))
print("-" * 40)
# 3. Confusion Matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['Predicted Negative', 'Predicted Positive'],
yticklabels=['Actual Negative', 'Actual Positive'])
plt.title('Confusion Matrix')
plt.show()ROC Curve (Receiver Operating Characteristic)
The ROC Curve plots the True Positive Rate against the False Positive Rate.
- A curve in the top-left corner (AUC = 1.0) is a perfect model.
- A diagonal line (AUC = 0.5) is a model that's no better than random guessing.
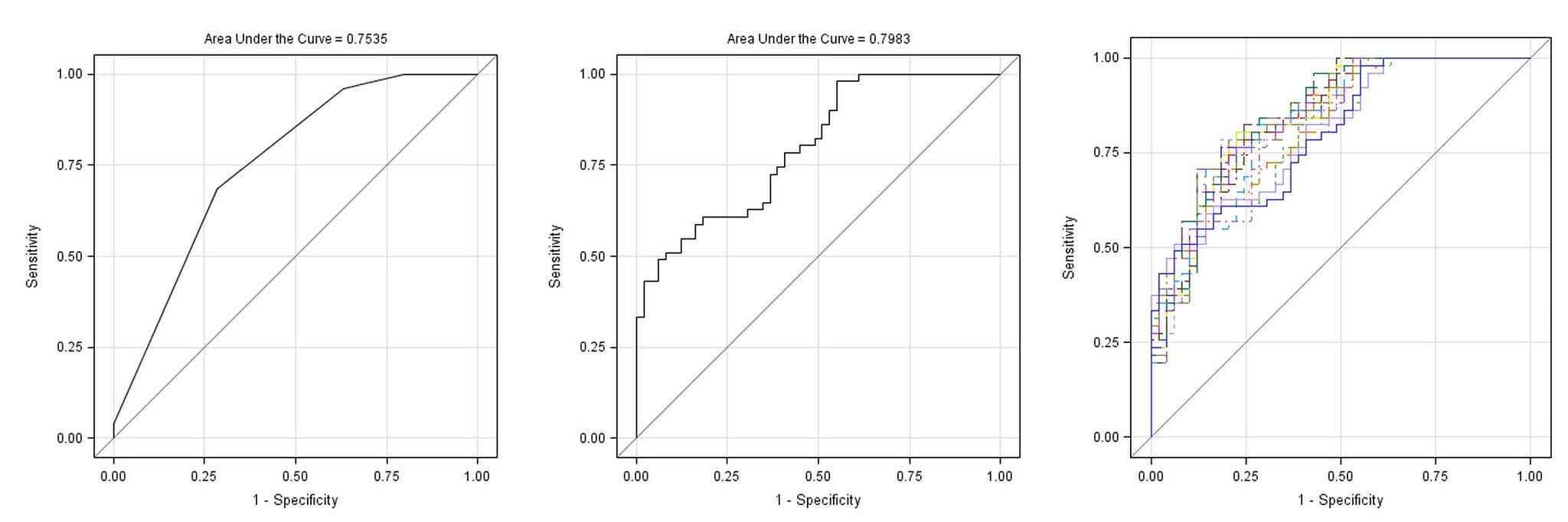
# Plot ROC Curve
RocCurveDisplay.from_estimator(pipeline, X_test, y_test)
plt.title('ROC Curve for Naive Bayes Classifier')
plt.plot([0, 1], [0, 1], 'r--', label='Random Guess')
plt.legend()
plt.show()Precision-Recall Curve
This curve is particularly useful when dealing with imbalanced datasets, as it focuses on the performance of the positive class.
# Plot Precision-Recall Curve
PrecisionRecallDisplay.from_estimator(pipeline, X_test, y_test)
plt.title('Precision-Recall Curve')
plt.show()Step 5: Predicting on New Data
The best part! Let's use our trained pipeline to predict sentiment on new, raw text. The pipeline will automatically apply all the preprocessing steps and the TF-IDF vectorization.
def predict_sentiment(text):
# The pipeline does all the work:
# 1. Preprocesses the text
# 2. TF-IDF vectorizes it
# 3. Predicts
prediction = pipeline.predict([text])[0]
probability = pipeline.predict_proba([text])[0]
if prediction == 1:
return f"Positive (Confidence: {probability[1]:.2f})"
else:
return f"Negative (Confidence: {probability[0]:.2f})"
# Try it out
print(predict_sentiment("This was the best movie I have ever seen!"))
print(predict_sentiment("The acting was stiff and the plot was just awful."))Example output:
Positive (Confidence: 0.95)
Negative (Confidence: 0.99)
Conclusion
We've successfully built an end-to-end sentiment analysis classifier. We started by exploring our text data, then moved on to cleaning the text, building a robust Pipeline, training a Naive Bayes model, and finally, evaluating its performance with industry-standard metrics.
This process provides a solid baseline that can be applied to a wide range of text classification problems. From here, you could experiment with different vectorizers (like CountVectorizer), tune model hyperparameters (like alpha for Naive Bayes), or use this model's performance as a benchmark to see if more complex models (like Logistic Regression or Transformers) provide a significant lift.
Opinions expressed by DZone contributors are their own.
Comments