SRE From Theory to Practice: What's Difficult About On-Call?
A major challenge facing organizations is on-call. Incidents are inevitable in complex systems. Automated incident response can’t handle every problem.
Join the DZone community and get the full member experience.
Join For FreeWe wanted to tackle one of the major challenges facing organizations: on-call. "SRE: From Theory to Practice - What’s Difficult About On-call" sees Blameless engineers Kurt Andersen and Matt Davis joined by Yvonne Lam, staff software engineer at Kong, and Charles Cary, CEO of Shoreline, for a fireside chat about everything on-call.
As software becomes more ubiquitous and necessary in our lives, our standards for reliability grow alongside it. It’s no longer acceptable for an app to go down for days, or even hours. But incidents are inevitable in such complex systems, and automated incident response can’t handle every problem.
This set of expectations and challenges means having engineers on-call and ready to fix problems 24/7 is a standard practice in tech companies. Although necessary, on-call comes with its own set of challenges. Here are the results of a survey we ran asking on-call engineers what they find most difficult about the practice:
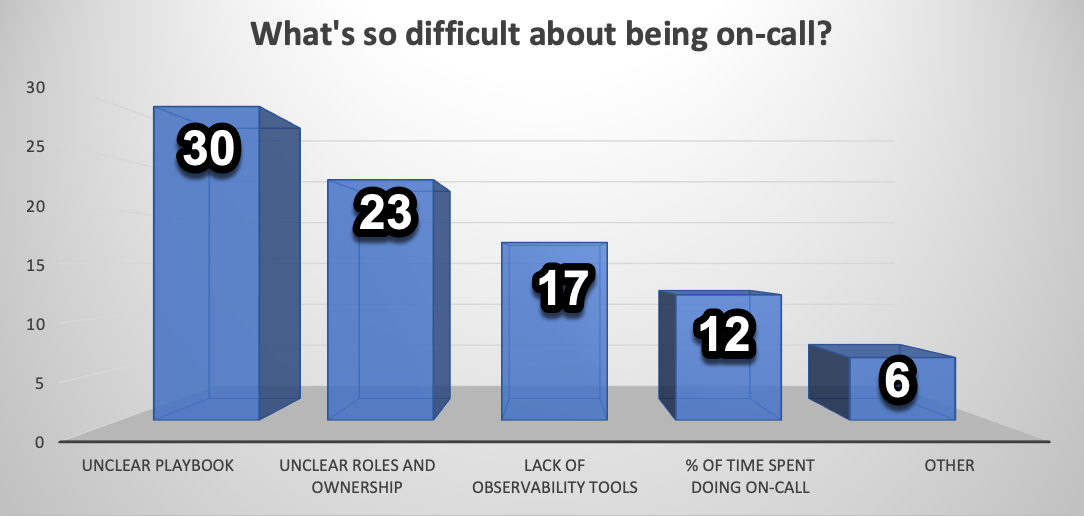
Bar graph showing the biggest difficulties in on-call based on a survey
These results indicate that on-call engineers primarily struggle with the absence of practical resources, like runbooks and role management. However, to solve a practical problem, taking a holistic approach to the systems behind that problem is often necessary.
When we see these challenges in the world of SRE, we want to dive into the challenges behind the challenges, building a holistic approach to improvement. This new webinar series will tackle a different set of challenges in the world of SRE from this perspective. We think that honest and open conversations between experts are an enlightening and empathetic way to improve in these practices.
As the title suggests, this series bridges theoretical discussion of how on-call ought to be with practical implementation advice. If you don’t have the time to watch at the link above, here are three key takeaways. I’ll be continuing a series of wrap-up articles alongside each episode, so you can keep up with the conversation no matter what format you prefer.
Internal On-call Is Just as Important as External
Yvonne works mostly on internal tools for Kong. As a result, the incidents she’s alerted to aren’t the typical ones that directly impact customers, like a service being down. Instead, her on-call shifts are spent fighting fires that prevent teams from integrating and deploying new code. Ultimately, this is just as customer impacting as an outage when teams can’t deploy fixes for outages quickly because of internal tool failure. It can be even worse — if these tools are shared between teams, an internal outage can be totally debilitating.
Yvonne sharing her experiences with these challenges kicked off a discussion of the importance of internal on-call. She discussed how sometimes these internal issues can be uniquely hard to pinpoint. Rather than having a suite of observation tools reporting on the customer experience, internal monitoring is often just engineers vaguely reporting that a tool “seems slow.” Internal issues needed some of the structures that helped with external outages, while also incorporating the unique aspects of dealing with internal issues.
To achieve this mix, it’s important to have some universal standards of impact. SRE advocates tools like SLIs and SLOs to measure incidents in what ultimately matters most: if customers are satisfied with their experience. You can apply this thinking to internal issues too. Think of your engineers as “internal customers” and build their “user journeys” in terms of what tools they rely on, the impact of those tools failing on deploying code, and so on. This will help you build internal on-call systems that reflect the importance of internal system reliability, alongside the resources to support it, like runbooks. Investing in these resources strategically requires understanding the positive impact they’d have.
Think of your engineers as “internal customers” and build their “user journeys” in terms of what tools they rely on, the impact of those tools failing on deploying code, and so on.
Assessing Customer Impact Is Hard to Learn
We’ve discussed the importance of a universal language that reflects customer happiness, but how do you learn that language? Charles discussed the challenge in building up this intuition. Customer impact is a complex metric with many factors — how much the incident affects a service, how necessary that service is to customer experiences, how many customers use that service, how important those customers are in terms of business… the list goes on.
Incident classification systems and SLO impact can help a lot in judging incident severity, but there will always be incidents that fall outside of expectations and patterns. All of our participants related to experiences where they just “knew” that an incident was a bigger deal than the metrics said. Likewise, they could remember times that following the recommended runbook for an incident to a tee would have caused further issues. Charles gave an example of knowing that restarting a service, although potentially a fix for the incident, could also cause data loss, and needing to assess the risk and reward.
Ultimately, the group agreed that some things can’t be taught directly, but have to be built from experience — working on-call shifts and learning from more experienced engineers. The most important lesson: when you don’t know what to do and the runbook is unclear, get help! We often think of incident severity as what dictates how you escalate, but what if you don’t know the severity? Matt emphasized the importance of having a psychologically safe space, where people feel comfortable alerting other people whenever they feel unsure. Escalation shouldn’t feel like giving up on the problem, but a tool that helps provide the most effective solution.
The group discussed some of the nuances of escalation. Escalation shouldn’t be thought of as a linear hierarchy, but a process where the best person for a task is called in. Find the people who are just “one hop away” from you, where you can call them in to handle something you don’t have the capacity for. Incident management is a complex process with many different roles and duties; you shouldn’t need to handle everything on your own. The person you call won’t always be the person who's the most expert in the subject area. Sometimes someone you have a personal relationship with, like a mentor, will be the most useful to call upon. The social dynamics we all have as humans can’t be ignored in situations like on-call, and can even be a strength.
Escalation shouldn’t feel like giving up on the problem, but a tool that helps provide the most effective solution.
Lower the Cost of Being Wrong
Social dynamics come into play a lot with on-call. As we discussed, there can be a lot of hesitation when it comes to escalating. People naturally want to be the one that solves the problem, the hero. They might see escalating as akin to admitting defeat. If they escalate to an expert, they might feel embarrassed that the expert will judge their efforts so far as being “wrong,” and might defer escalating to avoid that feeling of wrongness.
To counteract this, Yvonne summarized wonderfully: “you have to lower the cost of being wrong.” Promote a blameless culture, where everyone’s best intentions are assumed. This will make people feel safe from judgment when escalating or experimenting. Matt focused on the idea of incidents as learning opportunities, unique chances to see the faults in the inner workings of your system. The more people fear being wrong, the more they pass up exploring this opportunity and finding valuable insights.
The fear of being wrong can also lead to what Kurt described as “the mean time to innocence factor” — when an incident occurs, each team races to prove that they weren’t at fault and bear no responsibility for solving the problem. Escaping the challenge of solving the problem is a very understandable human desire, but this game of incident hot potato needs to be avoided. Again, lower the cost of being wrong to keep people at the table: it doesn’t matter if your code caused the crash, what matters is that the service is restored and a lesson is learned.
The group also discussed getting more developers and other stakeholders to work on-call for their own projects. Development choices will always have some ramifications that you can’t really understand until you experience them firsthand. Developer on-call builds this understanding and empathy between developers and operations teams. Once again, lowering the cost of being wrong makes on-call more approachable. It shouldn’t be a dreadful, intimidating experience, but a chance to learn and grow, something to be embraced.
The more people fear being wrong, the more they pass up exploring this opportunity and finding valuable insights.
We hope you enjoyed the first episode of "SRE: From Theory to Practice." Please look forward to more episodes dealing with other challenges in SRE, and the challenges behind the challenges.
Published at DZone with permission of Emily Arnott. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments