Stateful Streaming in Spark
In this article, see how to do stateful streaming in Spark using Spark-DStream. This shows how to use mapWithState and updateStateByKey.
Join the DZone community and get the full member experience.
Join For FreeApache Spark is a fast and general-purpose cluster computing system. In Spark, we can do the batch processing and stream processing as well. It does near real-time processing. It means that it processes the data in micro-batches. I have discussed more Spark Streaming in my previous blog. Now in this blog, I'll discuss Stateful Streaming in Spark. So let's start !!
What Is Stateful Streaming?
Stateful stream processing means that a "state" is shared between events and therefore past events can influence the way current events are processed.
In simple words, we can say that in Stateful Streaming the processing of the current data/batch is dependent on the data/batch that has been processed already.
To understand it more, let's discuss a scenario. You want to find out the total occurrences of each word that has been received by the processor till now. Here is the spark streaming application for the above functioning. Now consider, first, it receives data as follows :

and then we get the following output:
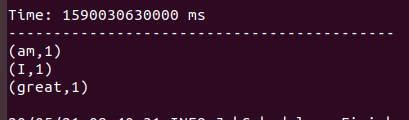
Now, while it was processing I sent the above data again. Now you must be expecting that the count of "I", "am" and "great" should be 2, 2 and 2 respectively. But I still got the following output:
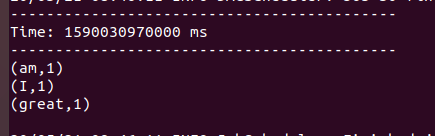
So, are you wondering why this? This is because the stream processing is stateless right now i.e processing of current batch is independent of the batch that has been processed already.
In the above scenario, you need to check the previous state of the to update te new state of the RDD. This is what is known as stateful streaming in Spark.
Now to get our expected result we will move to stateful streaming.
How to do Stateful Processing in Spark?
To do stateful streaming in Spark we can use updateStateByKey or mapWithState. I'm going to discuss both of them here.
updateStateByKey
The updateStateByKey operation allows you to maintain an arbitrary state while continuously updating it with new information.
To use this, you will have to do two steps :
- Define the state: The state can be an arbitrary data type.
- Define the state update function: In this function, you have to specify how to update the state with the previous state and the new value received from the stream.
In every batch, Spark will apply the state update function for all existing keys, regardless of whether they have new data in a batch or not. If the update function returns None then the key-value pair will be eliminated.
Look at the following example to see how to use updateStateByKey:
Now, if I send the following data:

the output will be the following:
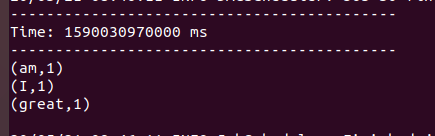
And on sending the same data again the word count will be the following:
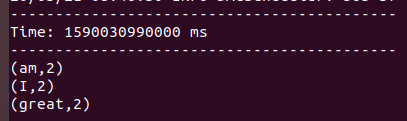
Now, it works as per our expectations.
mapWithState
The mapWithState operation takes an instance of StateSpec and uses its factory method StateSpec.function() for setting all the specification of mapWithState. StateSpec.function takes a mapping function as a parameter. So you will have to define a mapping function in your code.
Look at the following example to understand how to use mapWithState:
Checkpointing
To provide fault tolerance we use Checkpointing. In this basically, the intermediate values are stored in a storage, preferably fault-tolerant storage such as HDFS. In stateful streaming, it is compulsory to do checkpointing with the streaming context, so that if needed the state can be restored.
That's all in this blog about Stateful Streaming in Spark. You can look for the examples here. I hope it was helpful.
Published at DZone with permission of Muskan Gupta. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments