How to Synchronize Blocks by the Value of the Object in Java
Ever had trouble synchronizing blocks of code?
Join the DZone community and get the full member experience.
Join For Freethe problem
sometimes, we need to synchronize blocks of code by the value of a variable.
in order to understand this problem, we will consider a simple banking application that makes the following operations on each transfer of money by the client:
-
evaluates the amount of the cash back by this transfer from external web service (
cashbackservice) -
performs a money transfer in the database (
accountservice) -
updates the data in the cash-back evaluation system (
cashbackservice)
the money transfer operation looks like this:
public void withdrawmoney(uuid userid, int amountofmoney) {
synchronized (userid) {
result result = externalcashbackservice.evaluatecashback(userid, amountofmoney);
accountservice.transfer(userid, amountofmoney + result.getcashbackamount());
externalcashbackservice.cashbackcomplete(userid, result.getcashbackamount());
}
}
the base components of the application are shown in the following diagram:
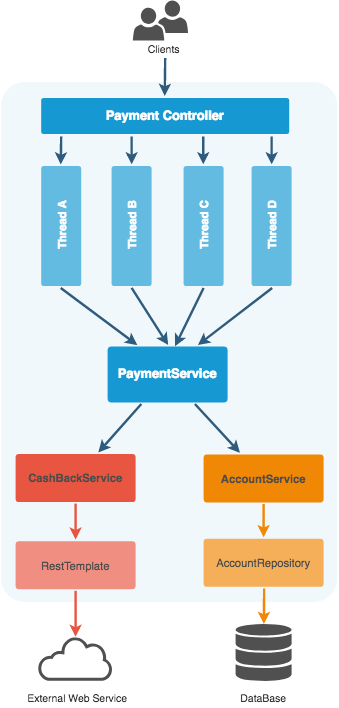
i tried to make an example as clear as possible. the transfer of money in the payment service depends on the other two services:
-
the first one is a
cashbackservicethat interacts with another (external) web application under the rest protocol. and, in order to calculate the actual cash-back, we need to synchronize transactions with this application. this is because the next amount of the cash-back may depend on the total amount of user payments. -
the second is an
accountservicethat communicates with an internal database and stores data related to accounts of its users. in this service, we can use a jpa transaction to make some actions as atomic operations in the database.
in a real life, i’d strongly recommend refactoring such systems to avoid this situation, if possible. but in our example, imagine that we have no choice.
let’s look at the draft code of this application:
@service
public class paymentservice {
@autowired
private externalcashbackservice externalcashbackservice;
@autowired
private accountservice accountservice;
public void withdrawmoney(uuid userid, int amountofmoney) {
synchronized (userid) {
result result = externalcashbackservice.evaluatecashback(userid, amountofmoney);
accountservice.transfer(userid, amountofmoney + result.getcashbackamount());
externalcashbackservice.cashbackcomplete(userid, result.getcashbackamount());
}
}
}
@service
public class externalcashbackservice {
@autowired
private resttemplate resttemplate;
public result evaluatecashback(uuid userid, int amountofmoney) {
return sendrestrequest("evaluate", userid, amountofmoney);
}
public result cashbackcomplete(uuid userid, int cashbackamount) {
return sendrestrequest("complete", userid, cashbackamount);
}
private result sendrestrequest(string action, uuid userid, int value) {
uri externalcashbacksystemurl =
uri.create("http://cash-back-system.org/api/" + action);
httpheaders headers = new httpheaders();
headers.set("accept", mediatype.application_json_value);
requestdto requestdto = new requestdto(userid, value);
httpentity<?> request = new httpentity<>(requestdto, headers);
responsedto responsedto = resttemplate.exchange(externalcashbacksystemurl,
httpmethod.get,
request,
responsedto.class)
.getbody();
return new result(responsedto.getstatus(), responsedto.getvalue());
}
}
@service
public class accountservice {
@autowired
private accountrepository accountrepository;
@transactional(isolation = repeatable_read)
public void transfer(uuid userid, int amountofmoney) {
account account = accountrepository.getone(userid);
account.setbalance(account.getbalance() - amountofmoney);
accountrepository.save(account);
}
}
however, you can have several objects with the same value (
userid
in this example), but the synchronization works on the instance of the object and not on its value.
the code below does not work well. because it’s incorrectly synchronized; the static factory method
uuid.fromstring(..)
makes a new instance of the uuid class on each call, even if you pass an equal string argument.
so, we get different instances of the
uuid
for equal keys. if we run this code from multiple threads, then we have a good chance to get a problem with synchronization:
public void threada() {
paymentservice.withdrawmoney(uuid.fromstring("ea051187-bb4b-4b07-9150-700000000000"), 1000);
}
public void threadb() {
paymentservice.withdrawmoney(uuid.fromstring("ea051187-bb4b-4b07-9150-700000000000"), 5000);
}
in this case, you need to obtain the same reference for equals objects to synchronize on it.
wrong ways to solve this issue
synchronized methods
you can move the
synchronized
on a method:
public synchronized void withdrawmoney(uuid userid, int amountofmoney) {
..
}
this solution has a bad performance. you will block transfers of money for absolutely all users. and if you need to synchronize different operations in the different classes by the same key, this solution does not help you at all.
string intern
in order to ensure that the instance of the class, which contains a user id, will be the same in all synchronized blocks, we can serialize it into a string and use the
string.intern()
to obtain the same link for equals strings.
string.intern
uses a global pool to store strings that are interned. and when you request intern on the string, you get a reference from this pool if such string exists there or else this string puts in the pool.
you can find more details about
string.intern
in
the java language specification - 3.10.5 string literals
or in the oracle java documentation about the
string.intern
public void withdrawmoney(uuid userid, int amountofmoney) {
synchronized (userid.tostring().intern()) {
..
}
}
using the intern is not a good practice because the pool of strings is difficult to clean with the gc. and, your application can consume too many resources with the active use of the
string.intern
.
also, there is a chance that a foreign code is synchronized on the same instance of the string as your application. this can lead to deadlocks.
in general, the use of intern is better left to the internal libraries of the jdk; there are good articles by aleksey shipilev about this concept.
how can we solve this problem correctly?
create your own synchronization primitive
we need to implement a behavior that describes the next diagram:

at first, we need to make a new synchronization primitive — the custom mutex. that will work by the value of the variable, and not by the reference to the object.
it will be something like a "named mutex , " but a little wider, with the ability to use the value of any objects for identification, not just the value of a string. you can find examples of synchronization primitives to locking by the name in other languages (c++, c#). now, we will solve this issue in java.
the solution will look something like this:
public void withdrawmoney(uuid userid, int amountofmoney) {
synchronized (xmutex.of(userid)) {
..
}
}
in order to ensure that the same mutexes are obtained for equal values of variables, we will make the mutex factory.
public void withdrawmoney(uuid userid, int amountofmoney) {
synchronized (xmutexfactory.get(userid)) {
..
}
}
public void purchase(uuid userid, int amountofmoney, vendordescription vendor) {
synchronized (xmutexfactory.get(userid)) {
..
}
}
in order to return the same instance of mutex on the each of requests with equal keys, we will need to store the created mutexes. if we will store these mutexes in the simple
hashmap
, then the size of the map will increase as new keys appear. and we don’t have a tool to evaluate a time when a mutex not used anywhere.
in this case, we can use the
weakreference
to save a reference to the mutex in the map, just when it uses. in order to implement this behavior, we can use the
weakhashmap
data structure. i wrote an article about this type of references a couple of months ago; you can consider it in more details here:
soft, weak, phantom references in java
our mutex factory will be based on the
weakhashmap
. the mutex factory creates a new mutex if the mutex for this
value(key)
is not found in the
hashmap
. then, the created mutex is added to the
hashmap
. using of the
weakhashmap
allows us to store a mutex in the
hashmap
while existing any references to it. and, the mutex will be removed from a
hashmap
automatically when all references to it are released.
we need to use a synchronized version of
weakhashmap
; let’s see what’s described in the
documentation
about it:
this class is not synchronized. a synchronized weakhashmap may be constructed
using the collections.synchronizedmap method.
it’s very sad, and a little later, we’ll take a closer look at the reason. but for now, let’s consider an example of implementation, which is proposed by the official documentation (i mean the use of
collections.synchronizedmap
):
public final map<xmutex<keyt>, weakreference<xmutex<keyt>>> weakhashmap =
collections.synchronizedmap(new weakhashmap<xmutex<keyt>,
weakreference<xmutex<keyt>>>());
public xmutex<keyt> getmutex(keyt key) {
validatekey(key);
return getexist(key)
.orelseget(() -> savenewreference(key));
}
private optional<xmutex<keyt>> getexist(keyt key) {
return optional.ofnullable(weakhashmap.get(xmutex.of(key)))
.map(weakreference::get);
}
private xmutex<keyt> savenewreference(keyt key) {
xmutex<keyt> mutex = xmutex.of(key);
weakreference<xmutex<keyt>> res = weakhashmap.put(mutex, new weakreference<>(mutex));
if (res != null && res.get() != null) {
return res.get();
}
return mutex;
}
what about performance?
if we look at the code of the
collections.synchronizedmap
, then we find a lot of synchronizations on the global mutex, which is created in pair with a
synchronizedmap
instance.
synchronizedmap(map<k,v> m) {
this.m = objects.requirenonnull(m);
mutex = this;
}
and all other methods of the
synchronizedmap
are synchronized on mutex:
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean containskey(object key) {
synchronized (mutex) {return m.containskey(key);}
}
public v get(object key) {
synchronized (mutex) {return m.get(key);}
}
public v put(k key, v value) {
synchronized (mutex) {return m.put(key, value);}
}
public v remove(object key) {
synchronized (mutex) {return m.remove(key);}
}
...
this solution does not have the best performance. all of these synchronizations lead us to permanent locks on each operation with a factory of mutexes.
concurrenthashmap with a weakreference as a key
we need to look at the using of the
concurrenthashmap
. it has a better performance than collections.synchronizedmap. but we have one problem — the
concurrenthashmap
doesn’t allow the use of weak references. this means that the garbage collector cannot delete unused mutexes.
i found two ways to solve this problem:
-
the first is to create my own
concurrentmapimplementation. this is the right decision, but it will take a very long time. -
the second one is the use of the
concurrentreferencehashmapimplementation from the spring framework. this is a good implementation, but it has a couple of nuances. we will consider them below.
let’s change the
xmutexfactory
implementation to use a
concurrentreferencehashmap
:
public class xmutexfactory<keyt> {
/**
* create mutex factory with default settings
*/
public xmutexfactory() {
this.map = new concurrentreferencehashmap<>(default_initial_capacity,
default_load_factor,
default_concurrency_level,
default_reference_type);
}
/**
* creates and returns a mutex by the key.
* if the mutex for this key already exists in the weak-map,
* then returns the same reference of the mutex.
*/
public xmutex<keyt> getmutex(keyt key) {
return this.map.compute(key, (k, v) -> (v == null) ? new xmutex<>(k) : v);
}
}
that’s cool!
less code, but more performance than before. let’s try to check the performance of this solution.
create a simple benchmark
i made a small benchmark in order to select an implementation.
there are three implementations of the
map
involved in the test:
-
collections.synchronizedmapbased on theweakhashmap -
concurrenthashmap
-
concurrentreferencehashmap
i use the
concurrenthashmap
in benchmark just for comparing in measurements. this implementation is not suitable for use in the factory of mutexes because it does not support the use of weak or soft references.
all benchmarks are written with using the jmh library.
# run complete. total time: 00:04:39
benchmark mode cnt score error units
concurrentmap.concurrenthashmap thrpt 5 0,015 ? 0,004 ops/ns
concurrentmap.concurrentreferencehashmap thrpt 5 0,008 ? 0,001 ops/ns
concurrentmap.synchronizedmap thrpt 5 0,005 ? 0,001 ops/ns
concurrentmap.concurrenthashmap avgt 5 565,515 ? 23,638 ns/op
concurrentmap.concurrentreferencehashmap avgt 5 1098,939 ? 28,828 ns/op
concurrentmap.synchronizedmap avgt 5 1503,593 ? 150,552 ns/op
concurrentmap.concurrenthashmap sample 301796 663,330 ? 11,708 ns/op
concurrentmap.concurrentreferencehashmap sample 180062 1110,882 ? 6,928 ns/op
concurrentmap.synchronizedmap sample 136290 1465,543 ? 5,150 ns/op
concurrentmap.concurrenthashmap ss 5 336419,150 ? 617549,053 ns/op
concurrentmap.concurrentreferencehashmap ss 5 922844,750 ? 468380,489 ns/op
concurrentmap.synchronizedmap ss 5 1199159,700 ? 4339391,394 ns/op
in this micro-benchmark, i create a situation when several threads compute values in the map. you can consider the source code of this benchmark in more details here at concurrent map benchmark
put it on the graph:

so, the
concurrentreferencehashmap
justifies its use in this case.
getting started with the xsync library
i packed this code into the xsync library, and you can use it as a ready solution for the synchronization on the value of variables.
in order to do it, you need to add the next dependency:
<dependency>
<groupid>com.antkorwin</groupid>
<artifactid>xsync</artifactid>
<version>1.1</version>
</dependency>
then, you are able to create instances of the xsync class for synchronization on types that you need. for the spring framework, you can make them as beans:
@bean
public xsync<uuid> xsync(){
return new xsync<>();
}
and now, you can use it:
@autowired
private xsync<uuid> xsync;
public void withdrawmoney(uuid userid, int amountofmoney) {
xsync.execute(userid, () -> {
result result = externalpolicysystem.validatetransfer(userid, amountofmoney, withdraw);
accountservice.transfer(userid, amountofmoney, withdraw);
});
}
public void purchase(uuid userid, int amountofmoney, vendordescription vendor) {
xsync.execute(userid, () -> {
..
});
}
concurrent tests
in order to be sure that this code works well, i wrote several concurrent tests.
there is an example of one of these tests:
public void testsyncbysinglekeyinconcurrency() {
// arrange
xsync<uuid> xsync = new xsync<>();
string id = uuid.randomuuid().tostring();
nonatomicint var = new nonatomicint(0);
// there is a magic here:
// we created a parallel stream and try to increment
// the same nonatomic integer variable in each stream
intstream.range(0, thread_cnt)
.boxed()
.parallel()
.foreach(j -> xsync.execute(uuid.fromstring(id), var::increment));
// asserts
await().atmost(5, timeunit.seconds)
.until(var::getvalue, equalto(thread_cnt));
assertions.assertthat(var.getvalue()).isequalto(thread_cnt);
}
/**
* implementation of the does not thread safe integer variable:
*/
@getter
@allargsconstructor
private class nonatomicint {
private int value;
public int increment() {
return value++;
}
}
let’s see the result of this test:

references
xsync library on github: https://github.com/antkorwin/xsync
examples using the xsync library: https://github.com/antkorwin/xsync-example
the original article can be found here .
Published at DZone with permission of Anatoliy Korovin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments