The Backend Revolution and Why io_uring Is So Important
Developers who have noticed the rapid development of io_uring may be wondering why it's so important, and how we are seeing the start of a backend revolution.
Join the DZone community and get the full member experience.
Join For FreeNot so many backend (and application in general) developers are watching the development of Linux kernel. But those who do notice the appearance and rapid development of io_uring. For those who are not aware of what it is, I'll provide a brief introduction below. But the main topic of this post is not the io_uring itself. Instead, I want to show you that we are watching the beginning of the real revolution in backend development.
I/O Anatomy of the Backend
As I've explained in the article dedicated to Data Dependency Graph, each backend application at a very high level has only three parts - set of inputs, set of outputs, and set of transformations from inputs to outputs.
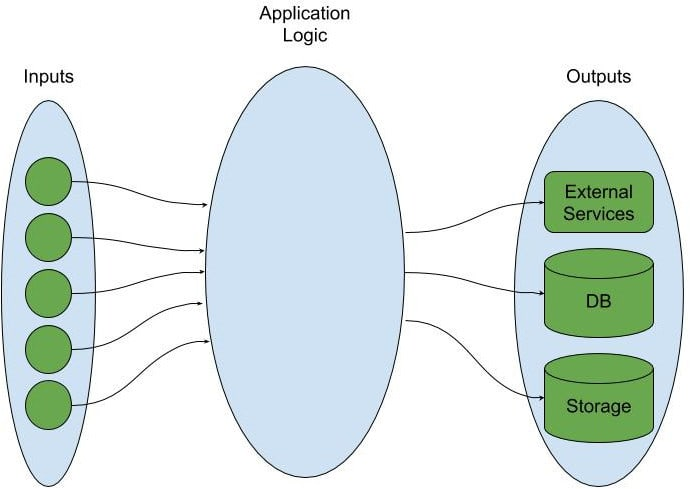
This is a rather logical view since it presents the logical meaning of inputs and outputs from the point of view of the architecture of the application. In other words, it preserves inputs and outputs as we see them while designing and implementing the application. Nevertheless, if we look at the same application from the low level I/O perspective, we quickly realize that every input, output, or internal communication (calls to other services located outside our application) consists of both, input and output. How does this happen?
Let's take a look at it. For example, the REST entry point receives the request from the client (input part), processes it, and sends a response (output part). The same is true for every other point where we are interacting with the world outside the application.
Let's try to draw a diagram with I/O which happens during the processing of a request of the very simple REST entry point. This entry point prepares arguments from the incoming requests, calls external service, formats responses, and sends it back. All I/O inputs (i.e. where data received) I'll keep pointing to left and all I/O outputs (i.e. where data sent) will point to right:

Vertical lines depict the interaction between application and external world, i.e. I/O operations.
Now let's ignore for the moment that all steps in this diagram logically belong to the same request and focus only on the I/O:
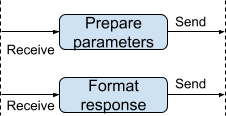
Some important observations:
- From the point of view of I/O, the application has many more inputs and outputs that we usually take into account at a logical level.
- The whole application is an asynchronous system driven by I/O events.
- At such a low-level, the structure of the application remains exactly the same - set of inputs, set of outputs, and set of transformations between them. But this time we have completely different sets of inputs, outputs, and transformations.
While in this very simple example we have only one input for every transformation, in more complex cases outputs may depend on more than one input. Also, usually, there is some kind of context which is passed across all transformations related to the same logical processing pipeline. For example, in the REST application, there are request and response contexts (often combined into one) which form the context passed through all processing steps of the same entry point.
I want to emphasize: all backend applications have an identical structure shown above. The internal architecture and software stack used for implementation is irrelevant. Old-fashioned Java monolith and fancy serverless functions have the same structure from point of view of I/O.
Few Words About Transformations
At first look transformations at the diagrams above should be functions. After all, they take some parameters (input data + context) and produce some output (which is then sent). But such a function is only part of the transformation. There is a very important stage - synchronization. It often overlooked (especially if we're dealing with synchronous code), but it's very important since it directly affects application performance characteristics (see below). The purpose of the synchronization stage is to collect all necessary parameters and then pass them to transformation function. So, the whole transformation contains two parts - the synchronization stage followed by transformation function.
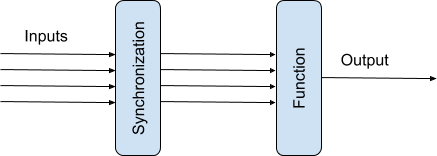
The synchronization part is one of two types - All and Any. The article dedicated to Data Dependency Graph explains these in more detail.
I/O and Application Performance
The look at the application as a set of Input-Transformation-Output elements is a crucial step for understanding application performance bottlenecks. There are only three factors which affect application performance:
- Input throughput
- Output throughput
- Transformation throughput
Let's start from the last item: transformation throughput. This part depends on several factors - overhead introduced by underlying software stack, for example. It also depends on the complexity of performed transformations. Some applications are computationally intensive (for example, blockchain and AI apps). Nevertheless, most backend applications have no significant computational load, and transformation throughput is limited by other factors:
- Overhead introduced by the software stack
- Overhead introduced by synchronous processing
The last item appears in traditional synchronous applications when they create and maintain a large number of threads, the vast majority of which just waits for the I/O.
OK, how about Input and Output? Well, they have their own (big) set of issues. First of all, the vast majority of traditional APIs provided by operating systems are synchronous. There are some exceptions but they cover only subsets of necessary functionality (usually network). The next issue is that every I/O operation means context switch. We prepare parameters and perform the call to the operating system (OS). At this point OS needs to save the whole context, switch to internal OS stack, copy (if necessary) data between user space and kernel space, perform requested operation, and upon completion perform the same steps in reverse order. Besides that, every context switch is a huge stress to CPU pipelines which heavily impacts performance.
Let's summarize: how the application looks and behaves from the point of view of I/O is completely different from how we ought to implement our applications.
New Era of I/O With io_uring
The io_uring is a completely new approach to I/O API.
First of all, the API is consistent across all types of I/O. Network and file I/O handled consistently.
Next, the API is asynchronous. The application submits requests and then is notified when the request is completed. This API naturally implements the so-called Proactor pattern. While far less famous than the Reactor pattern, Proactor is a better fit for pure asynchronous API.
The io_uring API uses two ring buffers for communication between application and kernel (hence the API name) and designed in a way that enables natural batching of requests and responses. Besides other consequences (see below), this means that number of context switches is significantly reduced. There is no correspondence One I/O = One syscall = Two context switches anymore.
Finally, io_uring can be configured (although this requires root privileges) to perform I/O without calling OS at all (to be precise - don't call OS as long as there is a stable stream of I/O operations).
There are several other useful features, for example, it's possible to pre-configure memory buffers for I/O so they will be directly accessible for application and kernel, so it is possible to perform I/O without copying any data (nor even remapping memory).
Ideal Backend Application
Well, there are no ideal applications. Nevertheless, I propose to call Ideal Backend Application any backend application which can saturate Input at given hardware (i.e. reach hardware+OS limits). This is not so easy to achieve. In fact, before io_uring was introduced, it was almost impossible for a traditional user-level application to reach I/O limits.
Now, with io_uring this is possible, but why this is important and why such an application is ideal?
The main property of such an application: it's impossible to overload it!
The whole range of loads, from zero to saturated Input is a normal operating range for such an application. Just imagine no performance degradation, no excessive memory (or other resources) consumption, and no relevant failures. Such an application is always stable and reliable, its ideal from maintenance and support points of view.
Are We Ready for This Revolution?
Well, we definitely have close to zero support for io_uring in popular stacks used for backend. Unfortunately, many of them are not designed to accommodate such an I/O model easily. Worse is that many frameworks support or promote a synchronous processing model. Adding io_uring support in such frameworks will provide no sensible benefits.
The good news is that virtually any stack which uses a promise-based asynchronous processing model will get a significant performance boost since this model is very close to io_uring API and how the application looks from the point of view of I/O.
Conclusion
We're facing revolutionary change in the backend development. And to get the most benefits from this change we need to adopt asynchronous processing and at least some functional programming approaches. This combination provides minimal "abstraction overhead" and allows us to get the most out of the hardware. Some software stacks are already adopted this model (for example, Node and Deno) and show quite good performance despite far from the best possible performance of JS and single-threaded design.
Published at DZone with permission of Sergiy Yevtushenko. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments