The End of Data Refactoring?
For “extract/transform/load,” are you transforming your application’s data for the purposes of your applications or the requirements of your database?
Join the DZone community and get the full member experience.
Join For FreeIn a former project, I remember going through requirements meetings, hashing out a data model, drawing up a database design, and submitting it to a DBA team for review and approval. There were numerous back-and-forth communications on naming, data types, and structure conventions. Weeks later, the tables were created in the development environment, so that I could ingest test data and build and test the code against it.
When requirements changed, understanding of the data model improved, test data iterations produced different results, or scope creeped in the project, we would start the data model -> database design -> DBA review/approval -> development creation process all over again.
This project is not the only one of its kind. There are a substantial number of project hours burned during each iteration of development, production, as well as maintenance/enhancement projects. By reducing or eliminating the translation step between a data model and database design, we can dramatically improve time-to-market and maintenance costs down the road.
What Is Data Refactoring?
The roots of data refactoring likely point back to code refactoring applied to computer programs. Martin Fowler defines refactoring as “a disciplined technique for restructuring an existing body of code, altering its internal structure without changing its external behavior.” There are entire books written on this topic, but how does this apply to data and databases?
Code refactoring is often done after an initial draft of code or when improvements/features need to be made. Any of these changes can impact a project before or after initial implementation to make code cleaner, more efficient, and more maintainable. Some refactorings might also occur because of changes to the data structure supporting the code, such as due to a deeper understanding of the data model or additions/subtractions to the collected data itself. Refactoring happens in the data and data model, too.
Notice that while code refactoring can occur without changes to the data model, code is nearly always impacted by changes to the underlying data model. Data refactoring becomes the source of refactors for the model, storage system, and code. Each piece needs careful planning and thorough understanding, which adds considerable project resources.
We see positive benefits from refactoring through better data and code, so isn’t the time spent well worth it? What’s the trouble?
Looking at the data refactoring component of a project, there are several tasks that accompany it. The first is making changes to the data model to fit the new case, feature, etc. The second is to align the data model with the storage technology’s format, i.e. relational, graph, or other. Each type of data storage format comes with its own set of rules, so we often end up making further changes to the data to accommodate the required structure.
This “translation” step between the data model and data storage steps is what can be cumbersome, accompanied by approvals to properly align data structures between the real-world and structured formats in a database. Graph databases can shorten or cut the translation phase because they more naturally model data as it exists in the real world.
Data Refactoring for Databases
In a previous article, we utilized a coffee shop data set with sales receipts, products, and customers. We can use the same data set to look at data refactoring today, but take a different section of the data — stores and their staff assignments. All of the data, change scripts, and more are available in the related Github repository.
Our example data set is in Tables 1 and 2 below.
sales_outlet_id |
sales_outlet_type |
store_square_feet |
store_address |
store_city |
store_state_province |
store_telephone |
store_postal_code |
manager |
1 |
headquarters |
0 |
unknown |
New York |
NY |
111-222-3333 |
44444 |
2 |
2 |
warehouse |
3400 |
164-14 Jamaica Ave |
Jamaica |
NY |
972-871-0402 |
11432 |
1 |
3 |
retail |
1300 |
32-20 Broadway |
Long Island City |
NY |
777-718-3190 |
11106 |
6 |
Table 1. The shop location table
staff_id |
first_name |
last_name |
position |
start_date |
location |
1 |
Sue |
Tindale |
CFO |
8/3/2001 |
1 |
2 |
Ian |
Tindale |
CEO |
8/3/2001 |
1 |
3 |
Marny |
Hermione |
Roaster |
10/24/2007 |
2 |
4 |
Chelsea |
Claudia |
Roaster |
7/3/2003 |
2 |
5 |
Alec |
Isadora |
Roaster |
4/2/2008 |
2 |
6 |
Xena |
Rahim |
Store Manager |
7/24/2016 |
3 |
7 |
Kelsey |
Cameron |
Coffee Wrangler |
10/18/2003 |
3 |
8 |
Hamilton |
Emi |
Coffee Wrangler |
2/9/2005 |
3 |
9 |
Caldwell |
Veda |
Coffee Wrangler |
9/9/2013 |
3 |
10 |
Ima |
Winifred |
Coffee Wrangler |
12/10/2016 |
3 |
Table 2. The staff table
Shop locations include data about the location type, size, address details, phone number, and assigned manager. The staff table contains names, positions, start dates, and assigned shop locations for each associate.
A graph representation of this data could look something like we see below.

Figure 1: Graph representation of shop locations and staff
In the graph model, we have two main entities (nodes: Shop and Staff. The relationships between these nodes tell us how they are connected. Either a staff member is assigned to work at a location or a shop is managed by a particular staff member.
Next, let’s take a look at how a few specific refactorings would impact each of these models.
Refactoring 1: Adding a New Column
Storing additional data is a common change in projects. In our coffee shop case, we might want to also track the open date for a shop location (i.e. how long a location has been in operation).
In a relational format, the process would be to add a new column to the table. This likely means explaining the change to stakeholders, writing and executing a Data Definition Language (DDL) statement to alter the table structure (or dropping the entire table and rebuilding it with the new column in the DDL), adding the new data to the population set, then importing the actual data to the table. It may also require change approval steps added between certain tasks. This change does not impact the staff table, so no changes are required there.
sales_outlet_id |
sales_outlet_type |
store_open_date |
store_square_feet |
store_address |
store_city |
store_state_province |
store_telephone |
store_postal_code |
manager |
1 |
headquarters |
8/1/2016 |
0 |
na |
New York |
NY |
111-222-3333 |
44444 |
2 |
2 |
warehouse |
7/3/2003 |
3400 |
164-14 Jamaica Ave |
Jamaica |
NY |
972-871-0402 |
11432 |
1 |
3 |
retail |
8/3/2001 |
1300 |
32-20 Broadway |
Long Island City |
NY |
777-718-3190 |
11106 |
6 |
Table 3. Refactor #1 for shop location table
In a graph format, we would need to add a new property to the Shop node. Similar to our relational process above, we would need to explain the change to stakeholders and get any necessary change approvals. However, dropping the data structure, making the addition, and setting the new data structure is all eliminated in a graph because there is no strict DDL. The structure is not forced on the data — rather, the data itself determines the structure and can be adapted when data shifts.

Figure 2. Refactor #1 for graph
Example scripts for both relational and graph processes are included in the code repository on GitHub.
Refactoring 2: Adding a New Table and Relationship
Next, perhaps we have issues with staffing coverage at our locations, so we want to retain employee addresses to help us determine who might be able to cover a shift at another location.
While we could store employee addresses directly in the Staff table, addresses are more likely to change than other data, and we might want to keep staff personal details separate from their business information. We can create a separate table to store addresses, which means creating a foreign key relationship between the staff row and related address with a new column, as well as statements for the new table structure and data insert.
staff_id |
first_name |
last_name |
position |
start_date |
location |
address_id |
1 |
Sue |
Tindale |
CFO |
8/3/2001 |
1 |
1 |
2 |
Ian |
Tindale |
CEO |
8/3/2001 |
1 |
2 |
3 |
Marny |
Hermione |
Roaster |
10/24/2007 |
2 |
3 |
4 |
Chelsea |
Claudia |
Roaster |
7/3/2003 |
2 |
4 |
5 |
Alec |
Isadora |
Roaster |
4/2/2008 |
2 |
5 |
6 |
Xena |
Rahim |
Store Manager |
7/24/2016 |
3 |
6 |
7 |
Kelsey |
Cameron |
Coffee Wrangler |
10/18/2003 |
3 |
7 |
8 |
Hamilton |
Emi |
Coffee Wrangler |
2/9/2005 |
3 |
8 |
9 |
Caldwell |
Veda |
Coffee Wrangler |
9/9/2013 |
3 |
9 |
10 |
Ima |
Winifred |
Coffee Wrangler |
12/10/2016 |
3 |
10 |
Table 4. Add foreign key column address_id to Staff table
address_id |
staff_id |
staff_address |
staff_city |
staff_state_province |
staff_postal_code |
staff_telephone |
1 |
1 |
111 Atlantic Avenue |
Brooklyn |
NY |
11201 |
999-888-7777 |
2 |
2 |
111 Atlantic Avenue |
Brooklyn |
NY |
11201 |
777-666-5555 |
3 |
3 |
94-22 117th Street |
Jamaica |
NY |
11419 |
123-456-7890 |
4 |
4 |
171-12 104th Avenue |
Jamaica |
NY |
11433 |
987-654-3210 |
5 |
5 |
8210 Surrey Place |
Jamaica |
NY |
11432 |
234-567-8901 |
6 |
6 |
13 46th Street |
Long Island City |
NY |
11101 |
345-678-9012 |
7 |
7 |
50-6 46th Street |
Woodside |
NY |
11377 |
456-789-0123 |
8 |
8 |
212 Leonard Street |
Brooklyn |
NY |
11211 |
567-890-1234 |
9 |
9 |
33-52 74th Street |
Jackson Heights |
NY |
11372 |
678-901-2345 |
10 |
10 |
33-1 29th Street |
Astoria |
NY |
11106 |
789-012-3456 |
Table 5. New staff_address table
In the graph, we would need to add the data for a new StaffAddress node and its relationship to Staff nodes. Existing data would not be impacted, so we would not need to alter Staff entities in the database.
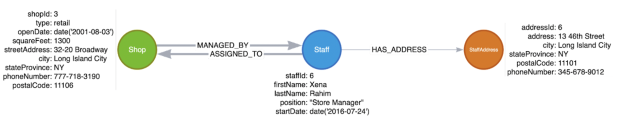
Figure 3: Refactor No. 2 for graph
Refactoring 3: Adding Data To Existing Tables
For our third and final refactoring, business is booming, and we might want to add newly hired staff members to a new shop location.
In the relational structure, creating a new staff member in the table means we would need a shop location assignment to make the row complete. We would likely need some sort of dependency rule (constraint) that ensures we could not insert a value in the Staff table’s location column if it does not exist in the Shop_Location table. If we want to add the new staff member’s address to the staff_address table, we’d need to set up the same guardrails in that table, as well. This means any new staff member assigned to a new location requires us to first create the location, then the staff member, and then their address. Doing these steps in the wrong order would result in errors.
sales_outlet_id |
sales_outlet_type |
store_open_date |
store_square_feet |
store_address |
store_city |
store_state_province |
store_telephone |
store_postal_code |
manager |
1 |
headquarters |
8/1/2016 |
0 |
na |
New York |
NY |
111-222-3333 |
44444 |
2 |
2 |
warehouse |
7/3/2003 |
3400 |
164-14 Jamaica Ave |
Jamaica |
NY |
972-871-0402 |
11432 |
1 |
3 |
retail |
8/3/2001 |
1300 |
32-20 Broadway |
Long Island City |
NY |
777-718-3190 |
11106 |
6 |
4 |
retail |
9/15/2022 |
1400 |
376 Union Avenue |
Brooklyn |
NY |
978-878-0488 |
11211 |
11 |
Table 6. Shop_location table with new row
staff_id |
first_name |
last_name |
position |
start_date |
location |
address_id |
1 |
Sue |
Tindale |
CFO |
8/3/2001 |
1 |
1 |
2 |
Ian |
Tindale |
CEO |
8/3/2001 |
1 |
2 |
3 |
Marny |
Hermione |
Roaster |
10/24/2007 |
2 |
3 |
4 |
Chelsea |
Claudia |
Roaster |
7/3/2003 |
2 |
4 |
5 |
Alec |
Isadora |
Roaster |
4/2/2008 |
2 |
5 |
6 |
Xena |
Rahim |
Store Manager |
7/24/2016 |
3 |
6 |
7 |
Kelsey |
Cameron |
Coffee Wrangler |
10/18/2003 |
3 |
7 |
8 |
Hamilton |
Emi |
Coffee Wrangler |
2/9/2005 |
3 |
8 |
9 |
Caldwell |
Veda |
Coffee Wrangler |
9/9/2013 |
3 |
9 |
10 |
Ima |
Winifred |
Coffee Wrangler |
12/10/2016 |
3 |
10 |
11 |
Jasmine |
Patterson |
Store Manager |
9/12/2022 |
4 |
11 |
12 |
Jose |
Vino |
Coffee Wrangler |
09/13/2022 |
4 |
12 |
Table 7. Staff table with 2 new staff
address_id |
staff_id |
staff_address |
staff_city |
staff_state_province |
staff_postal_code |
staff_telephone |
1 |
1 |
111 Atlantic Avenue |
Brooklyn |
NY |
11201 |
999-888-7777 |
2 |
2 |
111 Atlantic Avenue |
Brooklyn |
NY |
11201 |
777-666-5555 |
3 |
3 |
94-22 117th Street |
Jamaica |
NY |
11419 |
123-456-7890 |
4 |
4 |
171-12 104th Avenue |
Jamaica |
NY |
11433 |
987-654-3210 |
5 |
5 |
8210 Surrey Place |
Jamaica |
NY |
11432 |
234-567-8901 |
6 |
6 |
13 46th Street |
Long Island City |
NY |
11101 |
345-678-9012 |
7 |
7 |
50-6 46th Street |
Woodside |
NY |
11377 |
456-789-0123 |
8 |
8 |
212 Leonard Street |
Brooklyn |
NY |
11211 |
567-890-1234 |
9 |
9 |
33-52 74th Street |
Jackson Heights |
NY |
11372 |
678-901-2345 |
10 |
10 |
33-1 29th Street |
Astoria |
NY |
11106 |
789-012-3456 |
11 |
11 |
107 Irving Avenue |
Brooklyn |
NY |
11237 |
890-123-4567 |
12 |
12 |
43-1 Cambridge Place |
Brooklyn |
NY |
11238 |
901-234-5678 |
Table 8. Staff_address table with 2 new addresses
For our graph version, we simply need to add the new data. The structure remains the same, and existing data is not impacted.
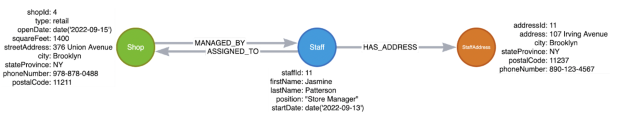
Figure 4: Refactor No. 3 for graph
Graphs Reduce Data Refactoring
We have seen how data refactoring impacts both relational and graph databases. Relational databases require a more intensive process to make changes because of the separation of table structure and actual data. In contrast, graphs remove the extra translation step between real-world data and database structure because they more naturally model data as it exists in the real world.
Time spent in today’s example might have seemed trivial, but what happens when you have thousands, millions, or billions of shops, staff members, and addresses? Business-critical systems discourage teams from making changes due to the labor involved and potential impacts. Graphs keep the data and model we already have and alter only what has changed.
Graph refactoring allows businesses to be adaptable and agile, giving them the power to morph as the industry or data around them changes. Moving to graphs in a current project can reduce time-to-market now, as well as improve future maintainability, risk mitigation, and additional feature development.
Learn more about graph modeling and refactoring through Neo4j GraphAcademy, where you can find self-paced and free online courses!
Published at DZone with permission of Jennifer Reif. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments