Understanding Inference Time Compute
Inference time compute is a crucial factor in the deployment of machine learning models, where performance, efficiency, and user experience are key.
Join the DZone community and get the full member experience.
Join For FreeIn the field of machine learning and artificial intelligence, inference is the phase where a trained model is applied to real world data to generate predictions or decisions. After a model undergoes training, which can be computationally intensive and time consuming, the inference process allows the model to make predictions with the goal of providing actionable results.
Inference Time Compute
Inference time compute refers to the amount of computational power required to make such predictions using a trained model. While training a model involves processing large datasets to learn patterns and relationships, inference is the process where the model is used to make predictions on new, unseen data. This phase is critical in real world applications such as image recognition, natural language processing, autonomous vehicles, and more.
While training time and accuracy are often the focus during the development of ML models, inference time and efficiency are equally important, especially when deploying models into high scale production environments. The performance of a model during inference can impact various real-world aspects like real-time user experience and power consumption. For example, a model responding very slowly may not be usable in autonomous driving use cases.
Adaptive Inference Time Compute
While scaling up model size through increased pre-training has been the dominant approach to improve model performance, adaptive inference time compute allows LLMs to think longer and harder about a given problem at inference time, using various strategies to improve their initial responses. LLMs can be more efficient by adaptively allocating compute based on the perceived difficulty of the task.
Adaptive inference time compute is a paradigm shift in how we think about LLM performance, moving away from fixed compute quota to a more dynamic and efficient approach. Instead of generating a predetermined number of responses or searching with a fixed compute quota, adaptive techniques allow the model to adjust its compute expenditure on the fly, based on the difficulty of the task and its own perceived ability to improve. For example, an LLM might decide to generate more samples for a challenging math problem where it's struggling to find a solution, while quickly returning a single, confident response for a simple factual query. This adaptability can lead to significant gains in both performance and efficiency, allowing LLMs to solve problems more effectively while minimizing wasted computation.
Inference Metrics
There are several traditional metrics for evaluating the performance of LLM namely TTFT, TBT, TPOT, and normalized latency. While these metrics are useful in some ways, they fail to provide a complete picture of real time experiences and can sometimes be misleading.
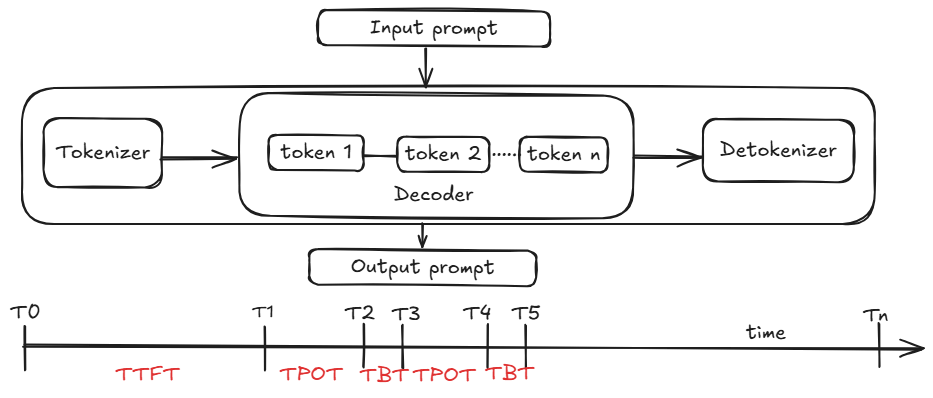
Time to First Token (TTFT)
This metric measures the latency between the time a request arrives and the generation of the first output token. It includes scheduling delay, which depends on factors like system load, and prompt processing time, which is influenced by prompt length. A key limitation of TTFT is that it doesn't account for the varying lengths of prompts. Normalizing TTFT by prompt length is also not ideal, as it normalizes scheduling delay as well, disproportionately penalizing shorter input requests.
Time Between Tokens (TBT)
This metric represents the latency for each subsequent token generation in the decode phase, directly impacting the perceived speed of response generation. Optimizing TBT is important for a fluid user experience, especially in real time applications like chat. However, TBT fails to reveal the magnitude and timing of stalls during token generation. A high tail TBT could indicate a stall at the beginning of the generation process, which significantly disrupts the user experience, but this information is not captured by the TBT alone. Additionally, TBT doesn't account for non uniform token generation strategies like speculative decoding, where multiple tokens can be generated in a single iteration.
Time Per Output Token (TPOT)
This metric is similar to TBT and represents the average time it takes to generate an output token in the decode phase. It's calculated by normalizing the total decode time by the number of decode tokens generated. The main issue with TPOT is that it hides jitters and stalls in token generation by averaging the latency over all tokens. A long stall can significantly impact user experience, but its impact on TPOT is numerically small due to the normalization by the number of tokens.
Normalized Latency
This metric calculates the total execution time of a request, including scheduling delay, prompt processing, and decode time, and then normalizes it by the number of decode tokens. While providing an overall measure of throughput, normalized latency can obscure important details like scheduling delay. Two systems with vastly different scheduling delays have very similar normalized latency values. Like TPOT, normalized latency can also mask jitters and stalls in token generation.
Fluidity Index
Conventional metrics like TTFT, TBT, and TPOT fail to fully capture the real time user experience in LLM interactions because they don't adequately account for variations in token generation speed. To address this, the fluidity index was introduced as a novel metric designed to reflect the nuances of LLM inference in real-time applications like chat. The fluidity index is inspired by deadline-based evaluation in real-time systems and treats streaming token generation in LLMs like periodic tasks. It works by setting deadlines for each token's generation based on desired TTFT and TBT value. A higher fluidity index indicates a smoother, more consistent token generation process, aligning better with user expectations in real time applications.
Factors Affecting Inference Time
Several factors affect the inference time of a model. These include the complexity of the model, the hardware used for computation, and the nature of the input data. Optimizing inference time is crucial for deploying machine learning models at scale. Several techniques can help reduce the time it takes for a model to make predictions.
- Model complexity: Larger, more complex models generally require more time to make predictions. For example, deep neural networks with millions of parameters may take longer to process data than simpler models like decision trees or linear regressions.
- Hardware: The hardware platform on which the model runs significantly impacts inference time. Traditional CPUs may be slower than specialized hardware like GPUs or TPUs (Tensor Processing Units) that are optimized for parallel processing, particularly for deep learning tasks.
- Batch size: Inference can often be faster when processing multiple inputs at once, a method known as batch inference. However, the optimal batch size depends on the specific model and hardware being used. Too large of a batch may overwhelm the system, while too small a batch could underutilize hardware resources.
- Data preprocessing: The time spent on preprocessing the input data before passing it to the model also contributes to the overall inference time. For example, tasks such as tokenization may add significant overhead.
- Model quantization and pruning: Optimizing the model through techniques like quantization, i.e., reducing the precision of model weights, and pruning, i.e., removing unnecessary parts of the model, can help reduce both the memory footprint and the inference time. These techniques are particularly useful for deploying models on resource constrained devices.
- Software optimizations: Specialized libraries and frameworks such as TensorRT, ONNX Runtime, or LiteRT can significantly speed up the inference process by optimizing the underlying computation graph. Additionally, optimizations like reduced precision arithmetic, e.g., 16-bit floating point instead of 32-bit, can be employed to speed up computations without sacrificing much accuracy.
- Model parallelism: For extremely large models, splitting the workload across multiple devices can help decrease inference time, allowing for faster processing.
- Edge computing: For applications involving mobile devices or IoT, deploying models directly on the edge, i.e., local devices, rather than relying on cloud services, can reduce the round trip communication time, allowing for faster inference. Edge computing allows for real-time decision-making without needing to send data to remote servers.
Conclusion
Inference time compute is a crucial factor in the deployment of machine learning models, especially in real world applications where performance, efficiency, and user experience are key. Reducing inference time can lead to faster, more cost effective, and scalable AI systems. As AI technologies continue to evolve, techniques like hardware acceleration, model optimization, and efficient software frameworks will play an increasingly important role in ensuring that inference is as quick and resource efficient as possible. Optimizing inference time allows for better user experiences, lower operational costs, and the ability to scale AI systems effectively.
References
- Metron: Holistic Performance Evaluation Framework for LLM Inference Systems
- Adaptive Inference-Time Compute: LLMs Can Predict if They Can Do Better, Even Mid-Generation
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
- NVIDIA NIM LLMs Benchmarking
- NVIDIA NIM LLMs Benchmarking
Opinions expressed by DZone contributors are their own.
Comments