Using API Gateways to Facilitate Your Transition From Monolith to Microservices
Learn about the different options for an edge/API gateway solution to help you migrate from a monolith to a cloud-native platform.
Join the DZone community and get the full member experience.
Join For FreeIn my consulting work, I bump into a lot of engineering teams that are migrating from a monolithic application to a microservices-based application. “So what?” you may say, “and the sky is blue,” and yes, while I understand that this migration pattern is almost becoming a cliche, there are often aspects of a migration get forgotten. I’m keen to talk about one of these topics today — the role of an edge gateway, or API gateway.
Migrating to Microservices
Typically at the start of a migration the obvious topics are given plenty of attention: domain modelling via defining Domain-Driven Design inspired “bounded contexts,” the creation of continuous delivery pipelines, automated infrastructure provisioning, enhanced monitoring and logging, and sprinkling in some shiny new technology (Docker, Kubernetes, and perhaps currently a service mesh or two?). However, the less obvious aspects can cause a lot of pain if they are ignored. A case in point is how to orchestrate the evolution of the system and the migration of the existing user traffic. Although you want to refactor the existing application architecture and potentially bring in some new technology, you do not want to disrupt your end users.
As I wrote in a previous article “Continuous Delivery: How Can an API Gateway Help (or Hinder),” patterns like the “dancing skeleton” can greatly help in proving the end-to-end viability of new applications and infrastructure. However, the vast majority of underlying customer interaction is funneled via a single point within your system — the ingress or edge gateway — and therefore to enable experimentation and evolution of the existing systems, you will need to focus considerable time and effort here.
Every (User) Journey Begins at the Edge
I’m obviously not the first person to talk about the need for an effective edge solution when moving towards a microservices-based application. In fact, in Phil Calcado’s proposed extension of Martin Fowler’s original Microservices Prerequisites article — Calcado’s Microservices Prerequisites — his fifth prerequisite is “easy access to the edge.” Phil talks based on his experience that many organisation’s first foray into deploying a new microservice alongside their monolith consists of simply exposing the service directly to the internet. This can work well for a single (simple) service, but the approach tends not to scale, and can also force the calling clients to jump through hoops in regards to authorization or aggregation of data.

It is possible to use the existing monolithic application as a gateway, and if you have complex and highly-coupled authorization and authentication code, then this can be the only viable solution until the security components are refactored out into a new module or service. This approach has obvious downsides, including the requirement that you must “update” the monolith with any new routing information (which can involve a full redeploy), and the fact that all traffic must pass through the monolith. This latter issue can be particularly costly if you are deploying your microservices to a separate new fabric or platform (such as Kubernetes), as now any request that comes into your application has to be routed through the old stack before it even touches the new stack.

You may already be using an edge gateway or reverse proxy — for example, NGINX or HAProxy — as these can provide many advantages when working with any type of backend architecture. Features provided typically include transparent routing to multiple backend components, header rewriting, TLS termination etc, and crosscutting concerns regardless of how the requests are ultimately being served. The question to ask in this scenario is whether you want to keep using this gateway for your microservices implementation, and if you do, should it be used in the same way?
From VMs to Containers (via Orchestration)
As I mentioned in the introduction to this article, many engineering teams also make the decision to migrate to new infrastructure at the same time as changing the application architecture. The benefits and challenges of doing this are heavily context-dependent, but I see many teams migrating away from VMs and pure Infrastructure as a Service (IaaS) to containers and Kubernetes.
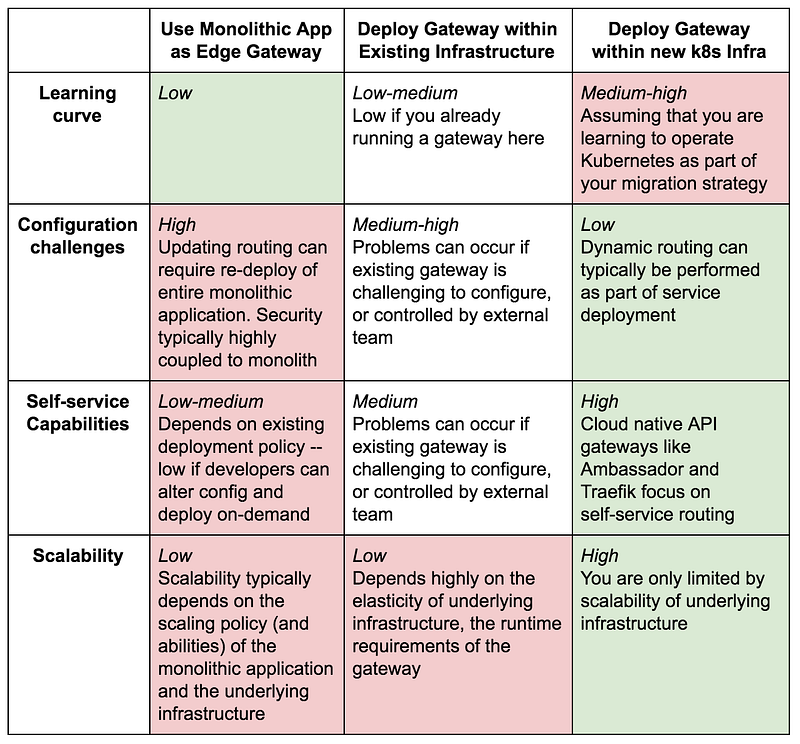
Assuming that you are deciding to package your shiny new microservices within containers and deploy these into Kubernetes, what challenges do you face in regards to handling traffic at the edge? In essence, there are three choices, one of which you have already read about:
- Use the existing monolithic application to act as an edge gateway that routes traffic to either the monolith or new services. Any kind of routing logic can be implemented here (because all requests are traveling via the monolith) and calls to authn/authz can be made in the process.
- Deploy and operate an edge gateway in your existing infrastructure that routes traffic based on URIs and headers to either the monolith or new services. Authn and authz are typically done via calling out to the monolith or a refactored security service.
- Deploy and operate an edge gateway in your new Kubernetes infrastructure that routes traffic based on URIs and headers to either the monolith or new services. Authn and authz are typically done via calling out to a refactored security service running in Kubernetes.
The choice of where to deploy and operate your edge gateway involves tradeoffs:
Once you have made your choice on how to implement the edge gateway, the next decision you will have make is how to evolve your system. Broadly speaking, you can either try and “strangle” the monolith as-is, or you put the “monolith-in-a-box” and start chipping away here.
Strangling the Monolith
Martin Fowler has written a great article about the principles of the Strangler Application Pattern, and even though the writing is over ten years old, the same guidelines apply when attempting to migrate functionality out from a monolith into smaller services. The pattern at its core describes that functionality should be extracted from the monolith in the form of services that interact with the monolith via RPC or REST-like “seams” or via messaging and events. Over time, functionality (and associated code) within the monolith is retired, which leads to the new microservices “strangling” the existing codebase. The main downside with this pattern is that you will still have to maintain your existing infrastructure alongside any new platform you are deploying your microservices to, for as long as the monolith is still in service.

One of the first companies to talk in-depth about using this pattern with microservices was Groupon, back in 2013, with “I-Tier: Dismantling the Monolith.” There are many lessons to be learned from their work, but we definitely don’t need to write a custom NGINX module in 2018, as Groupon originally did with “Grout.” Now modern open source API gateways like Ambassador and Traefik exist, which provide this functionality using simple declarative configuration.
Monolith-in-a-Box: Simplifying Continuous Delivery
An increasingly common pattern I am seeing with teams migrating to microservices and deploying onto Kubernetes is what I refer to as a “monolith-in-a-box.” I talked about this alongside Nic Jackson when we shared the story of migrating notonthehighstreet.com’s monolithic Ruby on Rails application — affectionately referred to as the MonoNOTH — towards a microservice-based architecture back in 2015 at the ContainerSched conference.
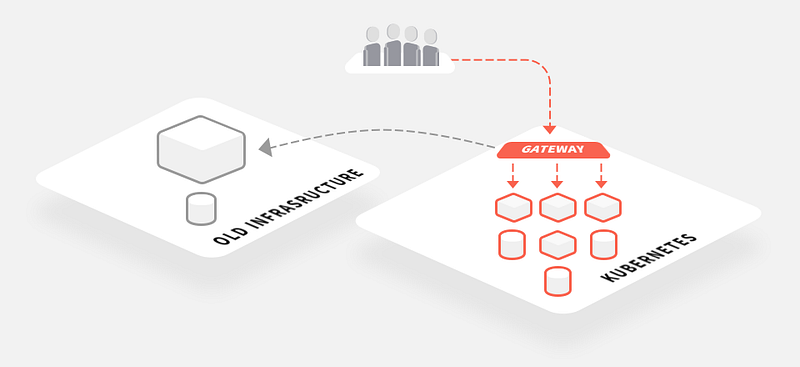
In a nutshell, this migration pattern consists of packaging your existing monolithic application within a container and running it like any other new service. If you are implementing a new deployment platform, such as Kubernetes, then you will run the monolith here too. The primary benefits of this pattern is the homogenisation of your continuous delivery pipeline — each application and service may require customised build steps (or a build container) in order to compile and package the code correctly, but after the runtime container has been created, then all of the other steps in the pipeline can use the container abstraction as the deployment artifact.
The ultimate goal of the monolith-in-a-box pattern is to deploy your monolith to your new infrastructure and gradually move all of your traffic over to this new platform. This allows you to decommission your old infrastructure before completing the full decomposition of the monolith. If you are following this pattern then I would argue that running your edge gateway within Kubernetes makes even more sense, as this is ultimately where all of the traffic will be routed.

Parting Thoughts
When moving from Virtual Machine (VM)-based infrastructure to a cloud-native platform like Kubernetes it is well worth investing time in implementing an effective edge/ingress solution to help with the migration. You have multiple options to implement this: using the existing monolithic application as a gateway; deploying or using an edge gateway in your existing infrastructure to route traffic between the current and new services, or deploying an edge gateway within your new Kubernetes platform.
Deploying an edge gateway within Kubernetes can provide more flexibility when implementing migration patterns like the “monolith-in-a-box,” and can make the transition towards a fully microservice-based application much more rapid.
Published at DZone with permission of Daniel Bryant. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments