Vector Databases Are Reinventing How Unstructured Data Is Analyzed
In an environment where businesses struggle to process unstructured data, vector databases are an exciting concept to maximize value from the data you collect.
Join the DZone community and get the full member experience.
Join For FreeUnstructured data is a complex challenge but a huge opportunity in any organization’s pursuit of data excellence. Unfortunately, it remains untouched due to the complexity of sorting, managing, and organizing the load. Interestingly, the OpenAI initiative, ChatGPT, has emerged as a winner in manipulating unstructured data into a structured format. However, ChatGPT isn’t the only one making inroads to streamlining the analysis of unstructured data: Enter vector databases.
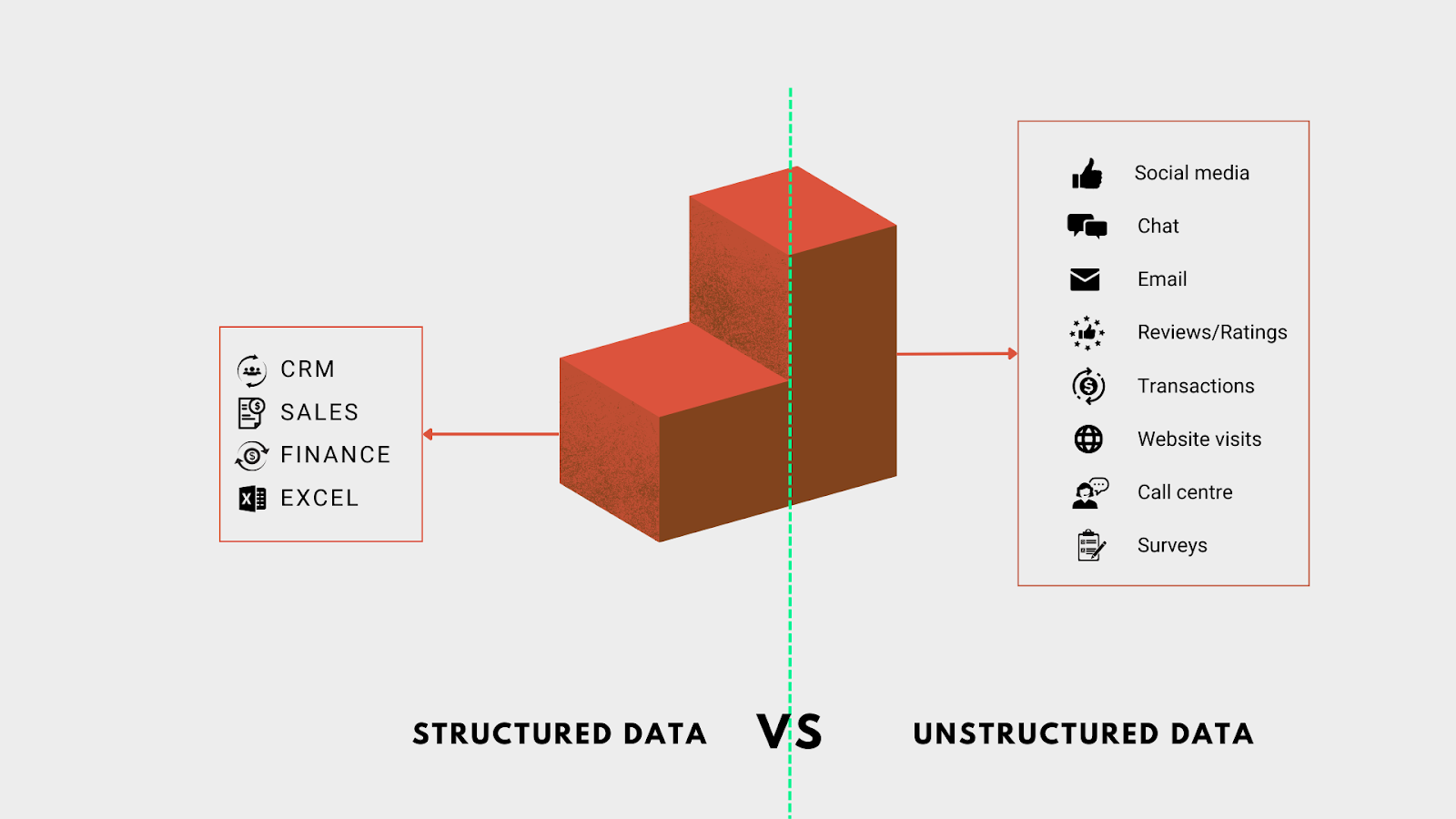
Difference between structured and unstructured data.
Vector databases have introduced a new approach to database management that enables you to put your untouched and unstructured data to good use. They have a brilliant capability to sort through and search unstructured data.
Before we go deep into vector databases, let’s understand the current scene of data analysis pertaining to unstructured data.
System Architecture for Unstructured Data Analysis
List of Vital Components
Collection
Data is generated from various places, including social media, IoT devices, emails, and other devices or platforms. However, ensuring that all the data you collect is reliable and relevant is critical. Also, you can use data lakes to collate from multiple places into a single storage unit.
Storage
As unstructured data cannot be stored in tables of columns and rows, it is impossible to draw statistics from the data. Therefore, it needs a unique data storage model known as the File system.
Metadata
Metadata is a set of characters that each data piece is associated with to help you access and manage the data. It is similar to the title and category tag you add to your blogs. Using ML methodologies like NLP (natural language processing), you analyze unstructured data for you to understand
Visualization
Once the data is decoded through analysis, it can be represented in graphs, charts, or other visuals in a stage that is known as data visualization. It facilitates an easy understanding of the data as it reveals hidden details.
File Systems to Store Unstructured Data
Storing electronic data in computers can be done in multiple ways, and one feasible method is Filesystems. It arranges data as files, which are then saved in a directory structure.
Since filesystems allow storing different file types, it is an ideal way to manage unstructured data. It also allows you to leverage this data across environments and applications by drawing insights effectively.
Types of File Systems
Distributed
A distributed file system (DFS) allows you to store data across multiple file servers or locations while letting you access the same from anywhere.
Object Storage
Object storage is a file system where data blocks are stored as a single block while keeping the data together with metadata.
Scale-Out NAS
Scale-out network-attached storage (NAS) is a system where the storage space - a disk - can be expanded by adding additional devices forming a clustered storage array.
Cloud-Native
Cloud-native file system (CNFS) is a copy-on-write file system that enables data movement between cloud storage units based on your requirements.
Network-Attached Storage
Network Attached Storage (NAS) is a network-based storage device that allows you to access your data in the form of files through a central network.
Databases
A database is a data collection that can be easily stored, accessed, and updated as and when required. The data can be files, images, videos, or other records. Organizations store all of their data in a single place so that it can be processed and analyzed to facilitate important business processes. Typically, databases use SQL (structured query language) to write and query data.
Types of Databases
Document
Databases that store data in JSON-like formats are called document databases. These nonrelational databases help developers to manage data using a single format in their application code.
Graph
A graph database is one where you store data in the form of nodes and relationships in a graph structure instead of tables or documents.
Column Family
Column Family databases store data in sections of columns within rows, with columns associated with a row key.
Key Value
Also known as key-value stores, Key Value databases store data in key-value format. It means that data is represented as a unique identifier or key that is formed by linking two data items.
Object-Oriented
Object-oriented databases (OOD) apply principles of object-oriented programming to store data in the form of objects.
A New Option for Databases: Vector Databases
Definition of Vector Databases
In simple terms, a vector database is a data storage system where you convert complex data into vectors to organize it efficiently and facilitate frictionless searching. To fully grasp the concept, we should familiarize ourselves with ‘vector embeddings.’
Vector embedding is a practice of representing complicated data objects as numeric values so that you can apply ML (machine learning) algorithms for data management. Applying vector embedding allows you to translate a block of text, numbers, images, audio, or even video into a vector for easier operations. Vector databases are explicitly designed to manage vector embeddings as they index vectors, making it easy to search and extract requested or similar data. It possesses CRUD operations, horizontal scaling, metadata filtering, and similarity search capabilities.
CRUD Operations
Vector databases enable CRUD functions, i.e., create, read, update, and delete the vector embeddings, as they are organized in such a way that you can easily compare vectors to one another or search queries.
Similarity Search
Also known as Vector Search, it is a capability that enables you to look up data even without the knowledge of keywords or metadata assigned to objects. Instead, it will return objects that are similar to your search query.
Metadata Filtering
Along with similarity search, a vector database also allows you to apply various filters to generate a desired result.
How Are Vector Databases Different?
Structured data is usually linked to each other; therefore, it becomes easy to manage the same with traditional databases. These databases, known as relational databases, store data in a tabular format, making it easy to search and process. However, the same can’t be said about unstructured data because of its complexity. This is where vector databases add significant value by bringing the ability to search and mine the unstructured data translated into vector embeddings.
While traditional databases return exact matches when you input a search query, the results from vector databases are mostly near-matches. This unique capability of vector databases has found immense applications in the business world.
Qdrant
Qdrant is a self-hosted or managed similarity search engine and vector database available with an API providing services like storing, searching, and managing vectors. Having been built on Rust, Qdrant is fast in implementing dynamic query planning and payload data indexing. It also offers extended filtering support.
Vertex
Vertex AI Machine Engine is Google’s high-scale, low-latency vector database, which offers a fully managed similarity search. It efficiently indexes vector embeddings based on their unique aspects to facilitate easy and scalable search.
NucliaDB
NucliaDB is an open-source vector database and distributed search engine that allows you to store your data on its cloud infrastructure. The cloud-native database is written in Rust and offers a high read performance to offer scalability at speed.
While all the names mentioned above offer similarity searches, Qdrant goes further. It has a custom implementation option for its HSNW (Hierarchical Navigable Small World Graph) algorithm. This lets you provide better search results by adding extra filters to queries.
Choosing the Right Option for Your Organization
Vector databases are a significant paradigm shift both technically and organizationally. Given the scale and reliance on computation, AI, and machine learning, managing vector databases could become a continuous process.
Further, creating vector indexes requires specialized expertise to normalize the usage of vector databases easily. However, the type of database you need depends on your business needs. For example, if your data is structured and stored in rows and columns using SQL, you can go for a traditional database setup like relational.
Below we quickly go through one use case each for relational and vector databases.
Use Case With Relational Database
Your OTT services, including Netflix, Prime Video, and Hulu, maintain databases to store the content available on their respective platforms. For example, they return the exact title whenever you search for a movie or TV show. Another use case for this is fantasy leagues in the sporting industries. Companies sift through petabytes of data like player performance, statistics, and game outcomes.
Use Case With Vector Database
If we take the same example of the streaming services, you must’ve seen these platforms recommend movies or TV series based on your viewing history. Vector databases power this recommendation engine. You can use them to suggest objects similar to past images, videos, and purchases.
Conclusion
Unstructured data holds deeper insights that give you a better view of the opportunities and weaknesses your business possesses. This is because it is the data that you don’t capture in explicitly defined fields. On the flip side, the inconsistency in the format of the data collected makes it tricky for organizations to unravel. In an environment where businesses are struggling to process unstructured data, vector databases are an exciting concept to maximize value from the data you are collecting. In addition, open-source vector search databases will power the next generation of AI applications through capabilities like similarity search, providing a production-ready service with a convenient API.
Opinions expressed by DZone contributors are their own.
Comments