Why Apache Kafka and Apache Flink Work Well Together to Boost Real-Time Data Analytics
Use Flink and Kafka to create reliable, scalable, low-latency real-time data processing pipelines with fault tolerance and exactly-once processing guarantees.
Join the DZone community and get the full member experience.
Join For FreeWhen data is analyzed and processed in real time, it can yield insights and actionable information either instantly or with very little delay from the time the data is collected. The capacity to collect, handle, and retain user-generated data in real time is crucial for many applications in today’s data-driven environment.
There are various ways to emphasize the significance of real-time data analytics like timely decision-making, IoT and sensor data processing, enhanced customer experience, proactive problem resolution, fraud detection and security, etc. Rising to the demands of diverse real-time data processing scenarios, Apache Kafka has established itself as a dependable and scalable event streaming platform.
In short, the process of collecting data in real-time as streams of events from event sources such as databases, sensors, and software applications is known as event streaming. With real-time data processing and analytics in mind, Apache Flink is a potent open-source program. For situations where quick insights and minimal processing latency are critical, it offers a consistent and effective platform for managing continuous streams of data.
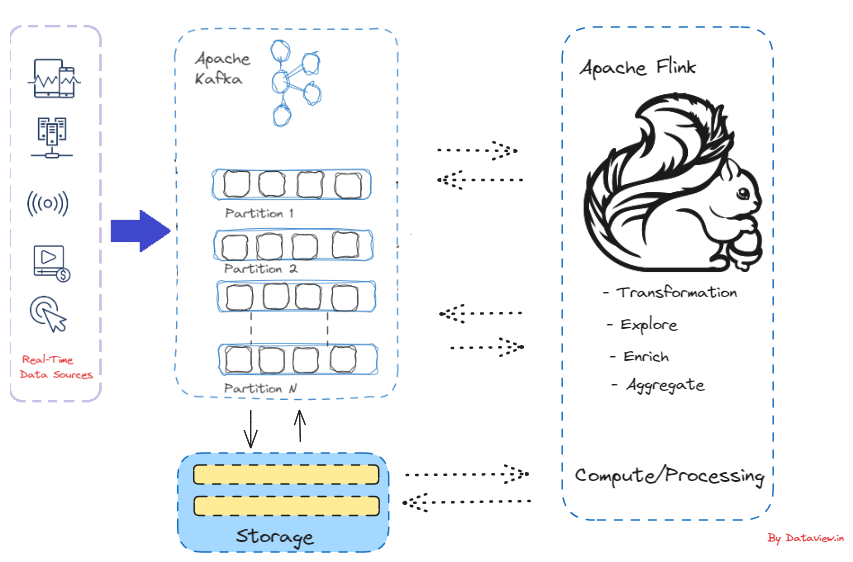
Causes for the Improved Collaboration Between Apache Flink and Kafka
- Apache Flink joined the Apache Incubator in 2014, and since its inception, Apache Kafka has consistently stood out as one of the most frequently utilized connectors for Apache Flink. It is just a data processing engine that can be clubbed with the processing logic but does not provide any storage mechanism. Since Kafka provides the foundational layer for storing streaming data, Flink can serve as a computational layer for Kafka, powering real-time applications and pipelines.
- Apache Flink has produced first-rate support for creating Kafka-based apps throughout the years. By utilizing the numerous services and resources offered by the Kafka ecosystem, Flink applications are able to leverage Kafka as both a source and a sink. Avro, JSON, and Protobuf are just a few widely used formats that Flink natively supports.
- Apache Kafka proved to be an especially suitable match for Apache Flink. Unlike alternative systems such as ActiveMQ, RabbitMQ, etc., Kafka offers the capability to durably store data streams indefinitely, enabling consumers to read streams in parallel and replay them as necessary. This aligns with Flink’s distributed processing model and fulfills a crucial requirement for Flink’s fault tolerance mechanism.
- Kafka can be used by Flink applications as a source as well as a sink by utilizing the many tools and services available in the Kafka ecosystem. Flink offers native support for commonly used formats like Avro, JSON, and Protobuf, similar to Kafka’s support for these formats.
- Other external systems can be linked to Flink’s Table API and SQL programs to read and write batch and streaming tables. Access to data kept in external systems such as a file system, database, message queue, or key-value store is made possible by a table source. For Kafka, it’s nothing but a key-value pair. Events are added to the Flink table in a similar manner as they are appended to the Kafka topic. A topic in a Kafka cluster is mapped to a table in Flink. In Flink, each table is equal to a stream of events that describe the modifications being made to that particular table. The table is automatically updated when a query refers to it, and its results are either materialized or emitted.
Conclusion
In conclusion, we can create reliable, scalable, low-latency real-time data processing pipelines with fault tolerance and exactly-once processing guarantees by combining Apache Flink and Apache Kafka. For businesses wishing to instantly evaluate and gain insights from streaming data, this combination provides a potent option.
Thank you for reading this write-up. If you found this content valuable, please consider liking and sharing.
Published at DZone with permission of Gautam Goswami. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments